
GutenOCR: A Grounded Vision-Language Front-End for Documents
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
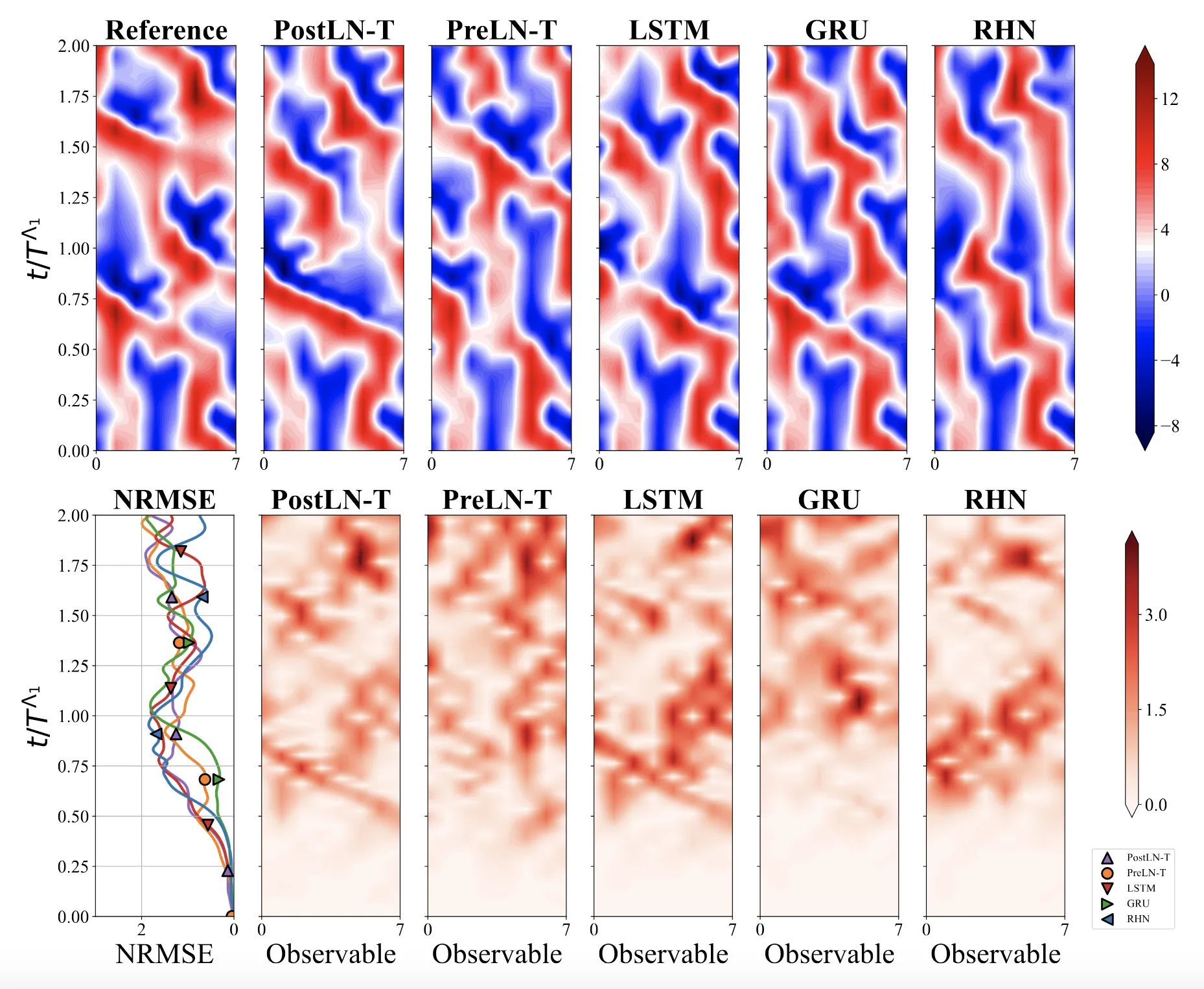
We systematically ablate core mechanisms of Transformers and RNNs, finding that attention-augmented Recurrent Highway Networks outperform standard Transformers on forecasting high-dimensional chaotic systems.
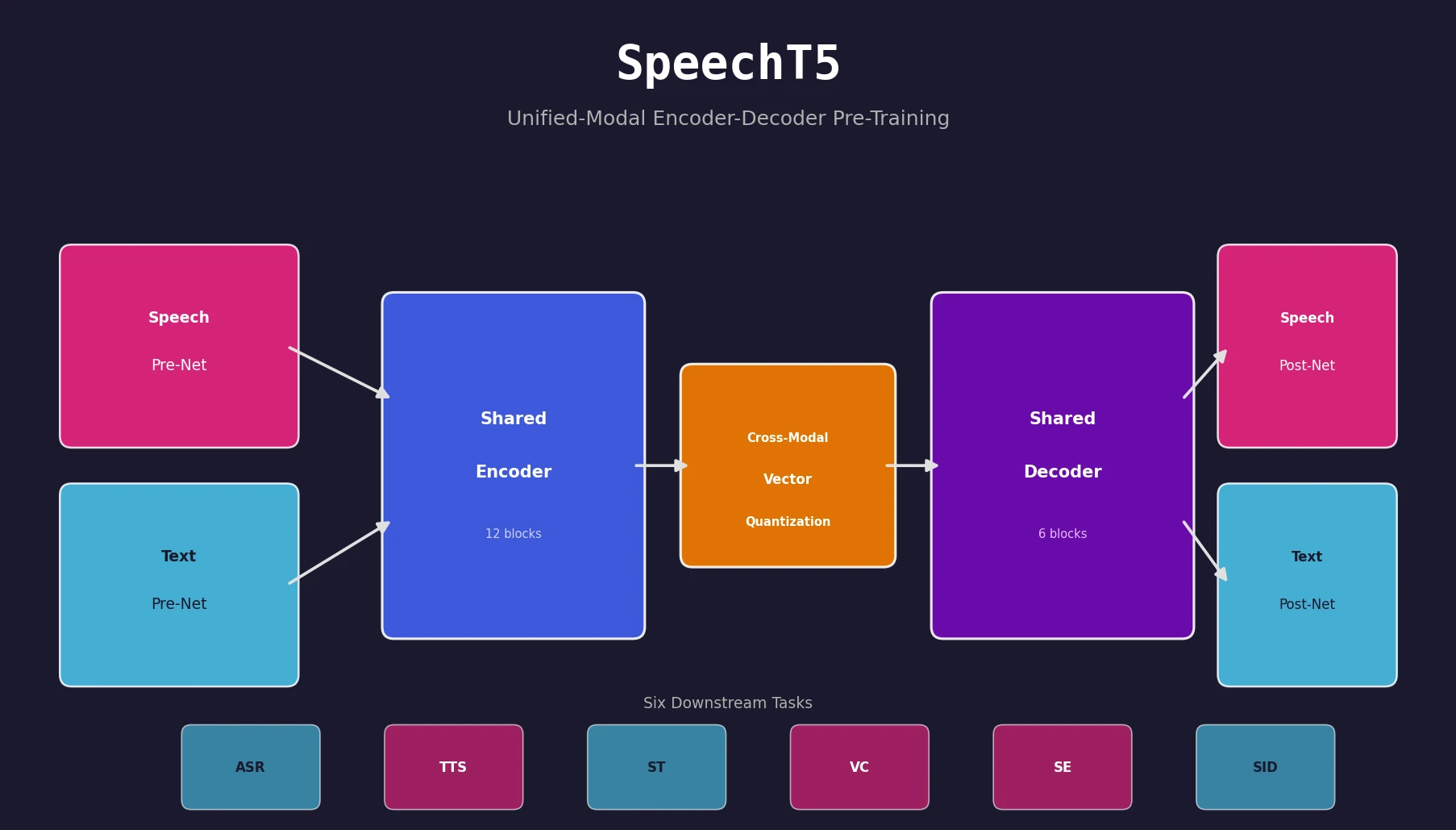
SpeechT5 proposes a unified encoder-decoder pre-training framework that jointly learns from unlabeled speech and text data, achieving strong results on ASR, TTS, speech translation, voice conversion, speech enhancement, and speaker identification.
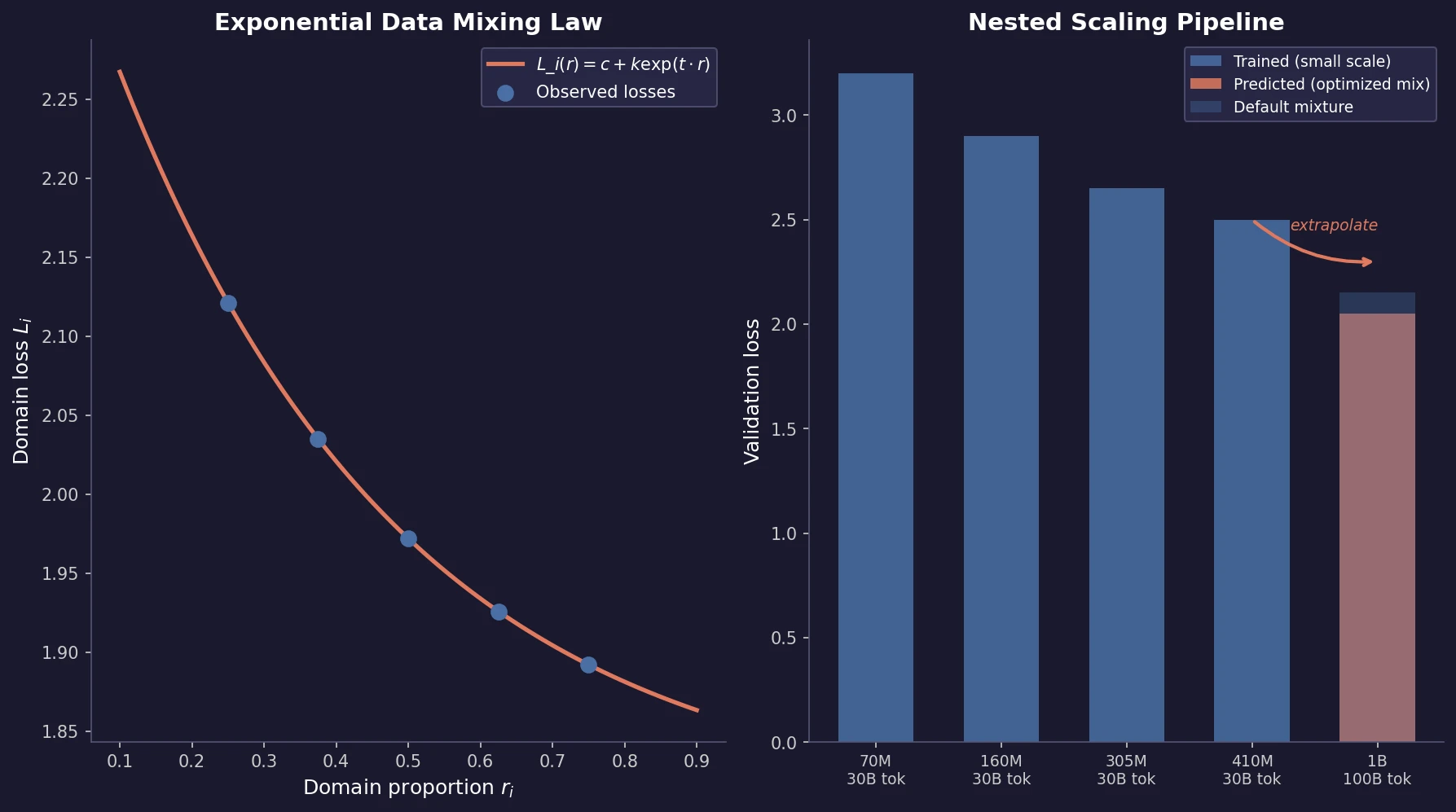
Ye et al. find that language model loss on each domain follows an exponential function of training mixture proportions. By nesting data mixing laws with scaling laws for steps and model size, small-scale experiments can predict and optimize mixtures for large models, achieving 48% training efficiency gains.
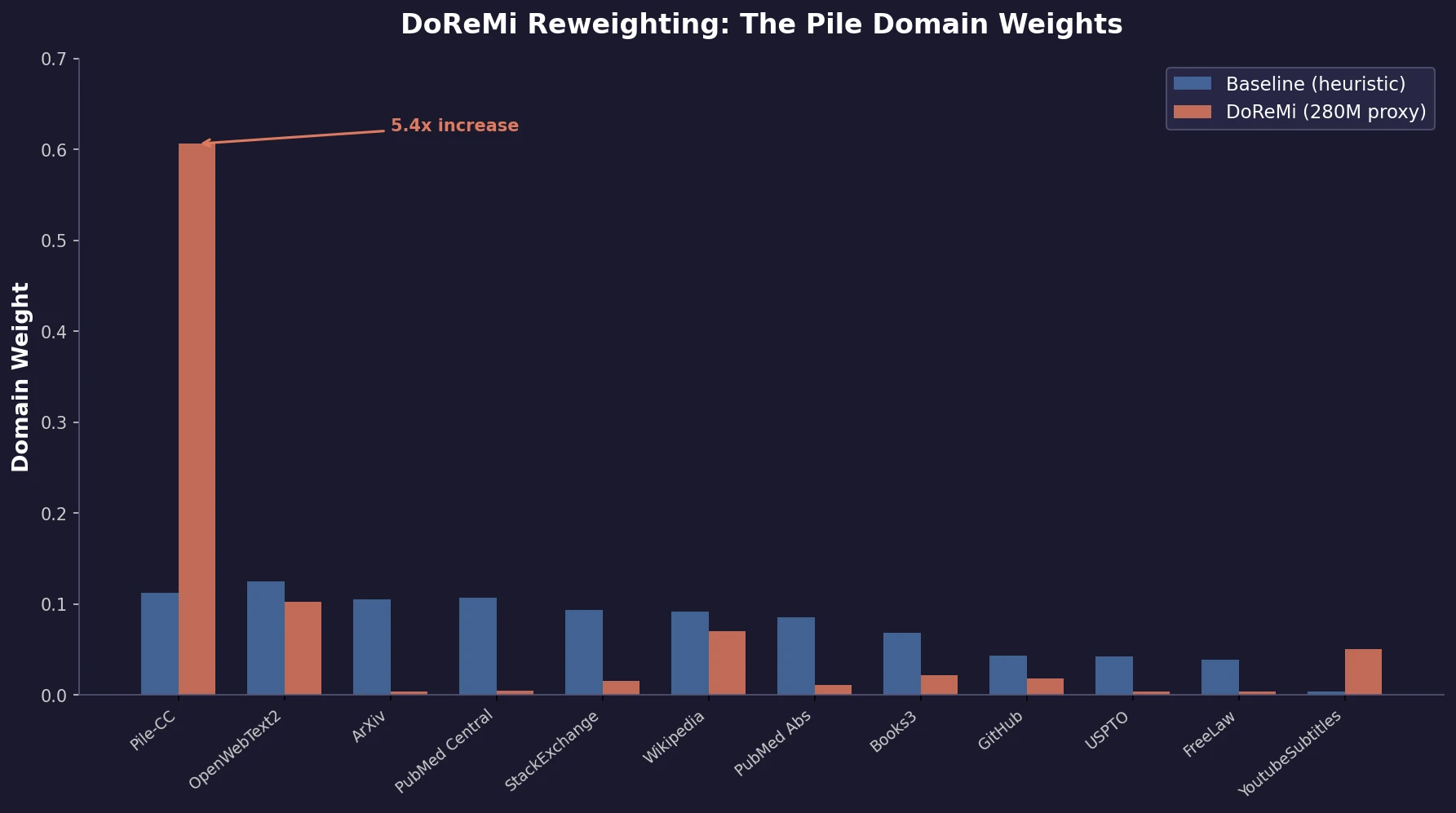
Xie et al. propose DoReMi, which trains a 280M proxy model using Group DRO to find optimal domain mixture weights, then uses those weights to train an 8B model 2.6x faster with 6.5% better downstream accuracy.
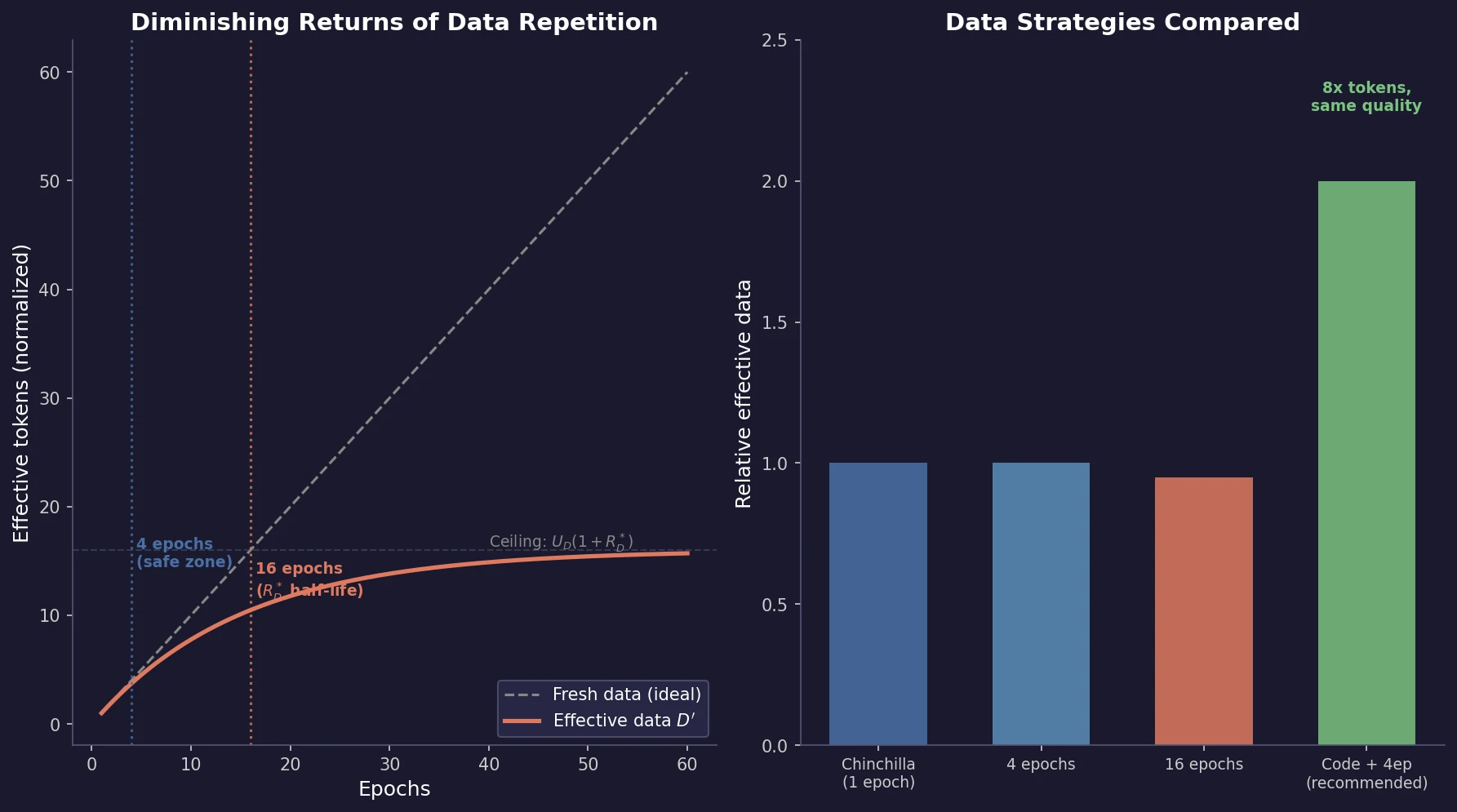
Muennighoff et al. train 400+ models to study how data repetition affects scaling. They propose a data-constrained scaling law with exponential decay for repeated tokens, finding that up to 4 epochs have negligible impact on loss, returns diminish around 16 epochs, and code augmentation provides a 2x effective data boost.
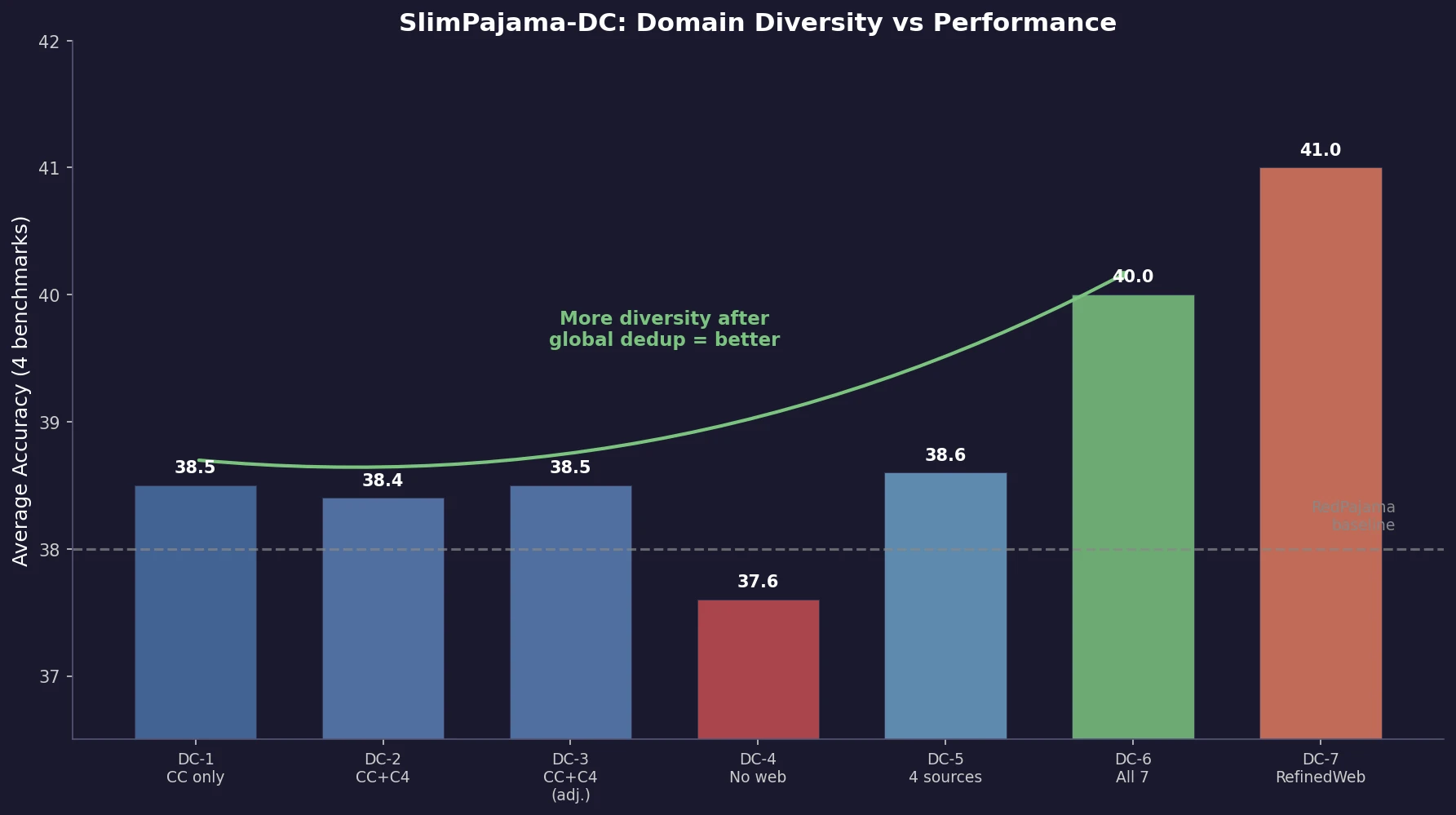
Shen et al. empirically analyze how different domain combinations and deduplication strategies in the SlimPajama dataset affect 1.3B model performance. Global deduplication across sources outperforms local deduplication, and increasing domain diversity consistently improves average accuracy, with findings transferring to 7B scale.
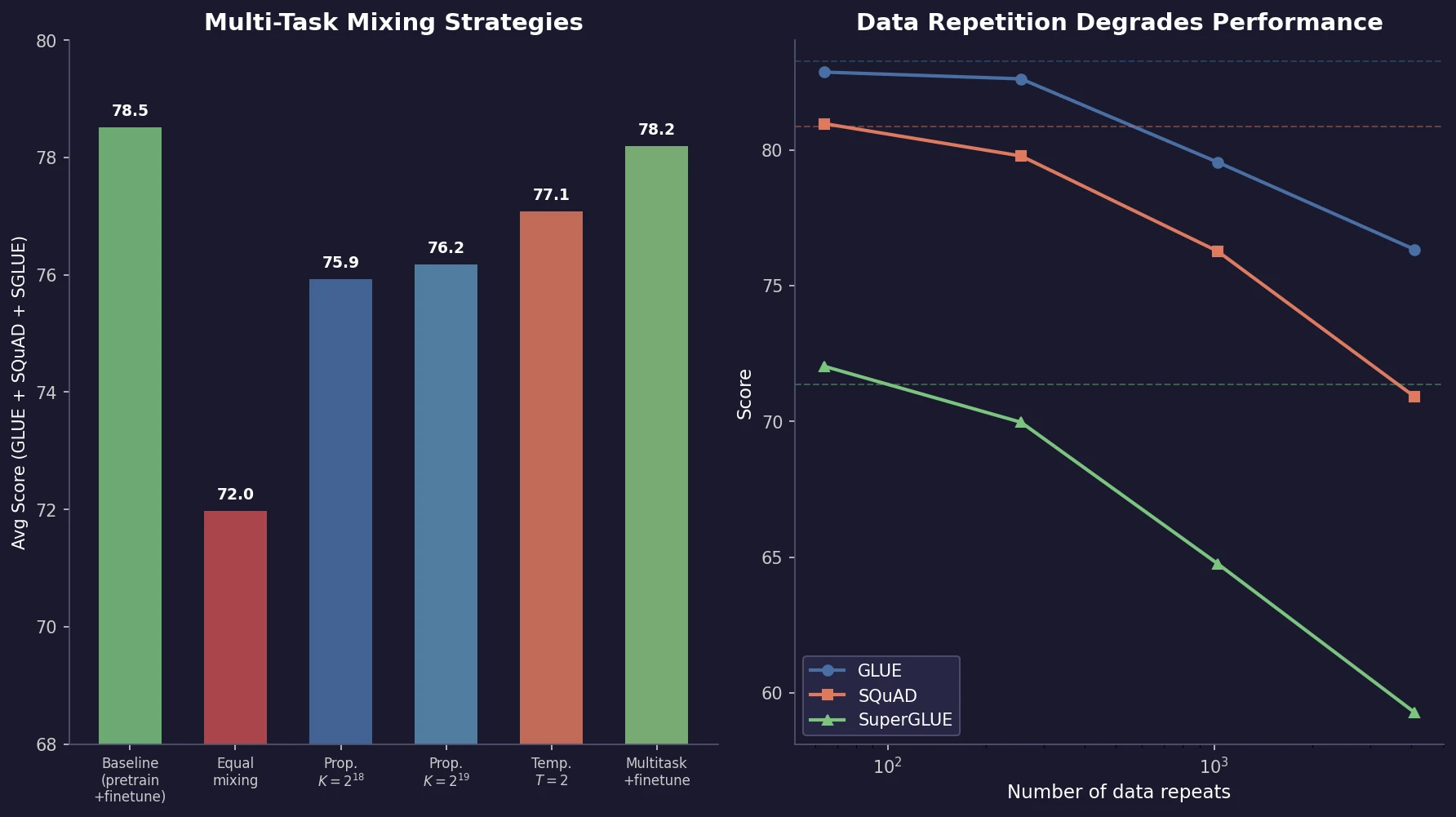
Raffel et al. introduce T5, a unified text-to-text framework for NLP transfer learning. Through systematic ablation of architectures, pre-training objectives, datasets, and multi-task mixing strategies, they identify best practices and scale to 11B parameters, achieving state-of-the-art results across multiple benchmarks.
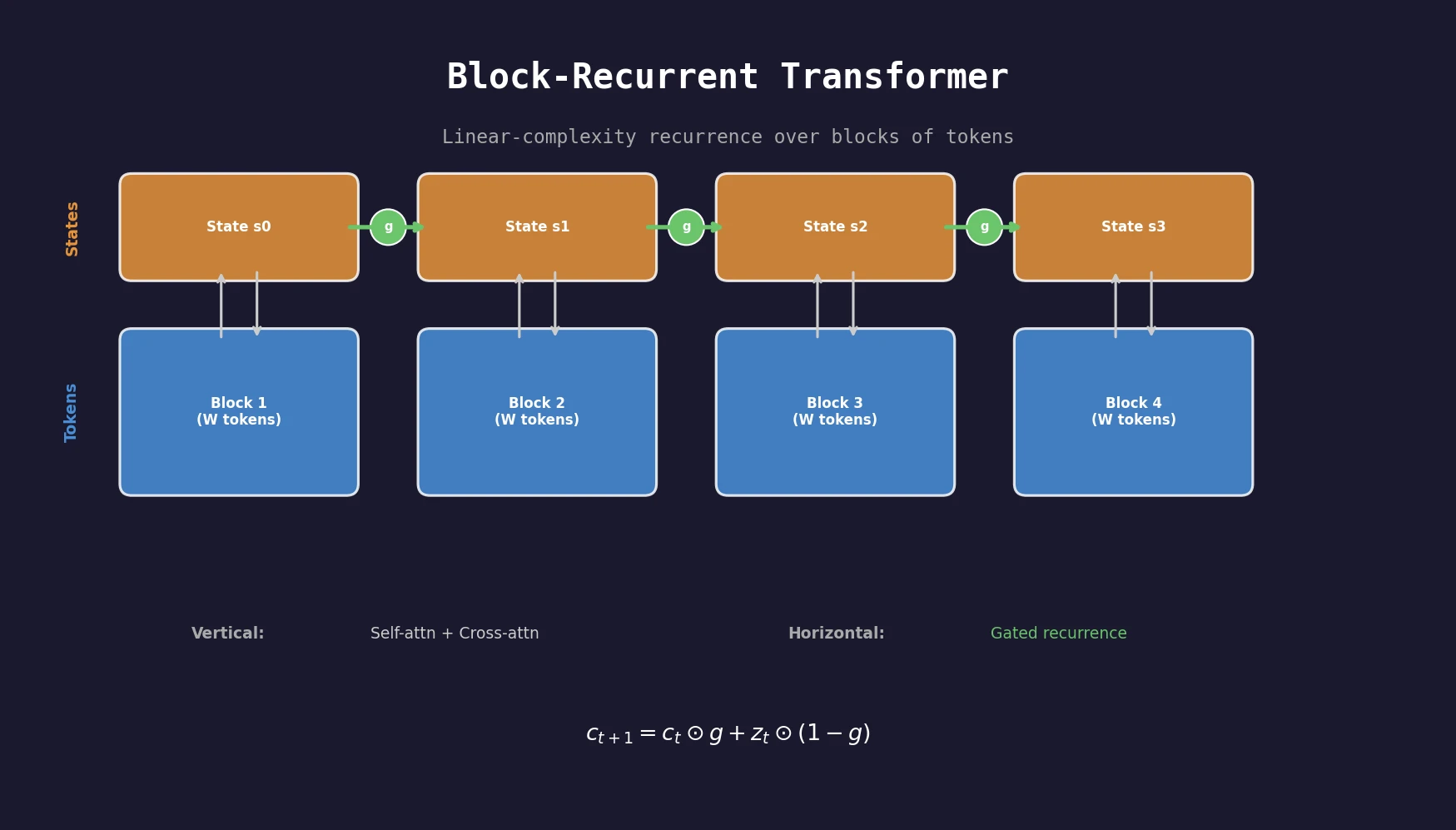
A transformer architecture that applies a recurrent cell over blocks of tokens, achieving linear complexity in sequence length while outperforming Transformer-XL baselines on PG19, arXiv, and GitHub datasets.
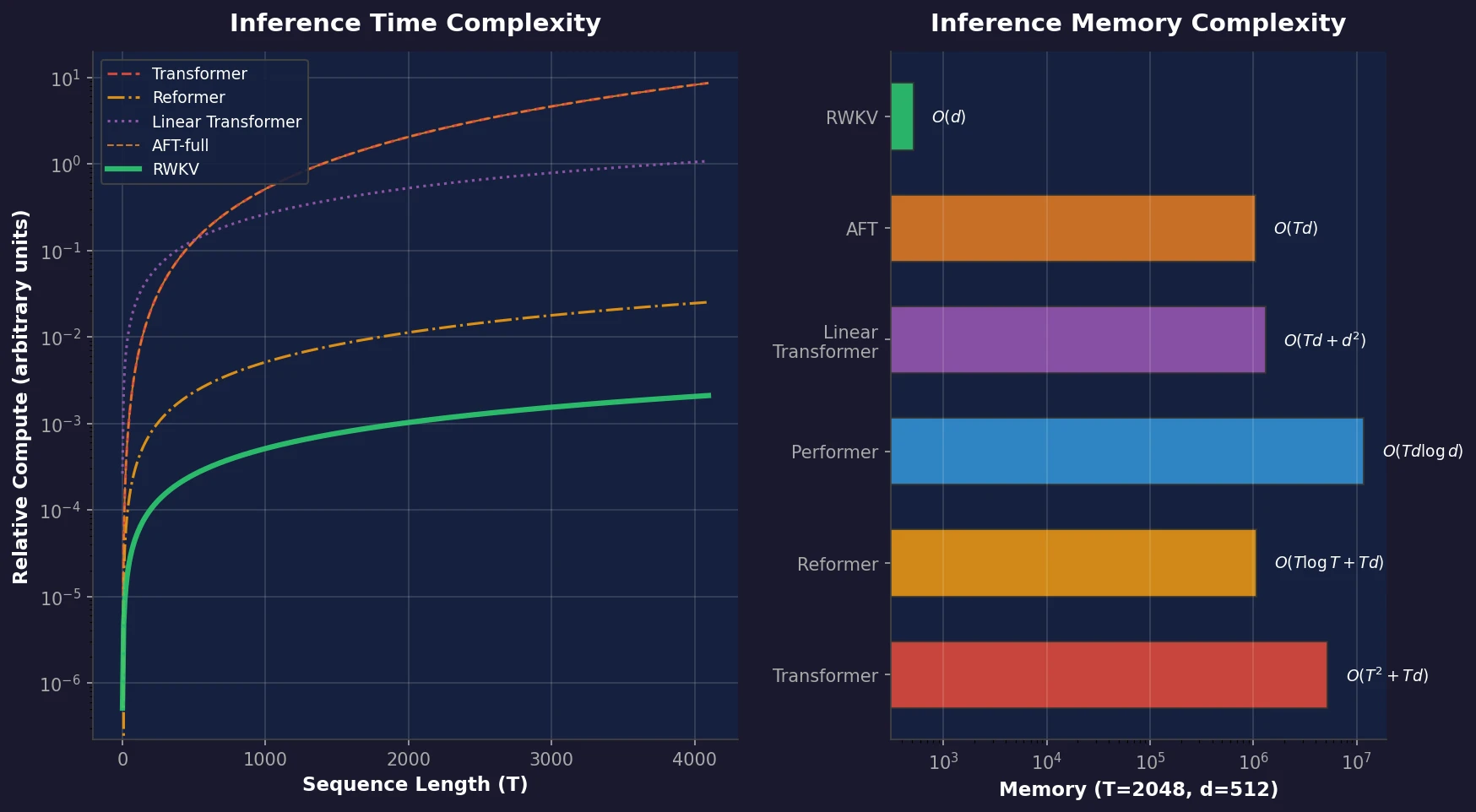
RWKV is a novel sequence model that achieves transformer-level performance while maintaining linear time and constant memory complexity during inference, scaled up to 14 billion parameters.
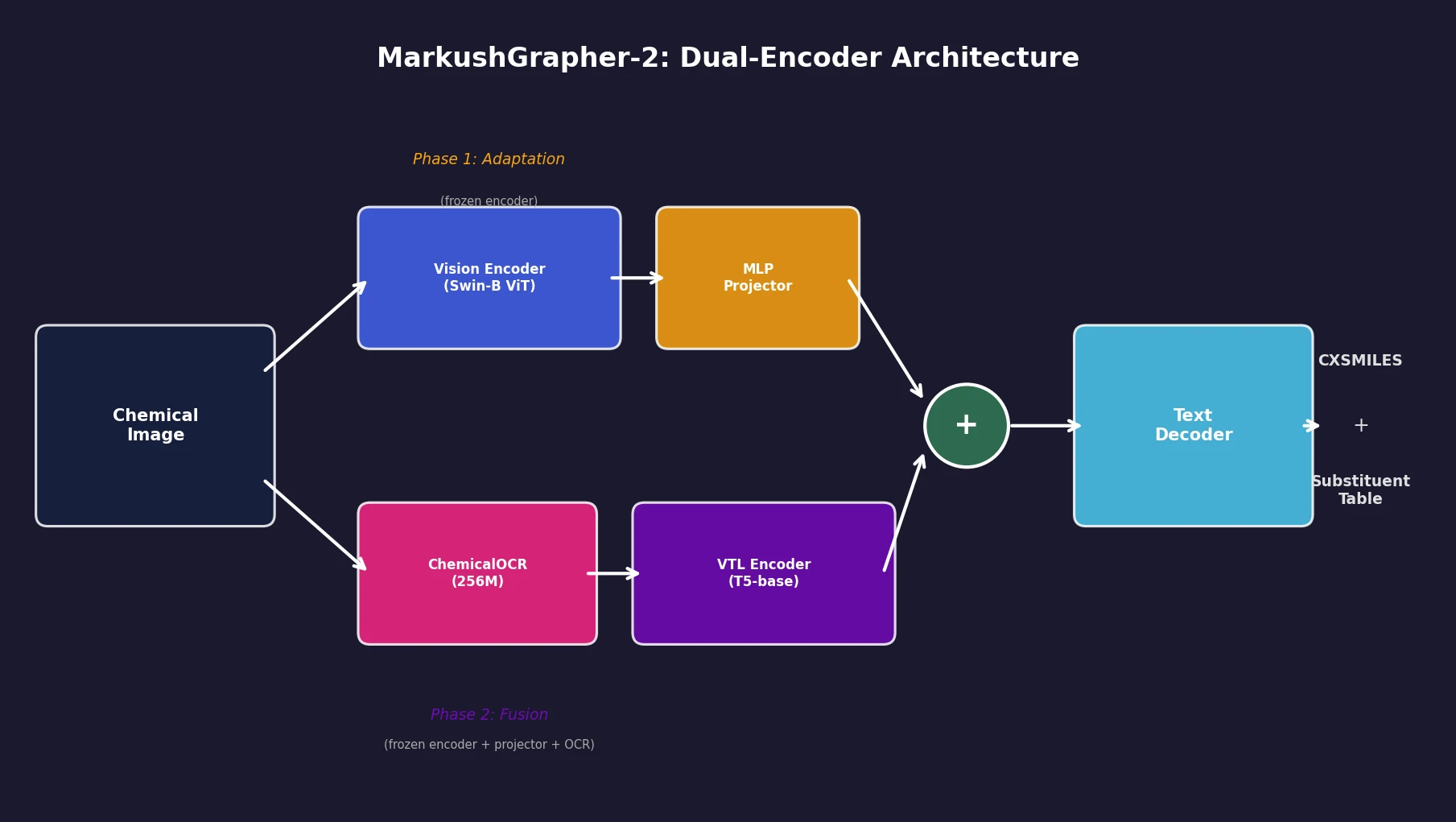
An 831M-parameter encoder-decoder model that jointly encodes image, OCR text, and layout information through a two-stage training strategy, achieving state-of-the-art multimodal Markush structure recognition while remaining competitive on standard molecular structure recognition.
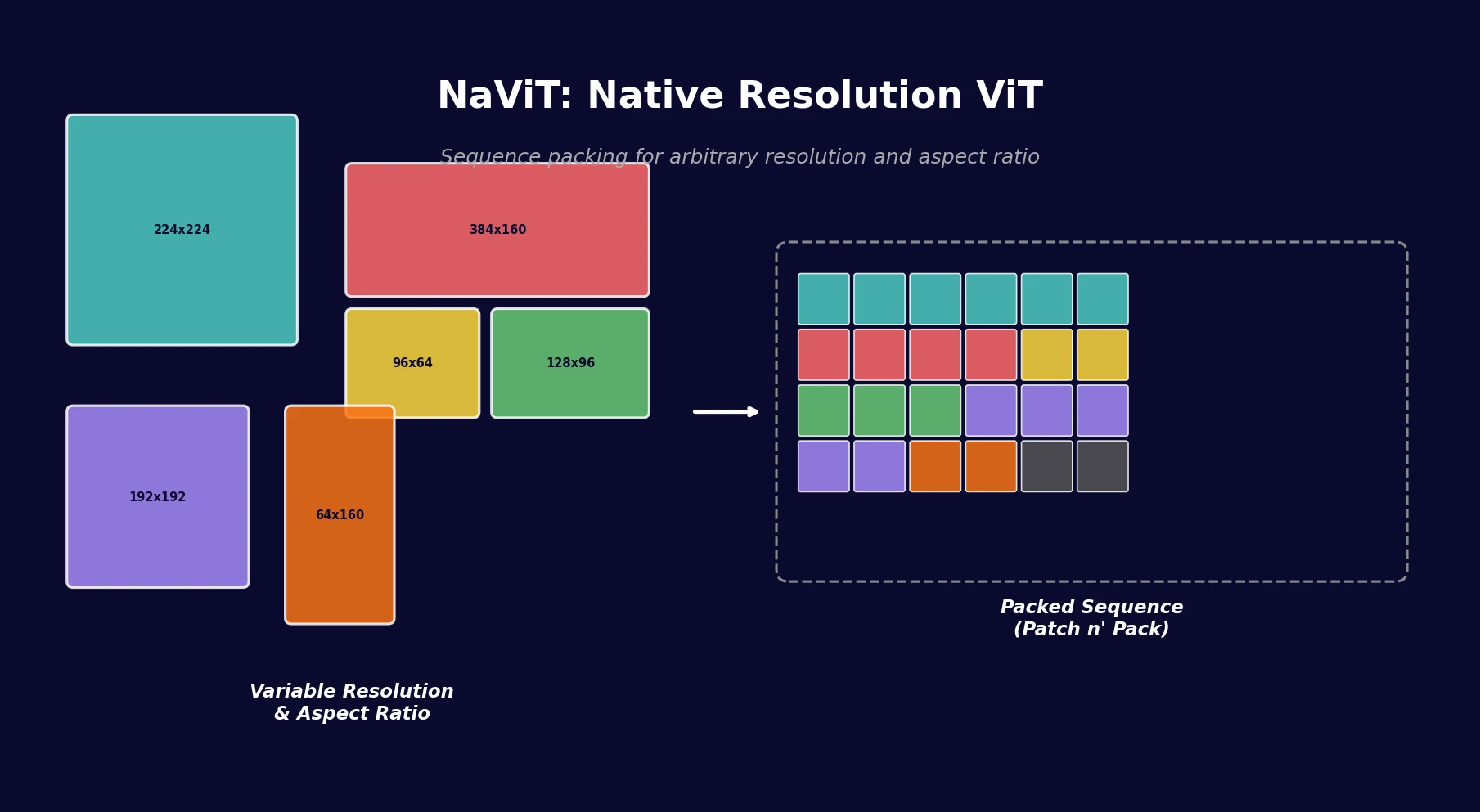
NaViT applies sequence packing (Patch n’ Pack) to Vision Transformers, enabling training on images of arbitrary resolution and aspect ratio while improving training efficiency by up to 4x over standard ViT.