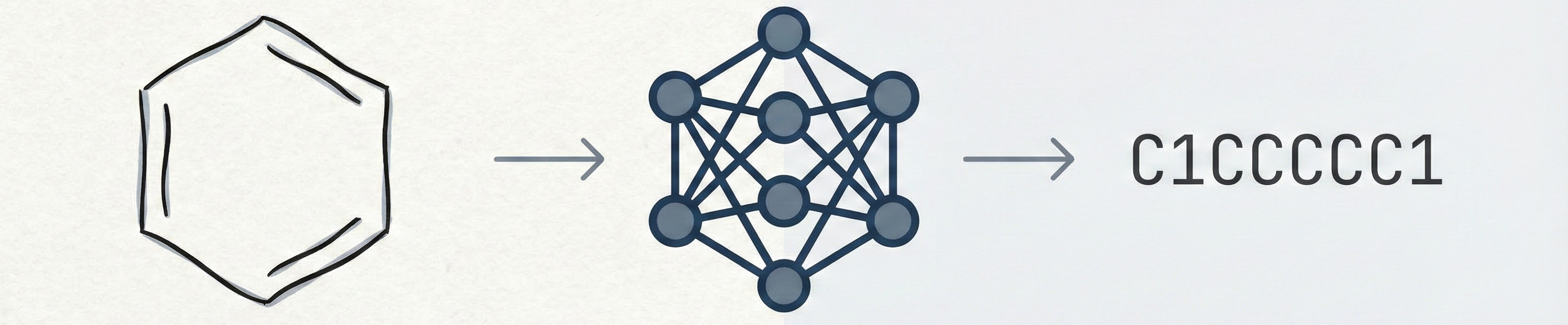
ChemPix: Hand-Drawn Hydrocarbon Structure Recognition
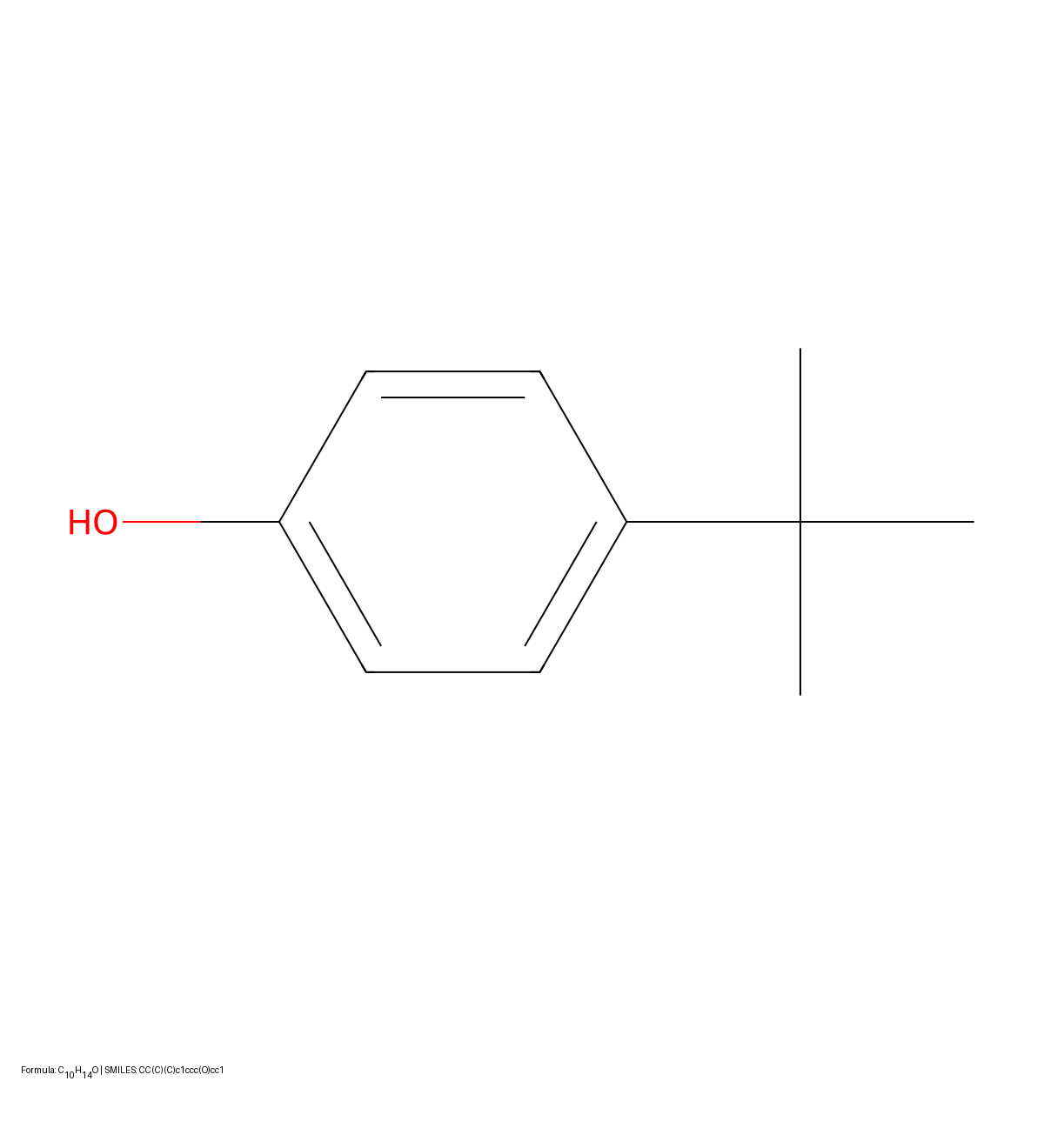
Proposes a CNN-LSTM architecture that treats chemical structure recognition as an image captioning task. Introduces a synthetic data generation pipeline with augmentation, degradation, and background addition to train models that generalize to hand-drawn inputs without seeing real data during training.