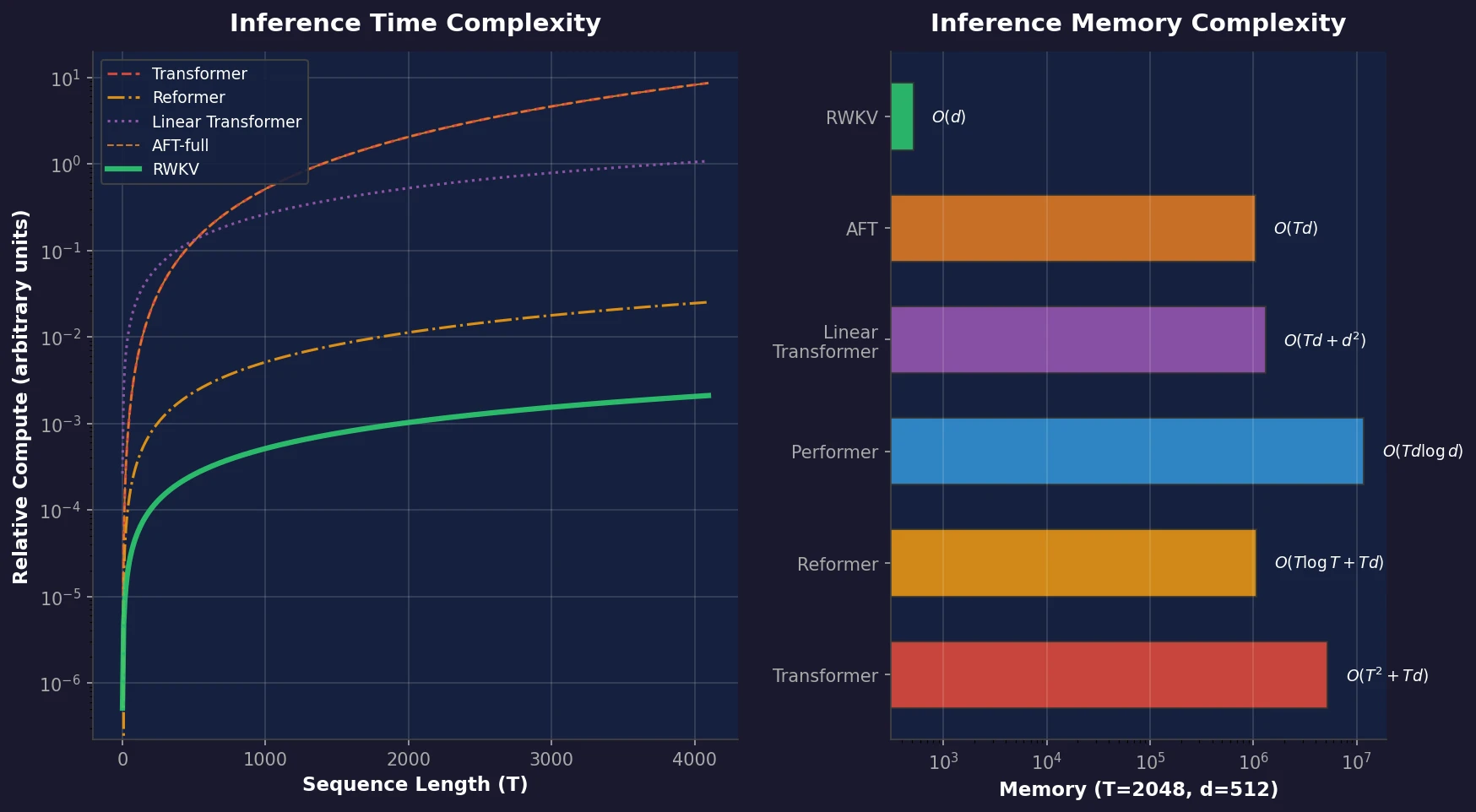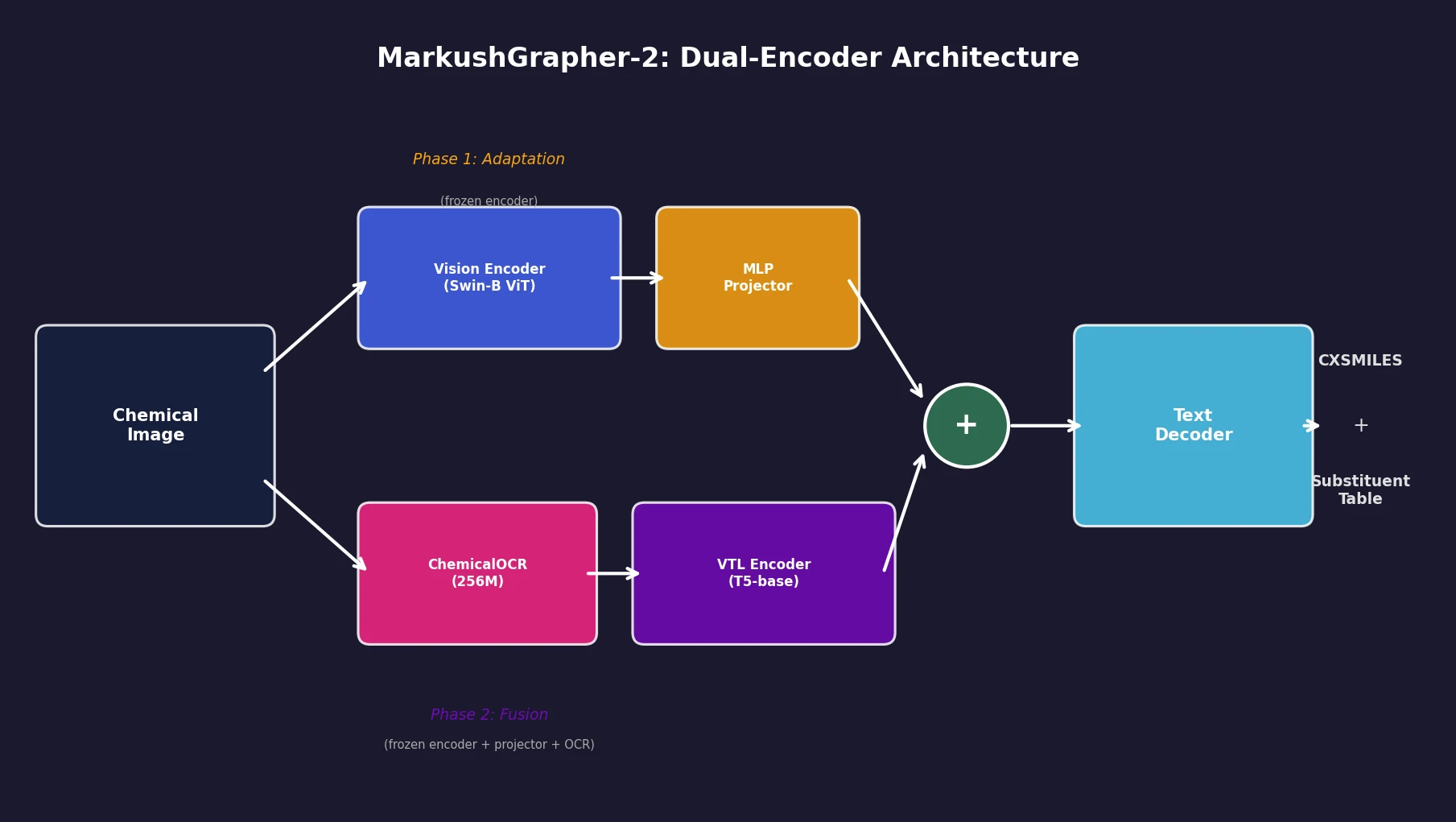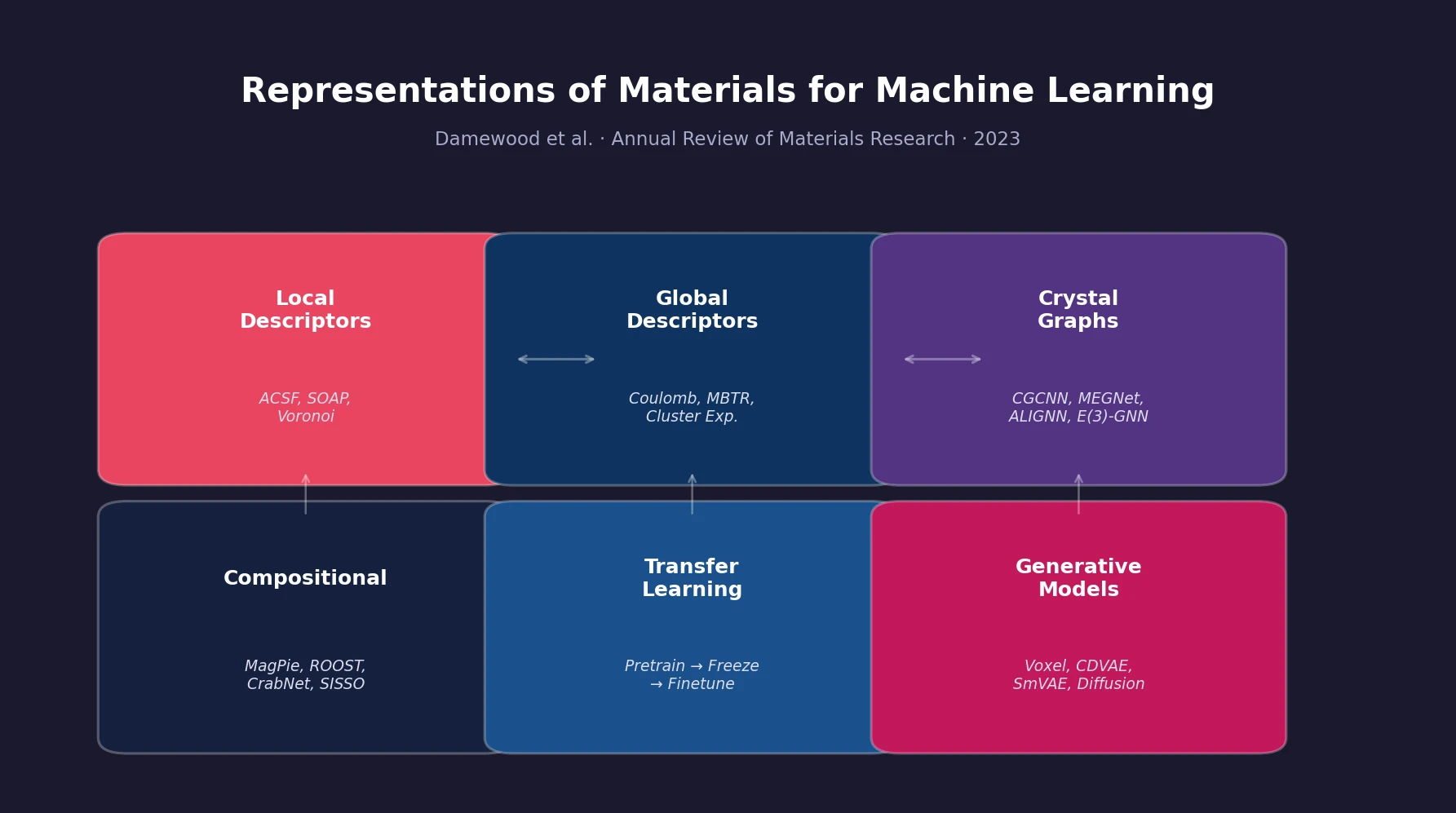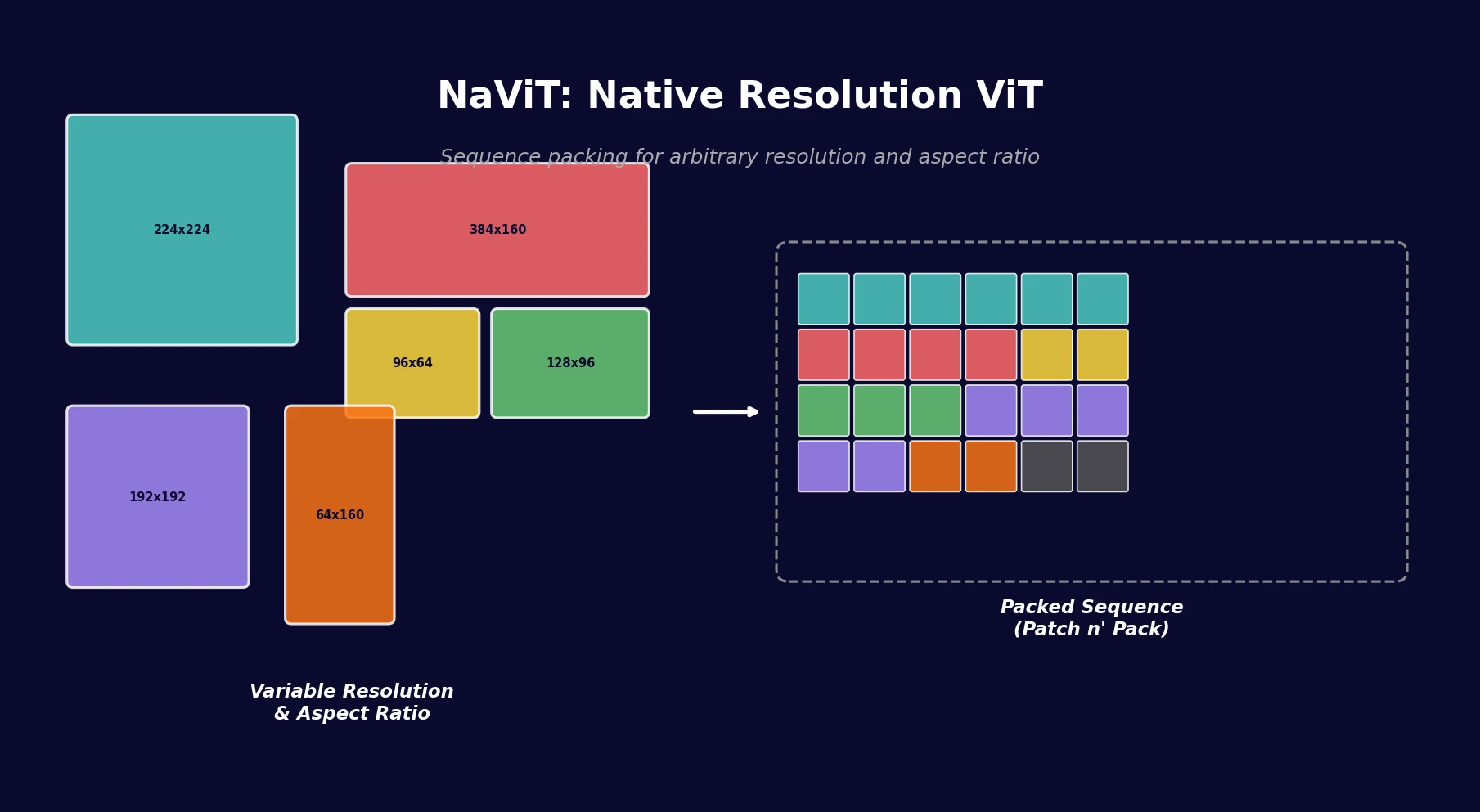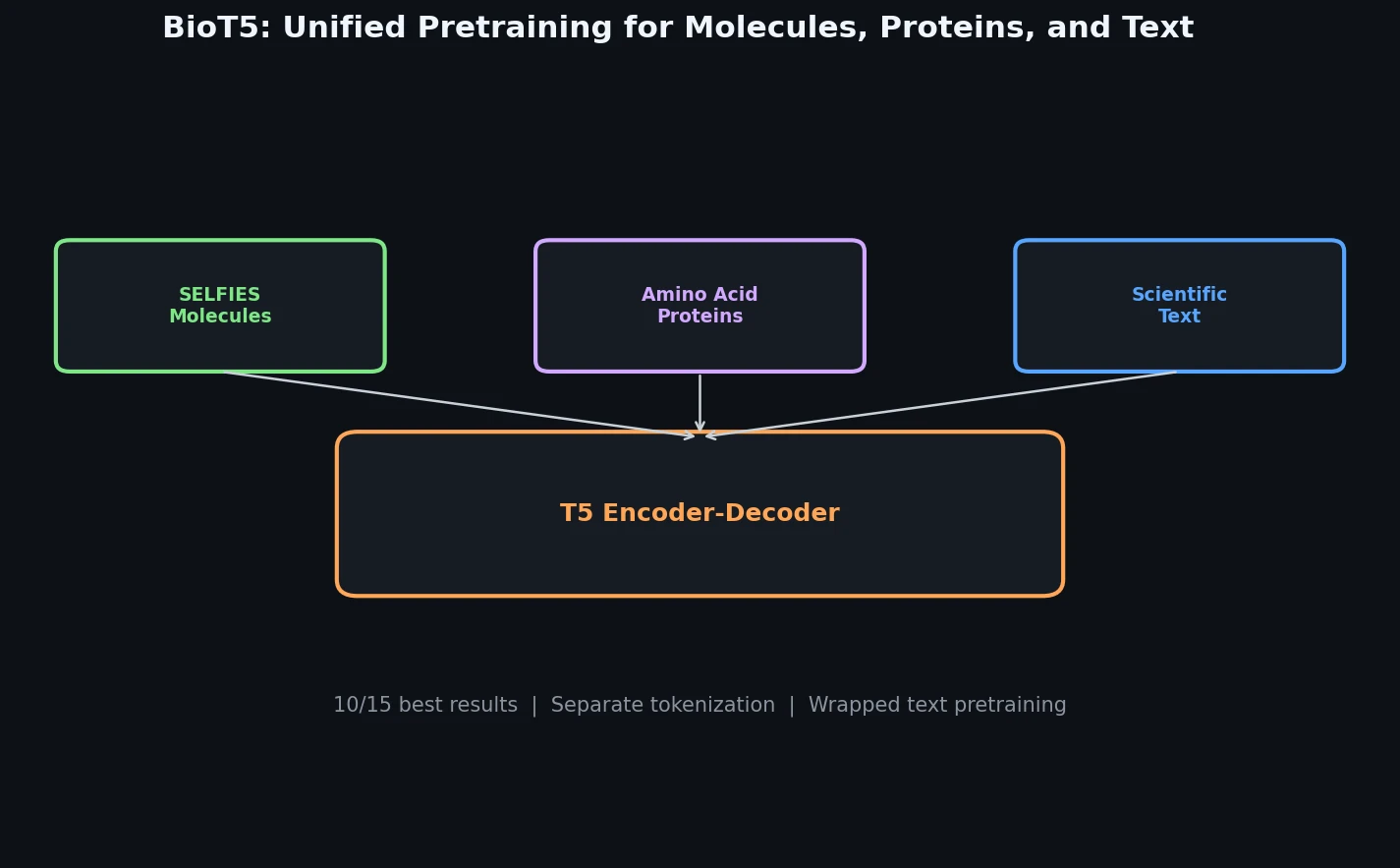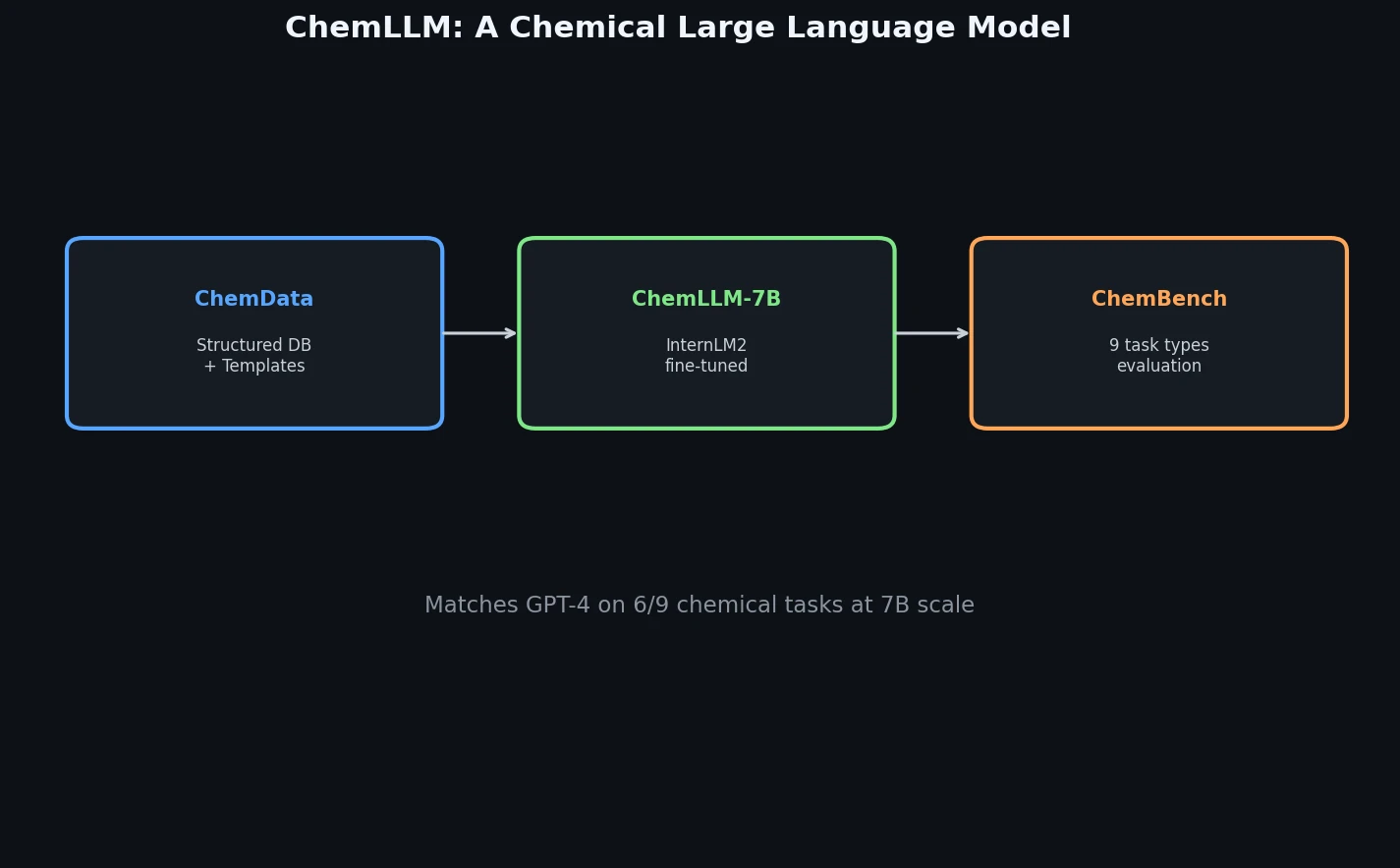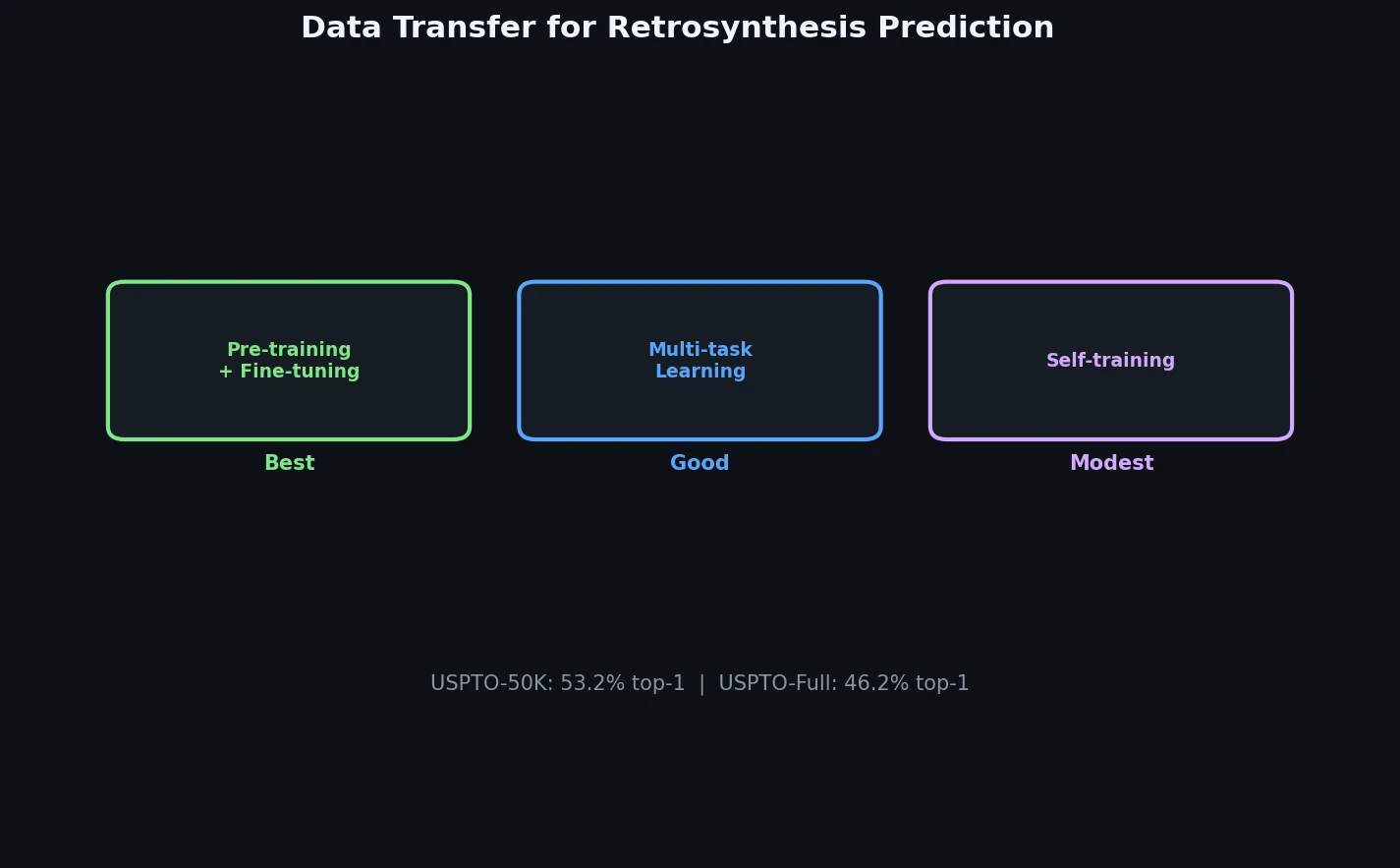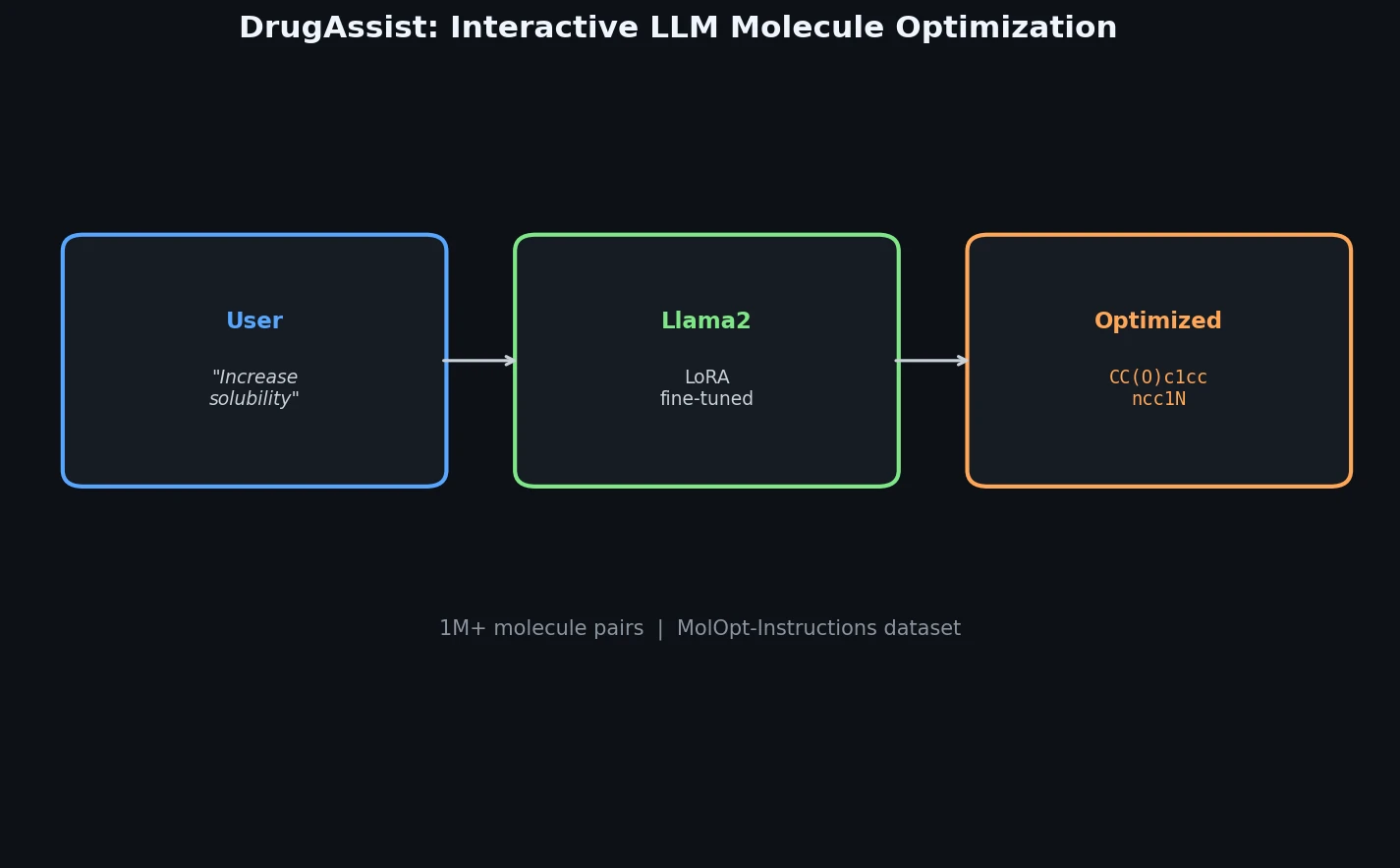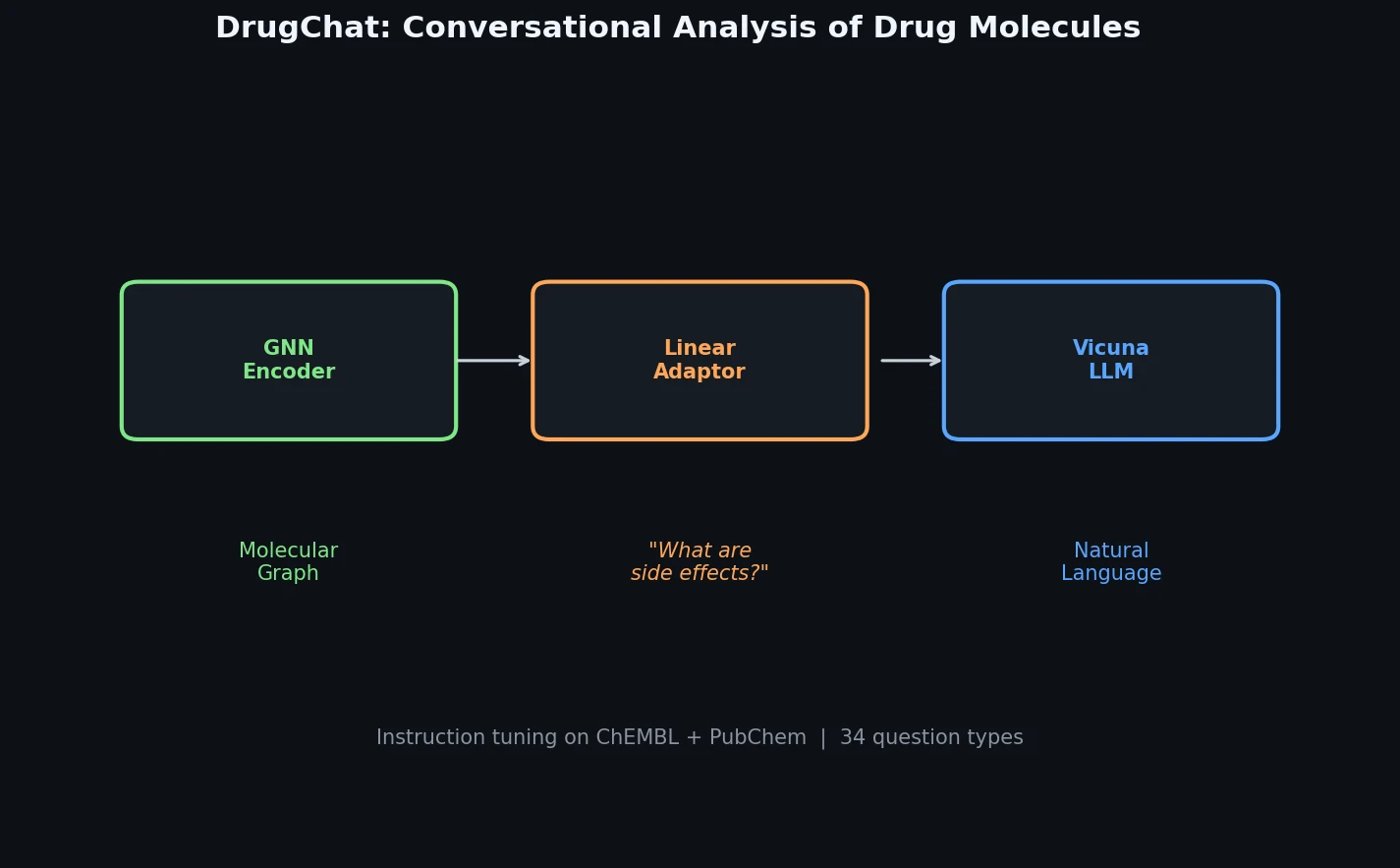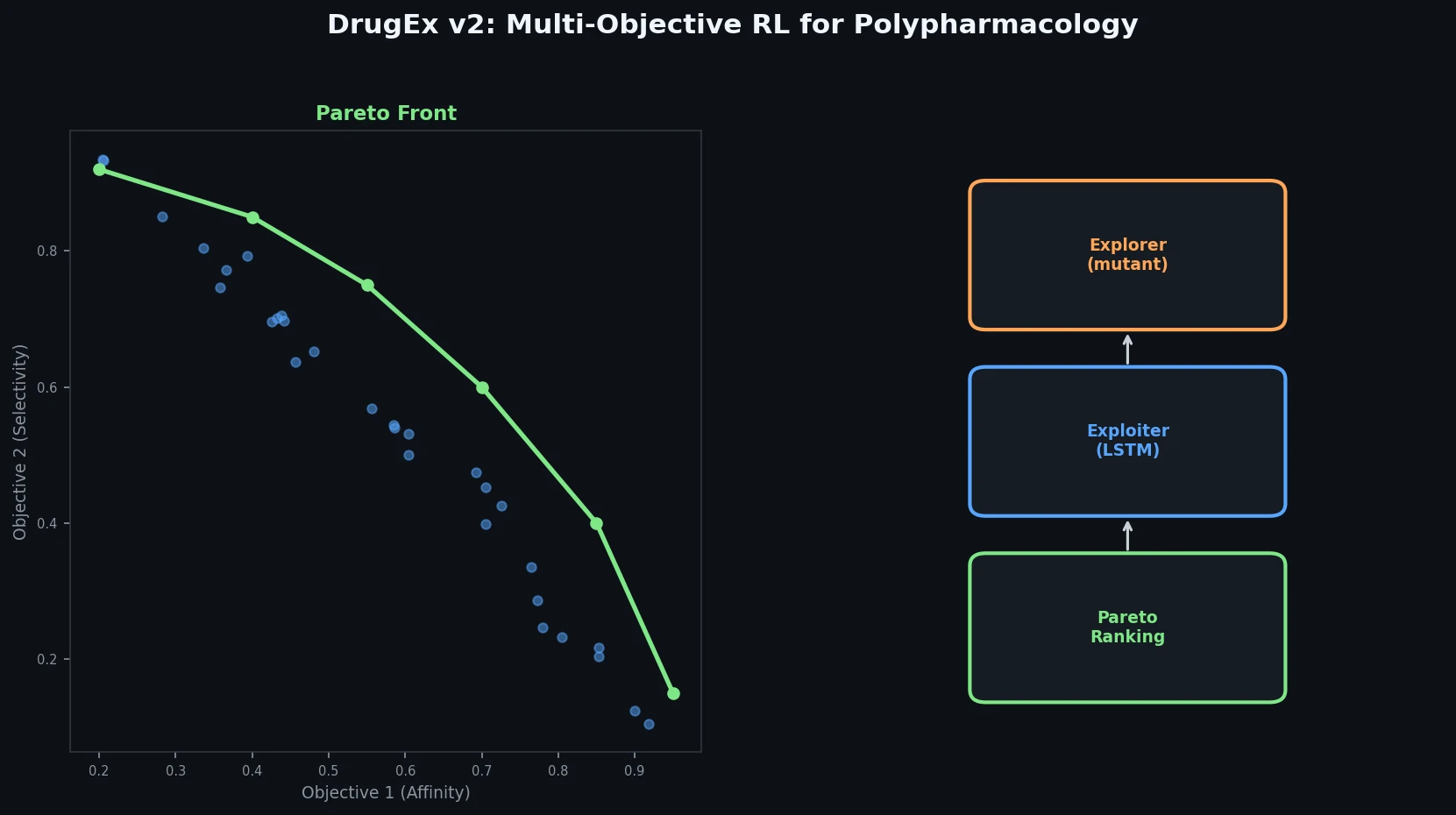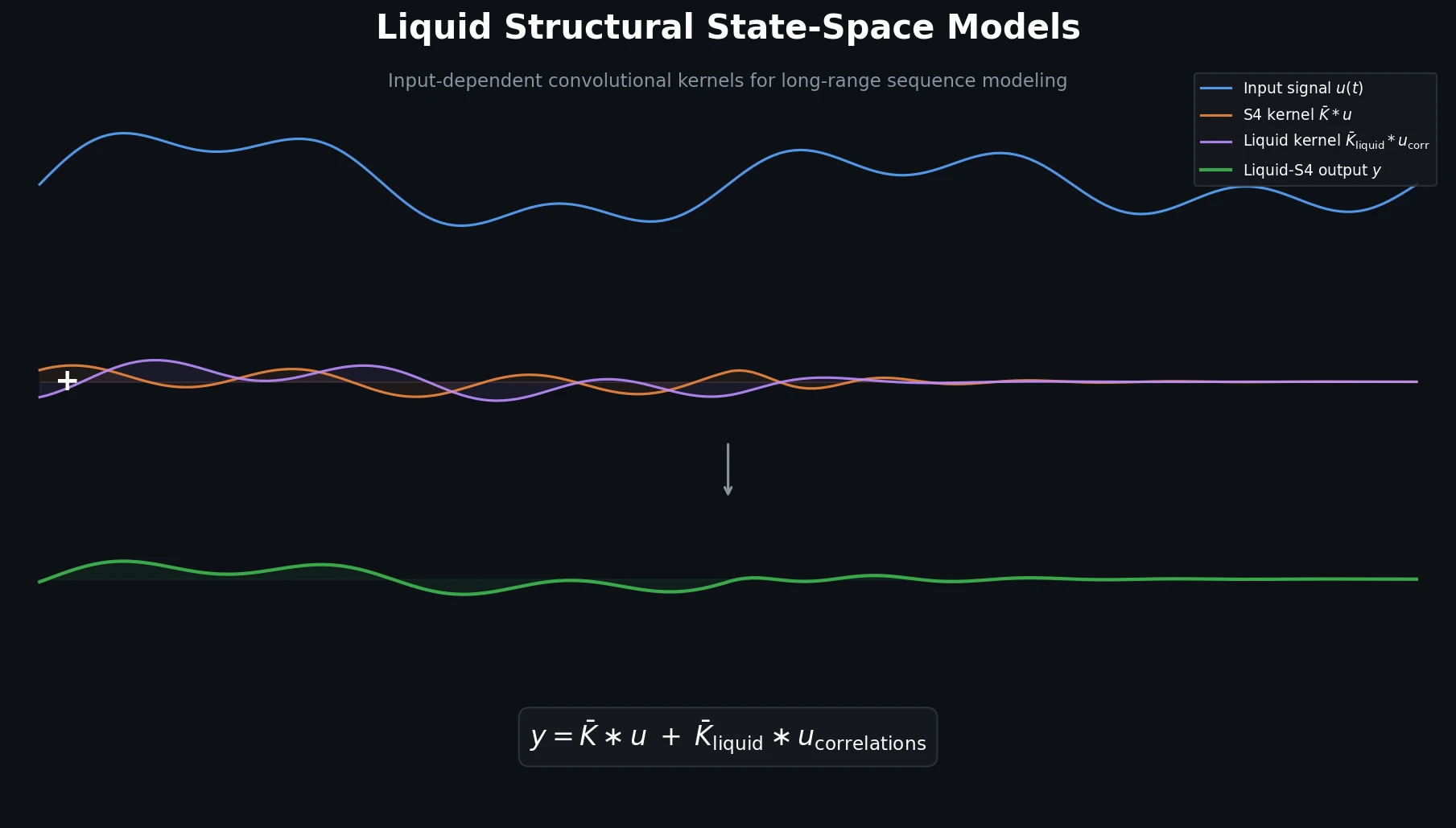
Liquid-S4: Input-Dependent State-Space Models
Liquid-S4 extends the S4 framework by incorporating a linearized liquid time-constant formulation that introduces input-dependent state transitions. This yields an additional convolutional kernel capturing input correlations, improving generalization across long-range sequence tasks.