
GutenOCR: A Grounded Vision-Language Front-End for Documents
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
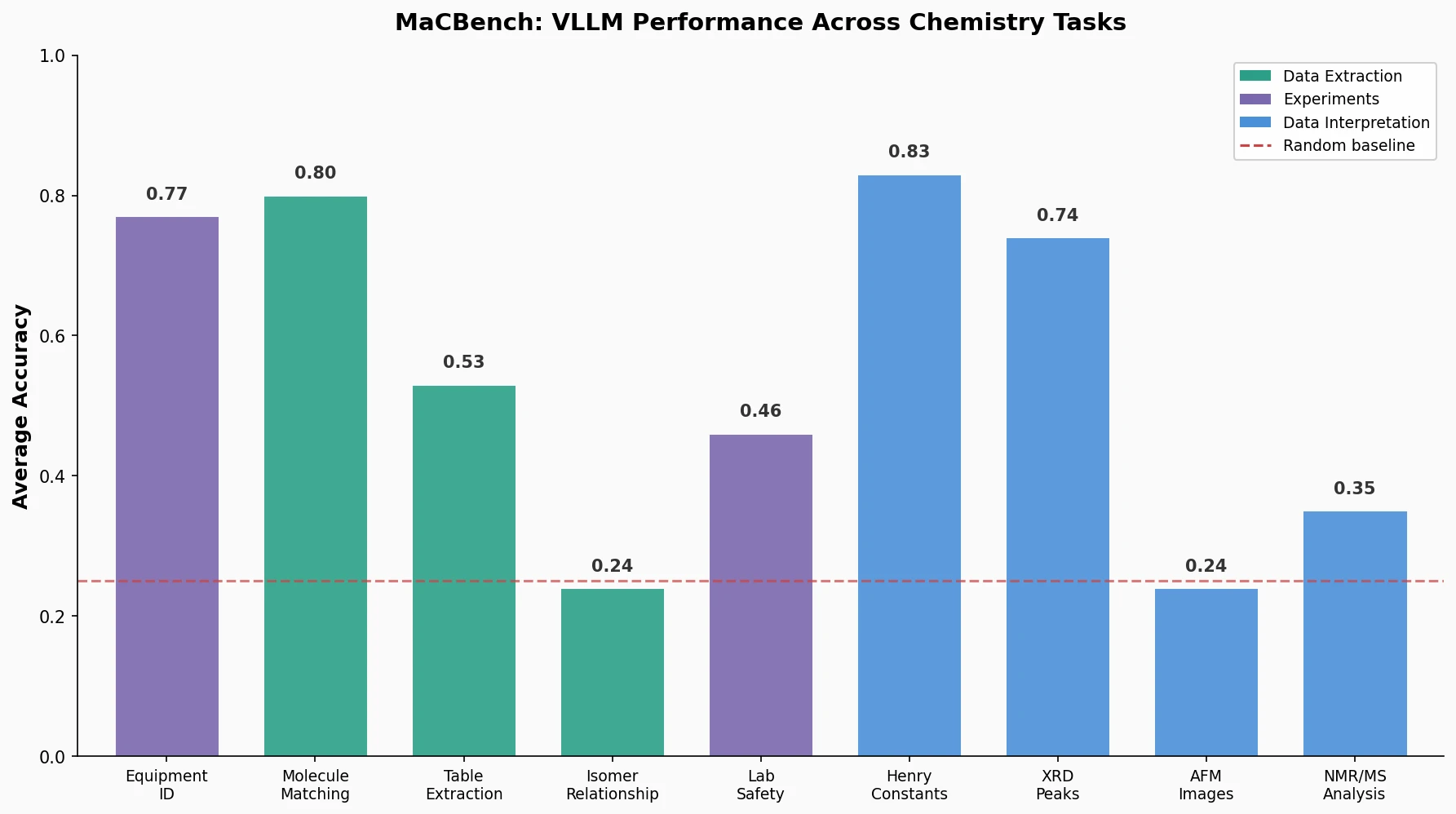
MaCBench evaluates frontier vision language models across 1,153 chemistry and materials science tasks spanning data extraction, experimental execution, and data interpretation, uncovering fundamental limitations in spatial reasoning and cross-modal integration.
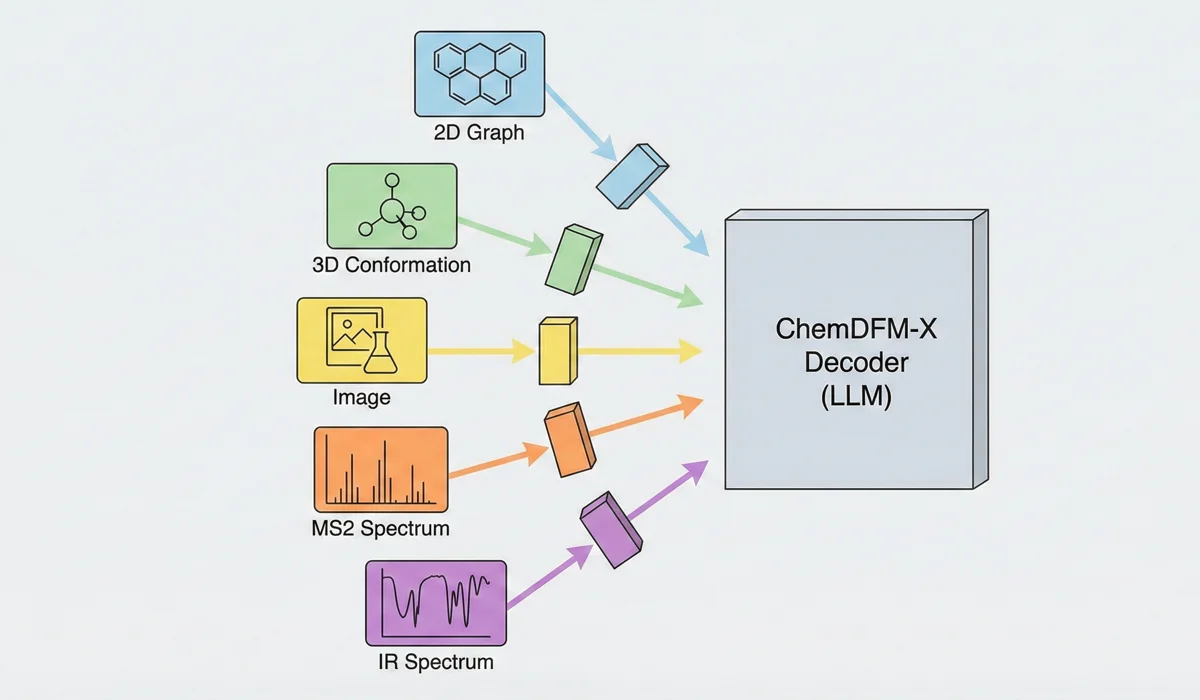
ChemDFM-X is a multimodal chemical foundation model that integrates five non-text modalities (2D graphs, 3D conformations, images, MS2 spectra, IR spectra) into a single LLM decoder. It overcomes data scarcity by generating a 7.6M instruction-tuning dataset through approximate calculations and model predictions, establishing strong baseline performance across multiple modalities.
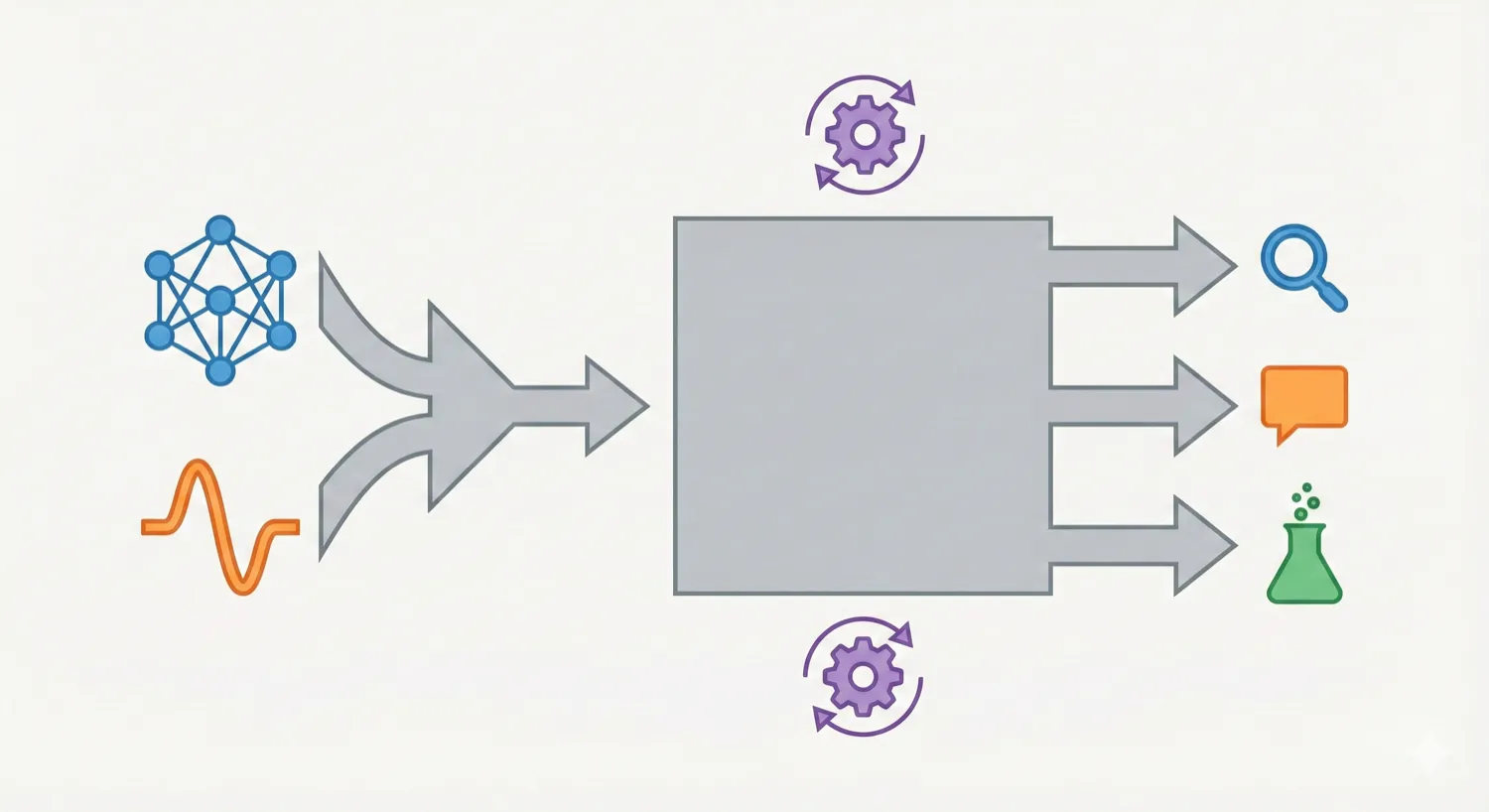
InstructMol integrates a pre-trained molecular graph encoder (MoleculeSTM) with a Vicuna-7B LLM using a linear projector. It employs a two-stage training process (alignment pre-training followed by task-specific instruction tuning with LoRA) to excel at property prediction, description generation, and reaction analysis.
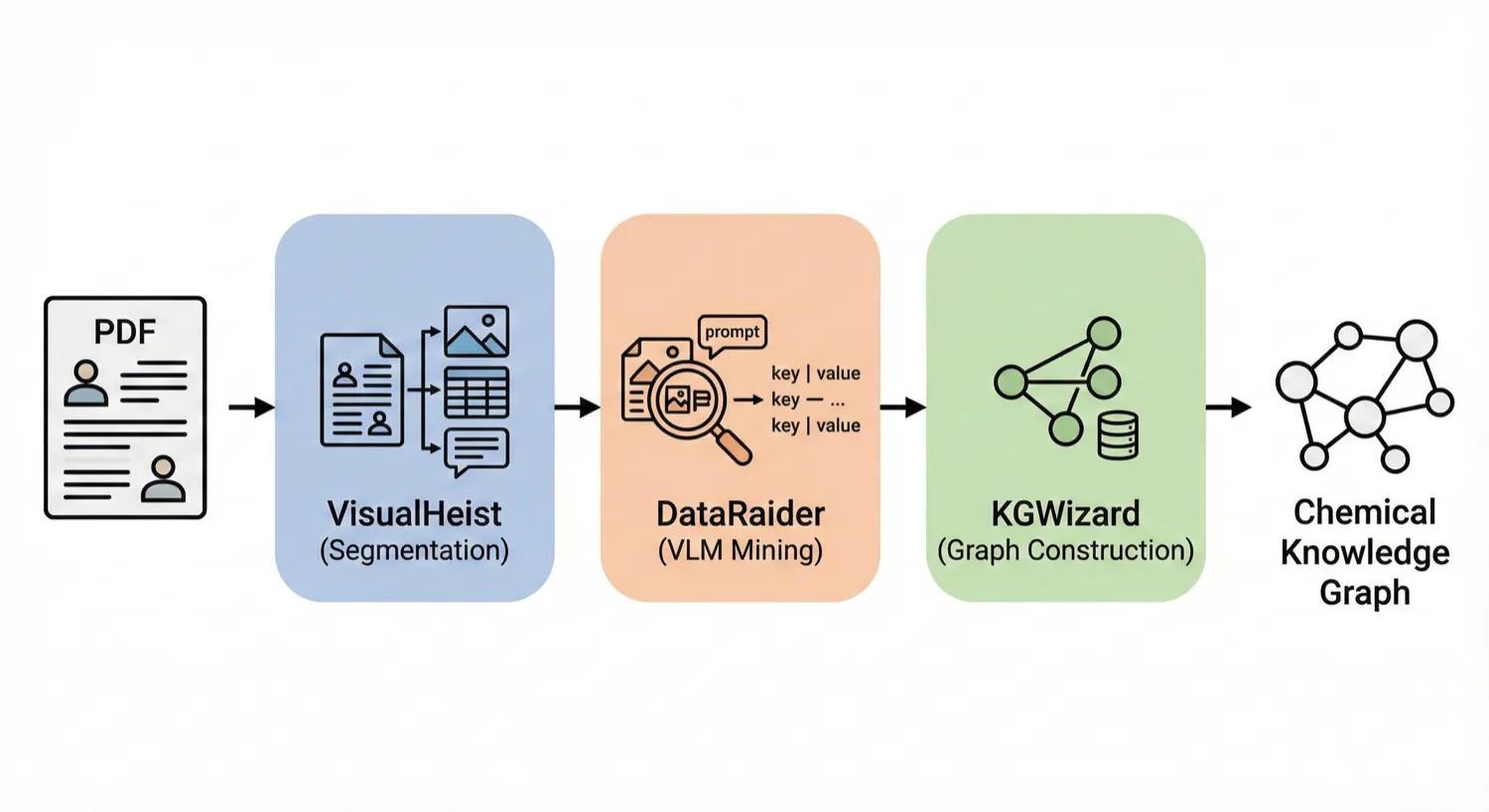
MERMaid leverages fine-tuned vision models and VLM reasoning to mine chemical reaction data directly from PDF figures and tables. By handling context inference and coreference resolution, it builds high-fidelity knowledge graphs with 87% end-to-end accuracy.
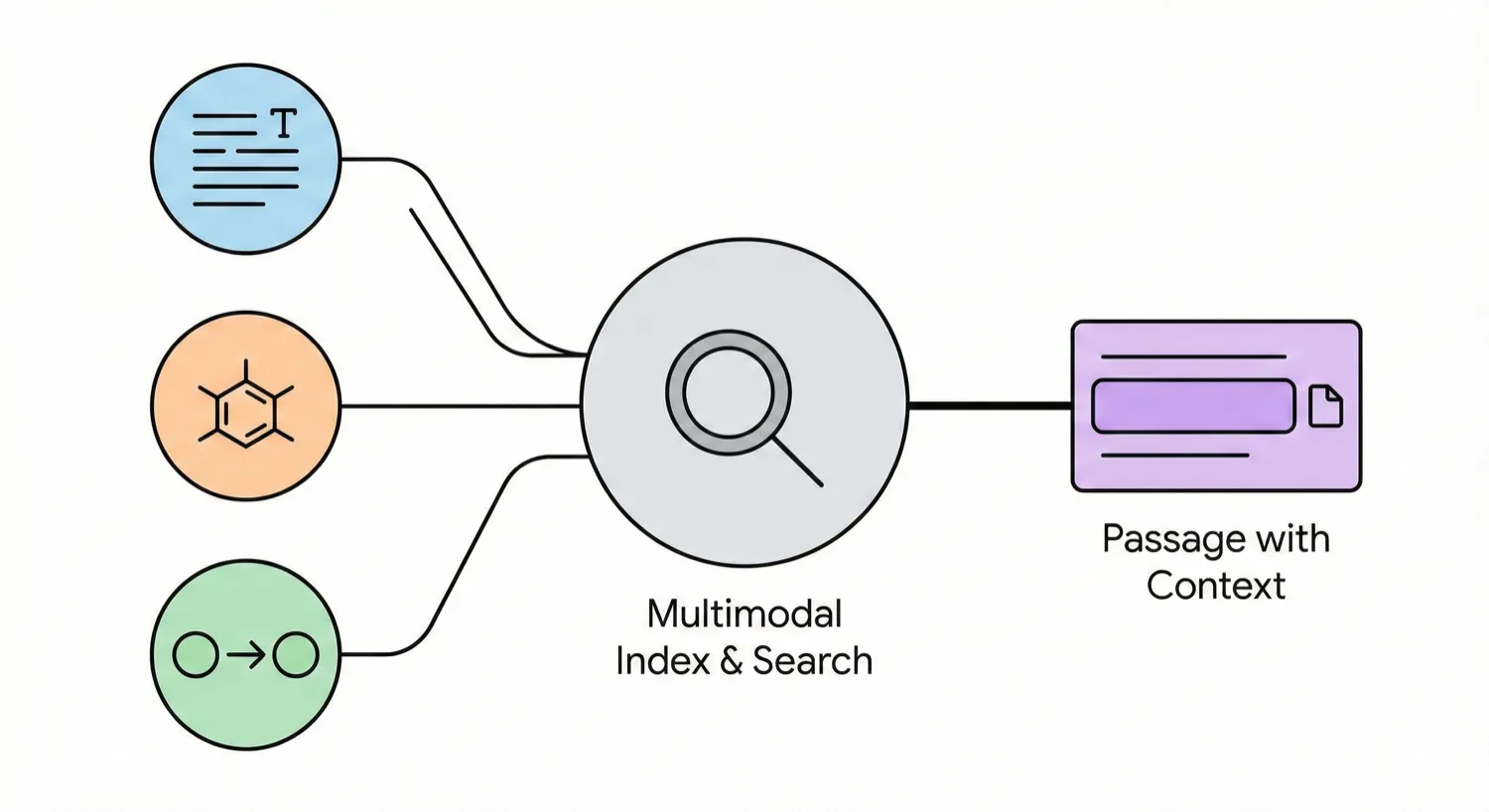
This paper presents a multimodal search system that facilitates passage-level retrieval of chemical reactions and molecular structures by linking diagrams, text, and reaction records extracted from scientific PDFs.
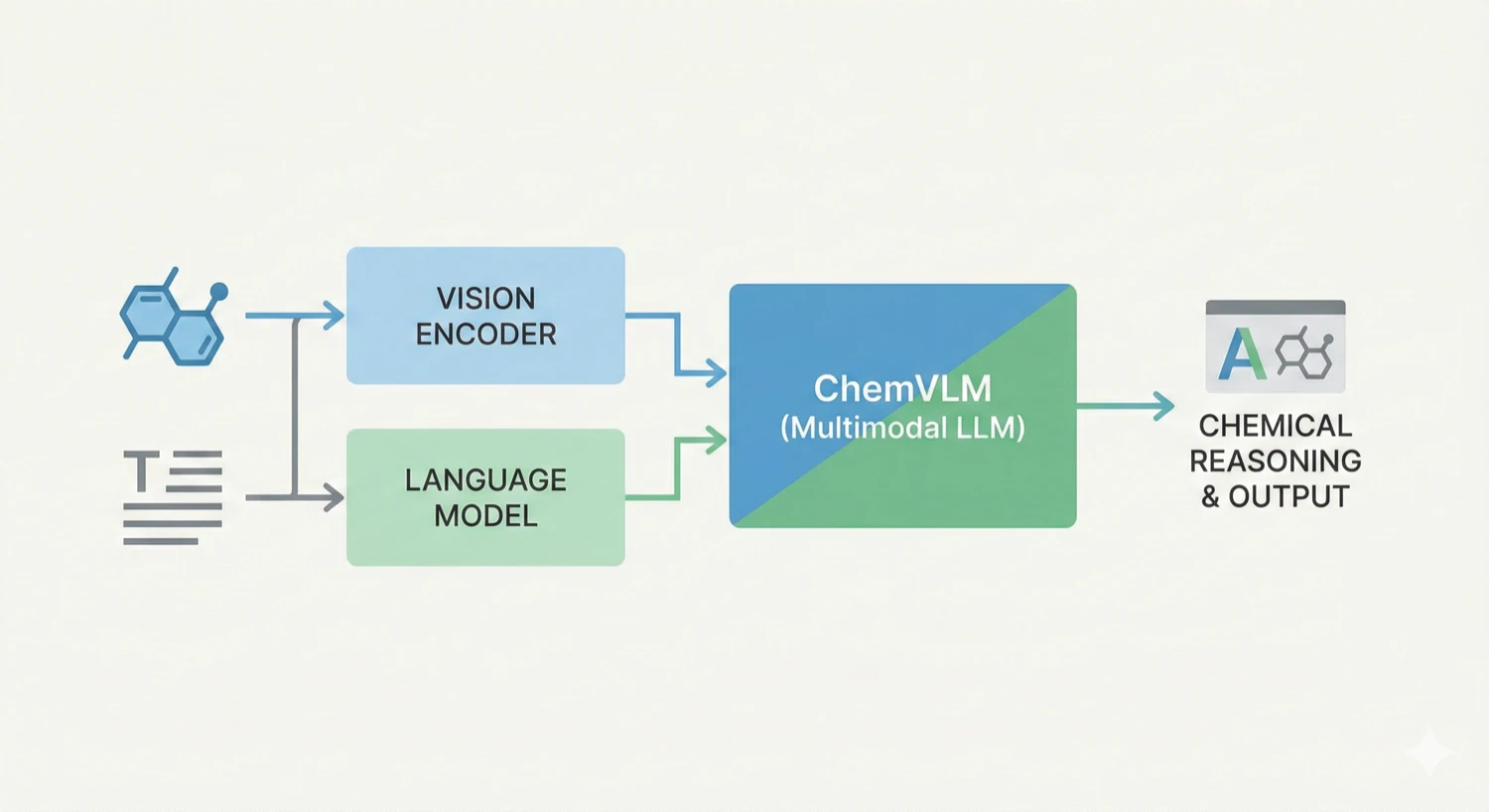
A 2025 AAAI paper introducing ChemVLM, a domain-specific multimodal LLM (26B parameters). It achieves state-of-the-art performance on chemical OCR, reasoning benchmarks, and molecular understanding tasks by combining vision and language models trained on curated chemistry data.