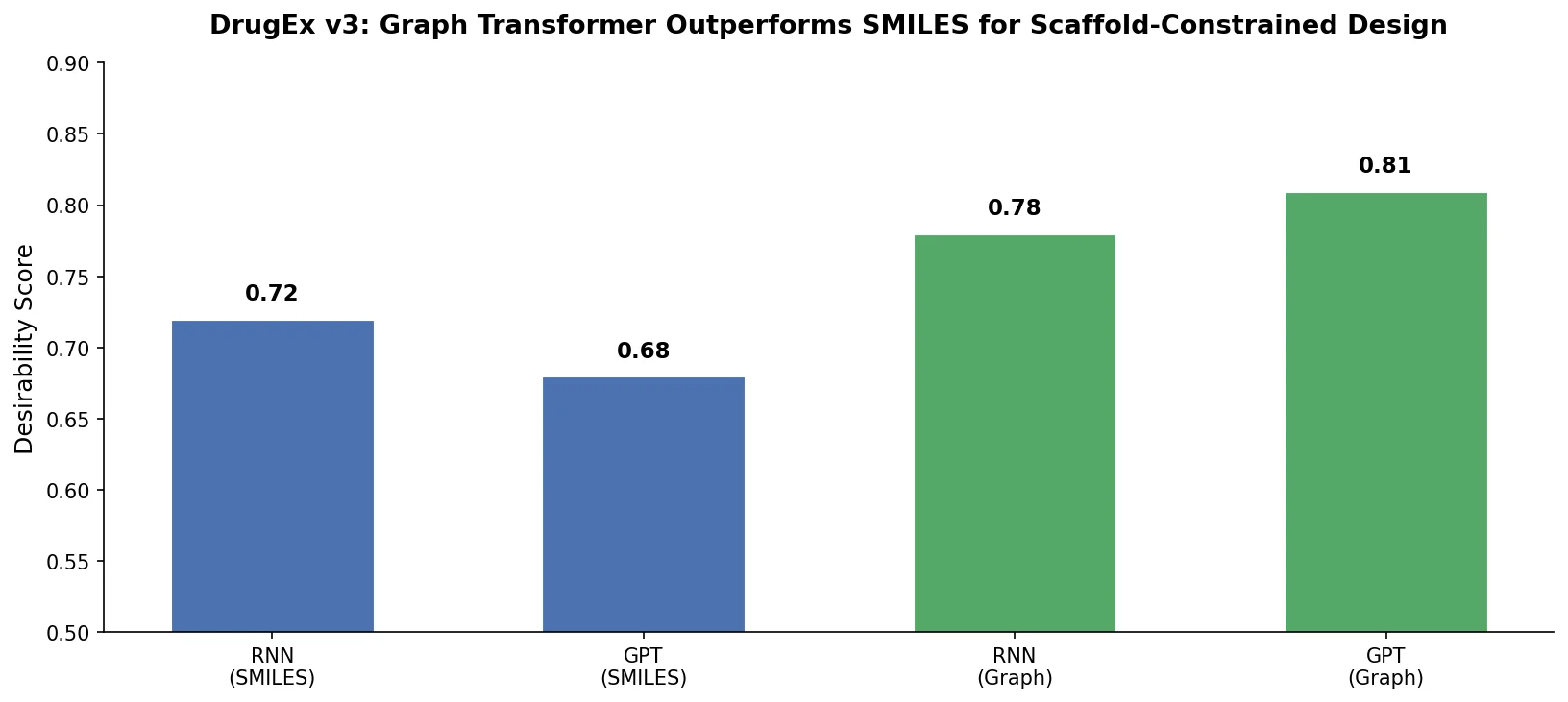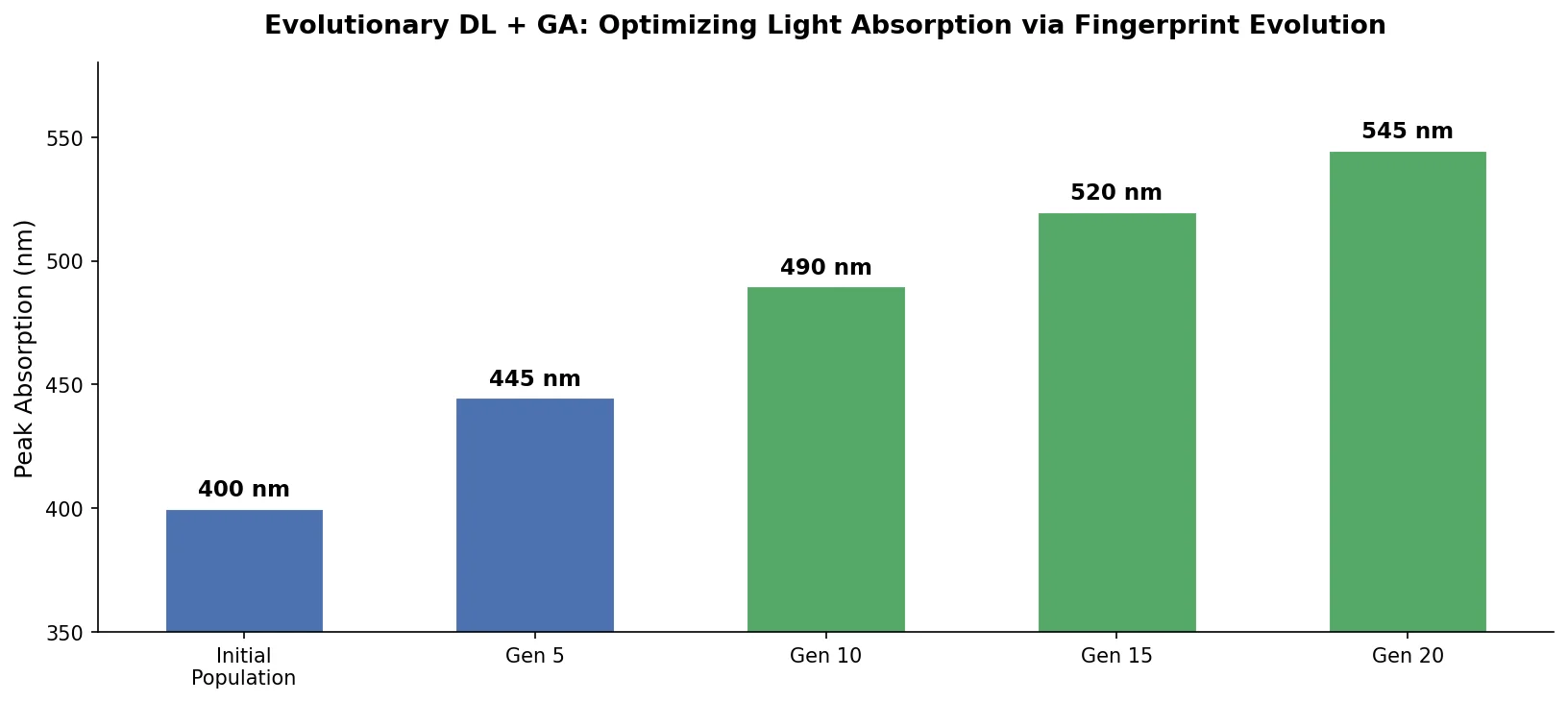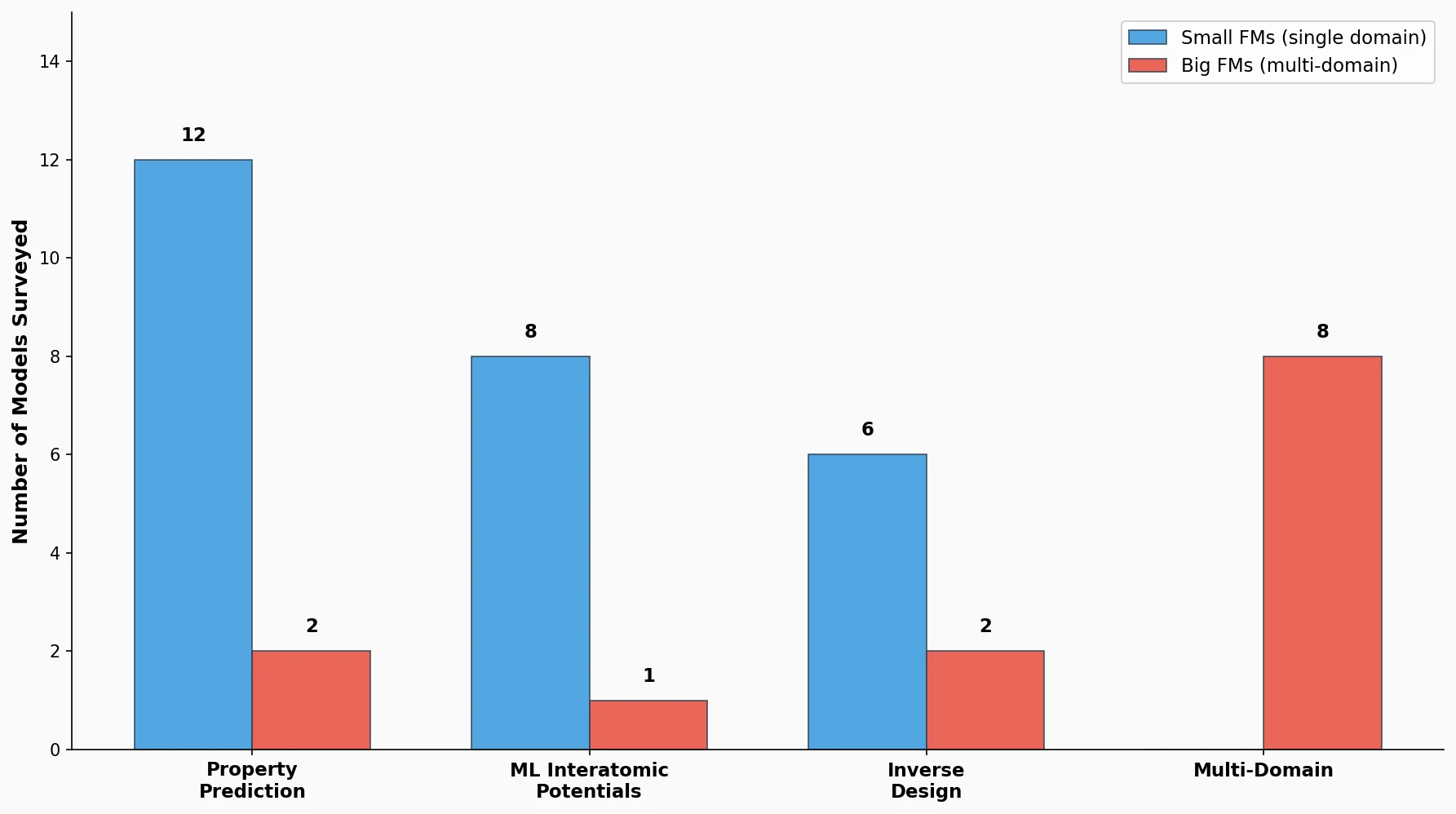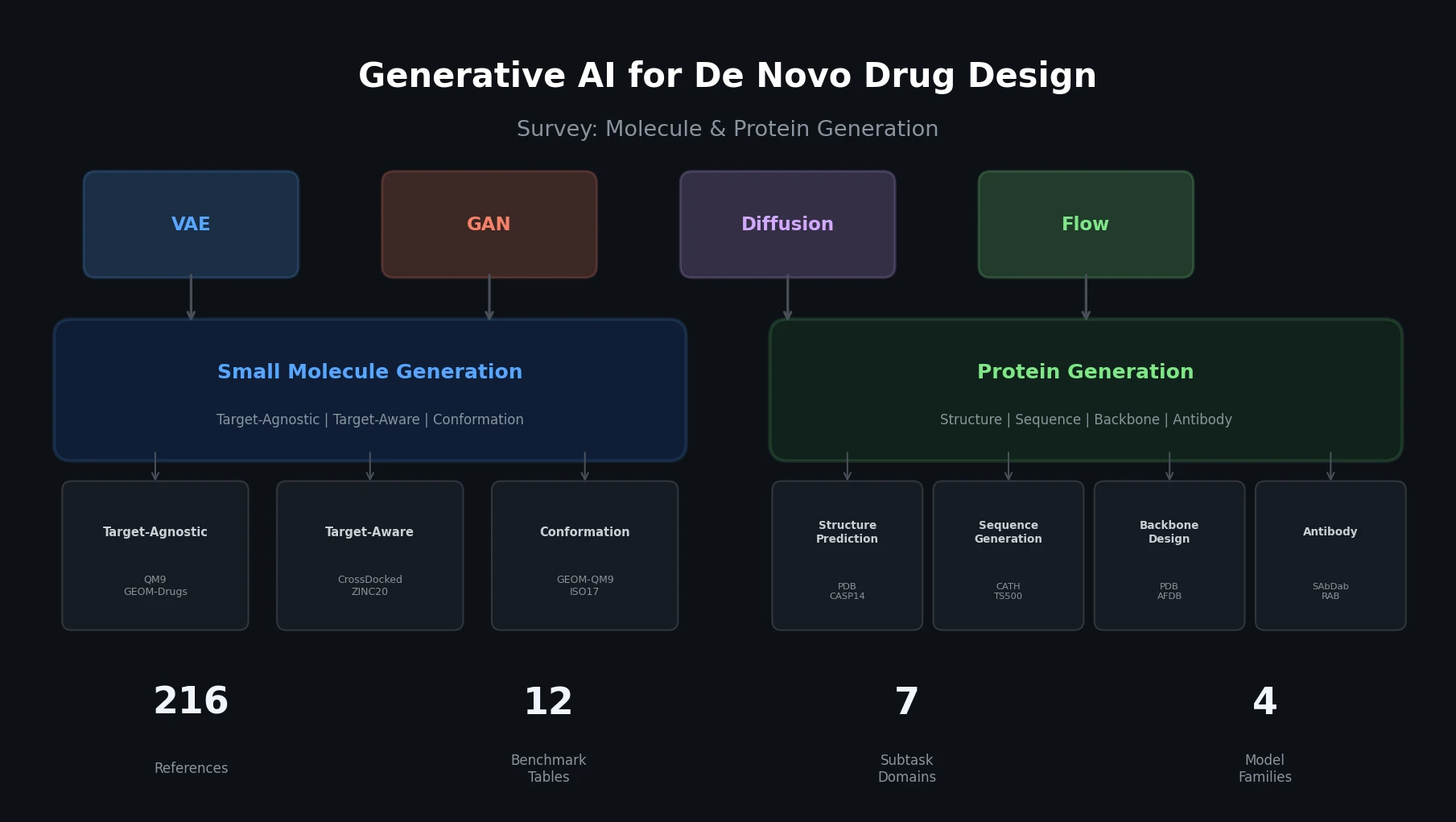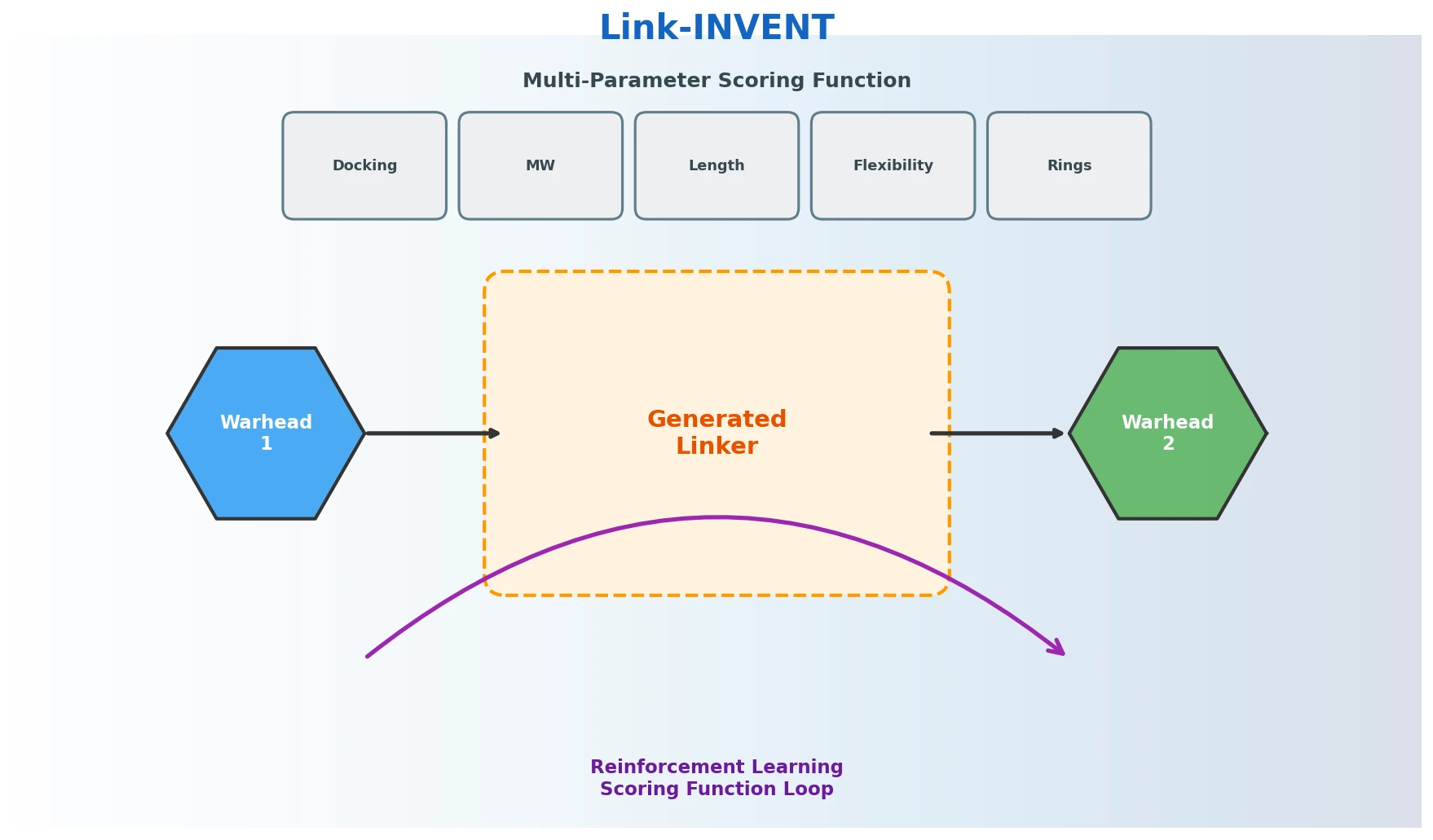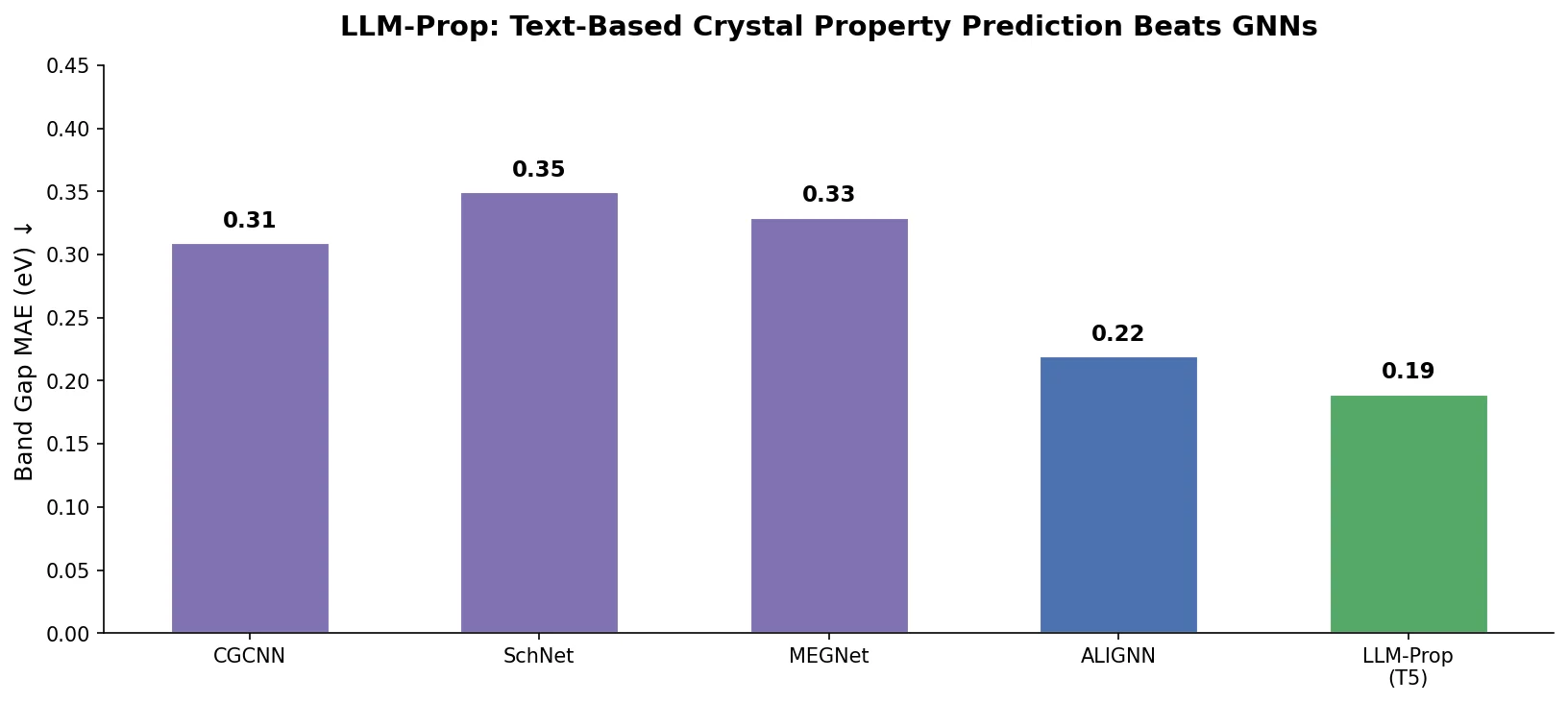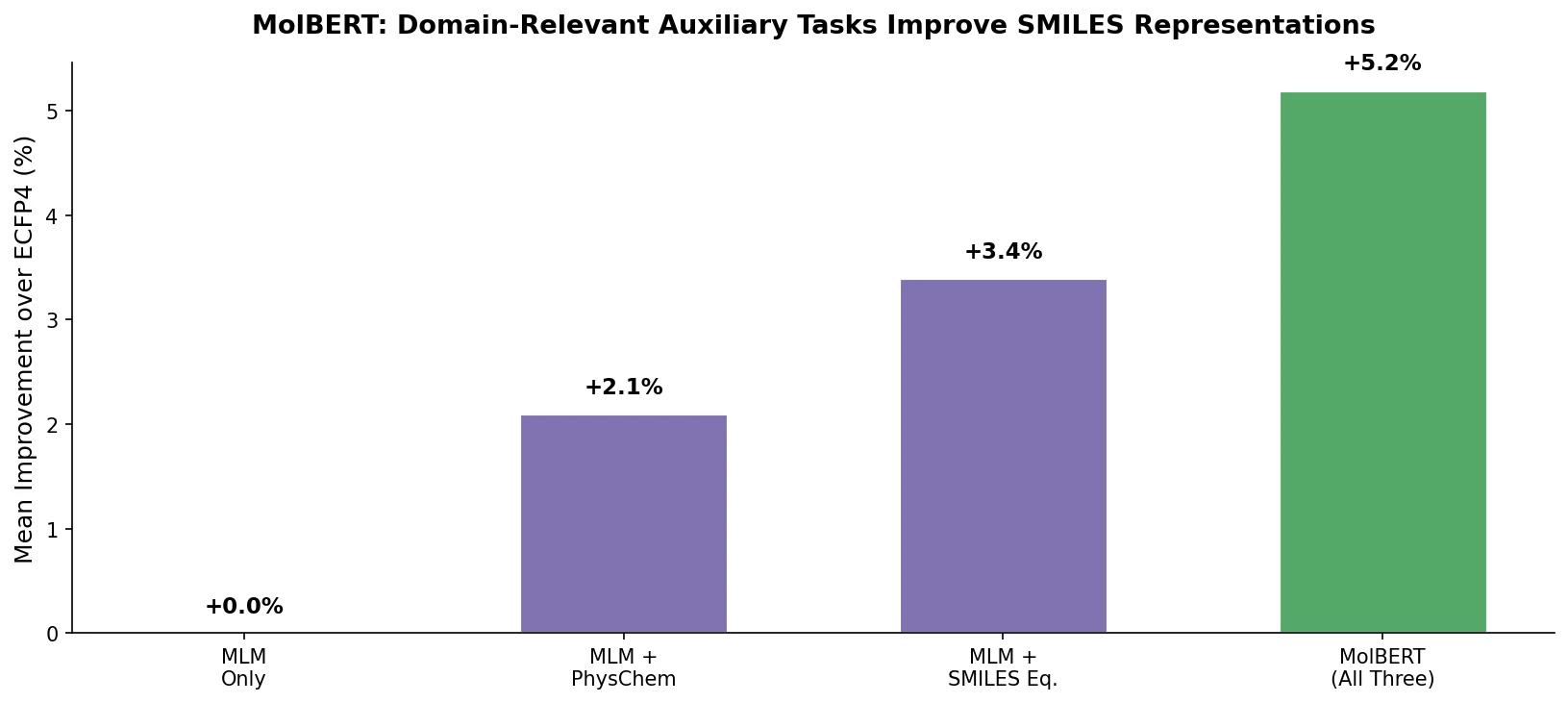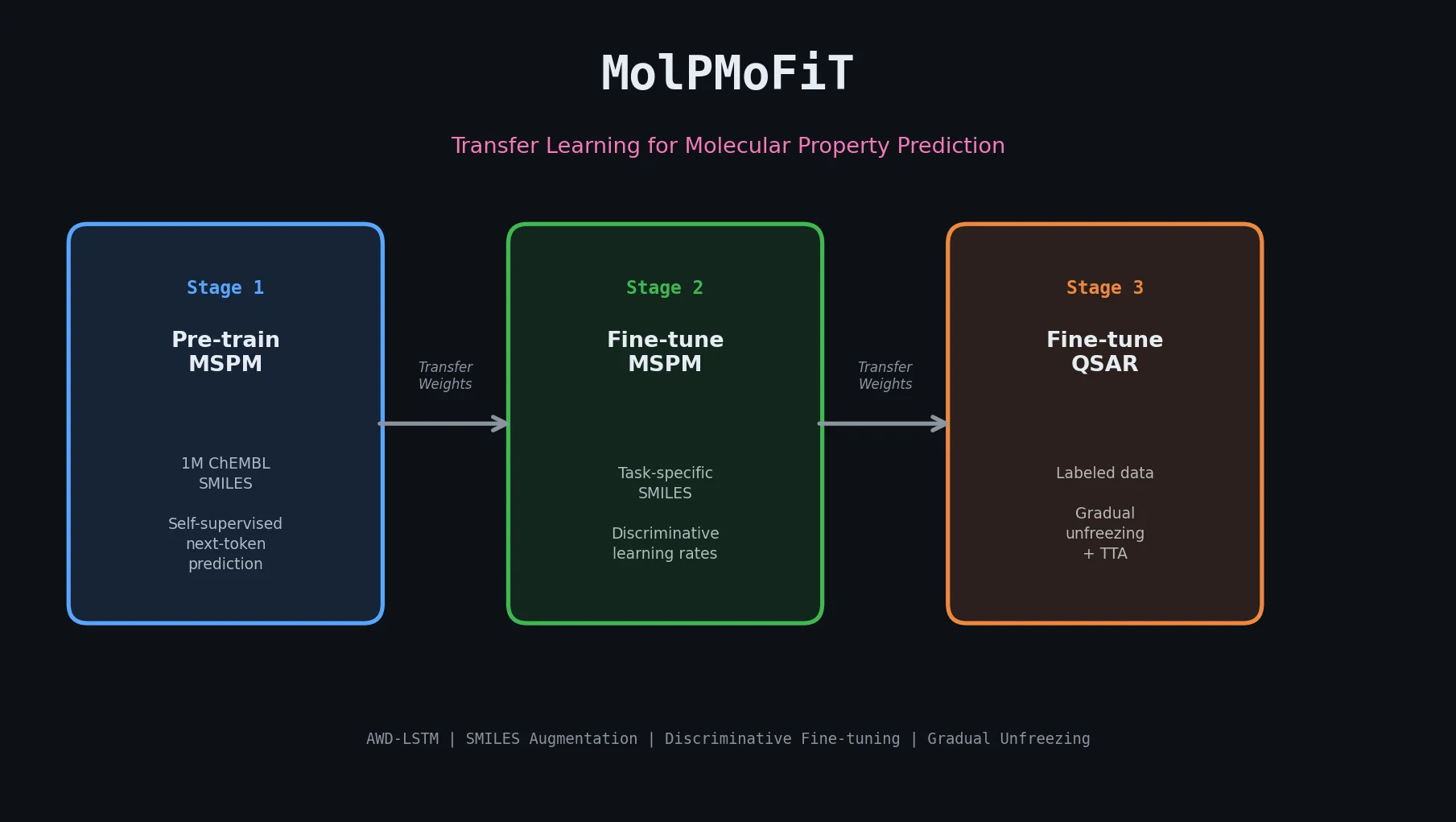
DeepSMILES: Adapting SMILES Syntax for Machine Learning
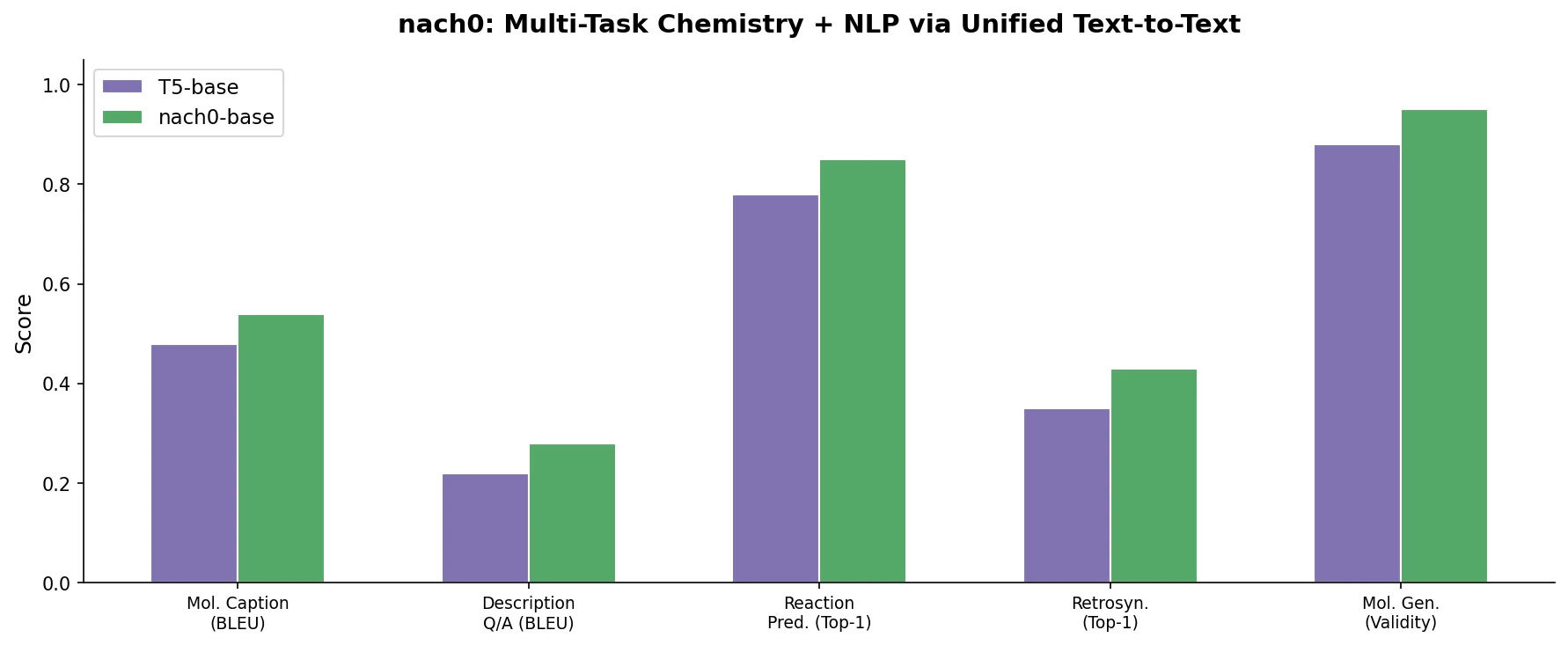
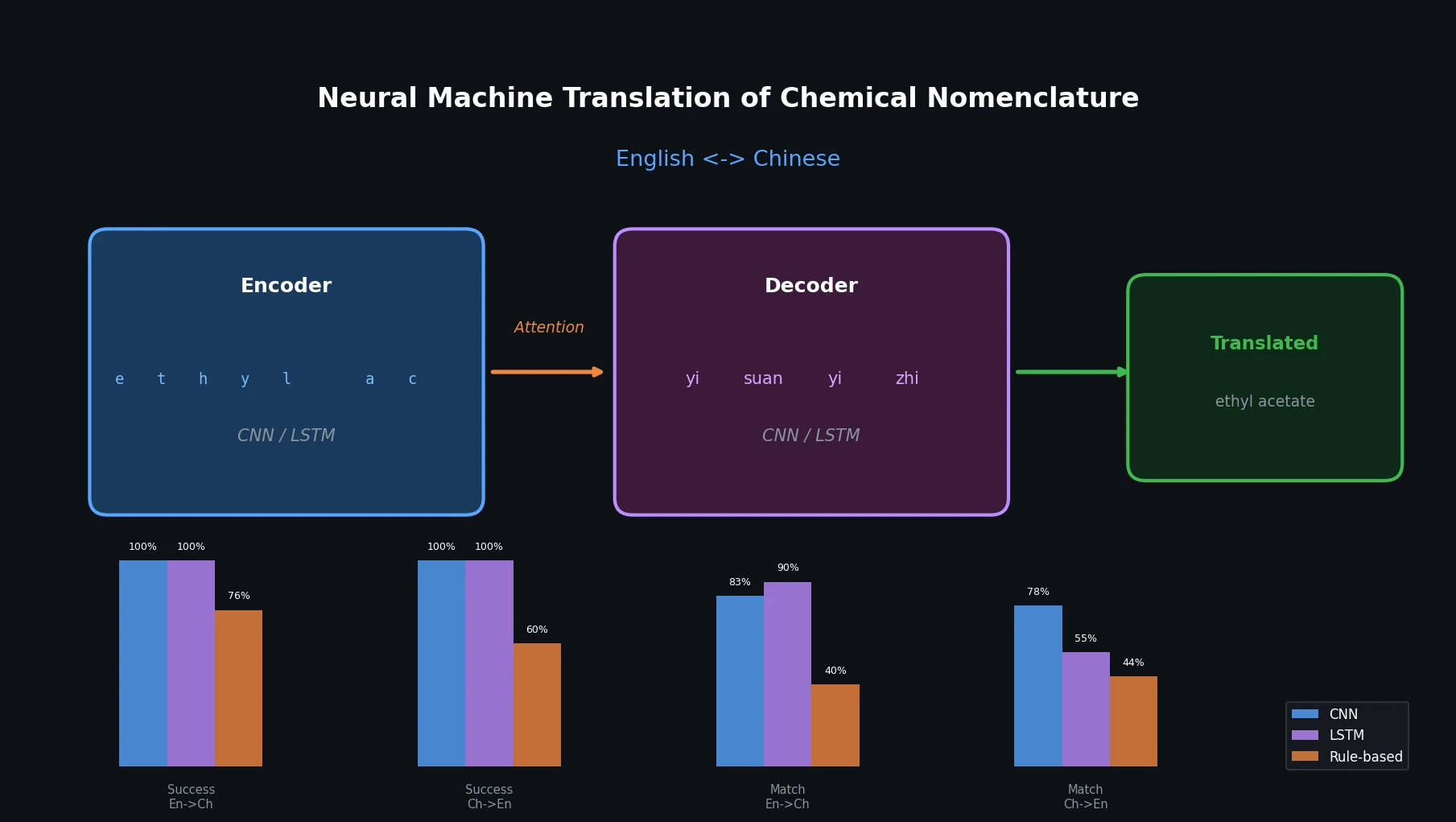
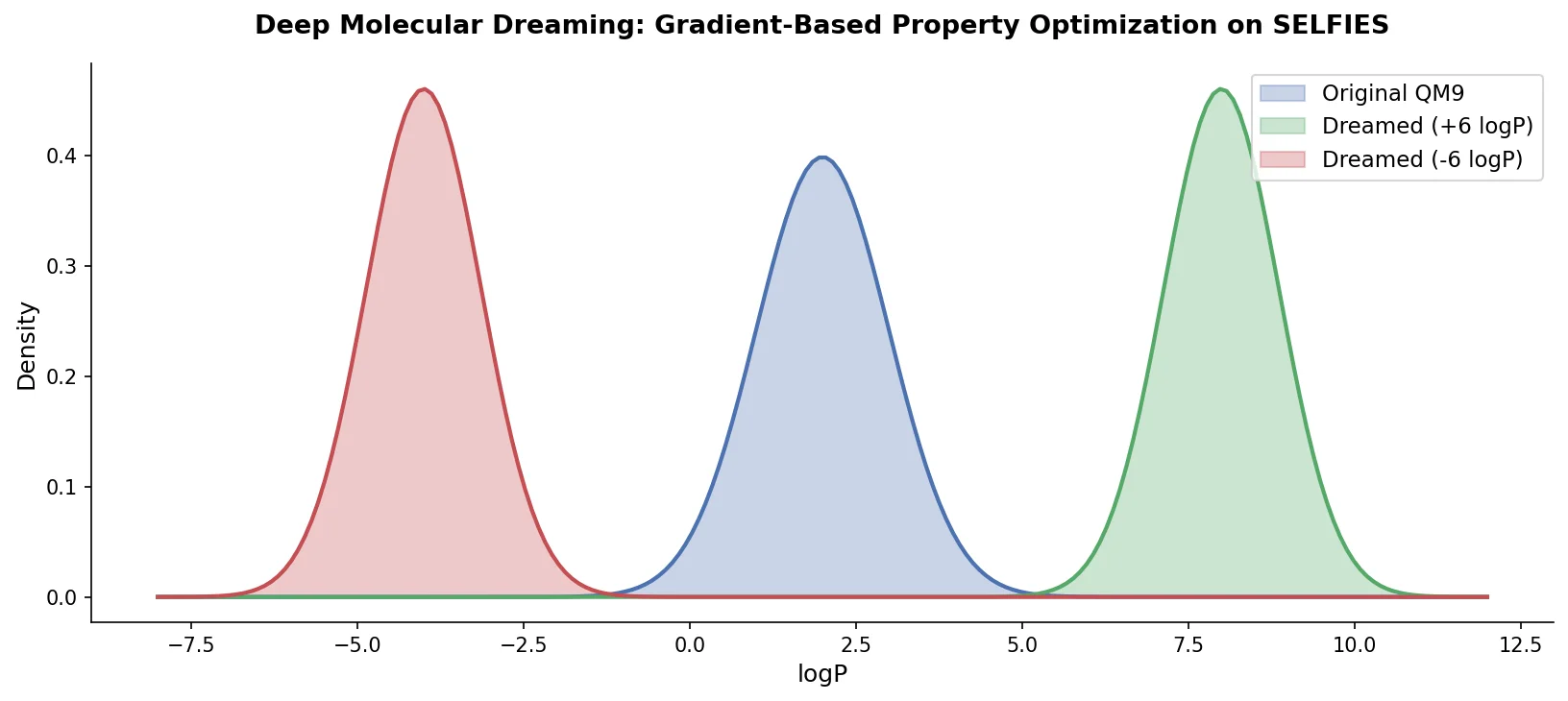
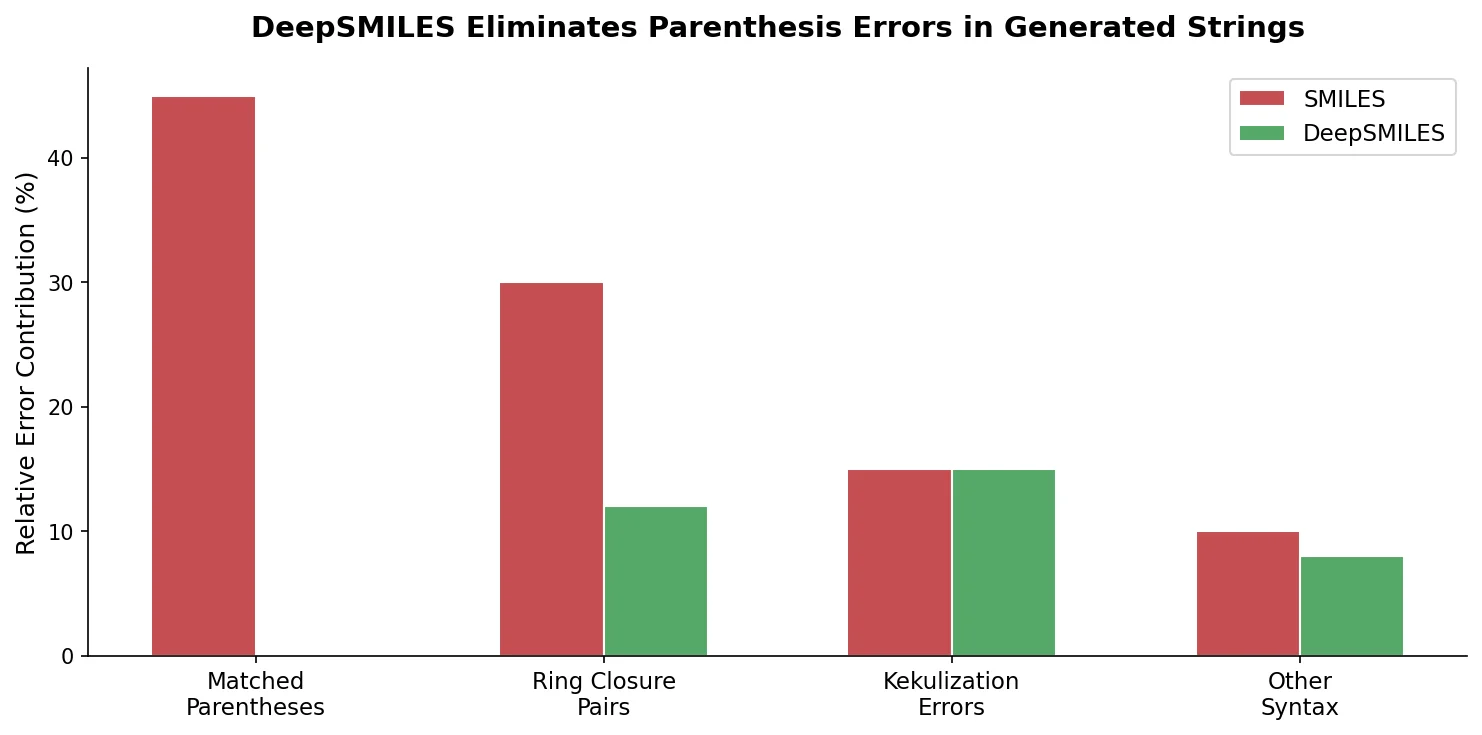
DeepSMILES replaces paired parentheses and ring closure symbols in SMILES with a postfix notation and single ring-size digits, making it easier for generative models to produce syntactically valid molecular strings.