SE(3)-Transformers: Equivariant Attention for 3D Data
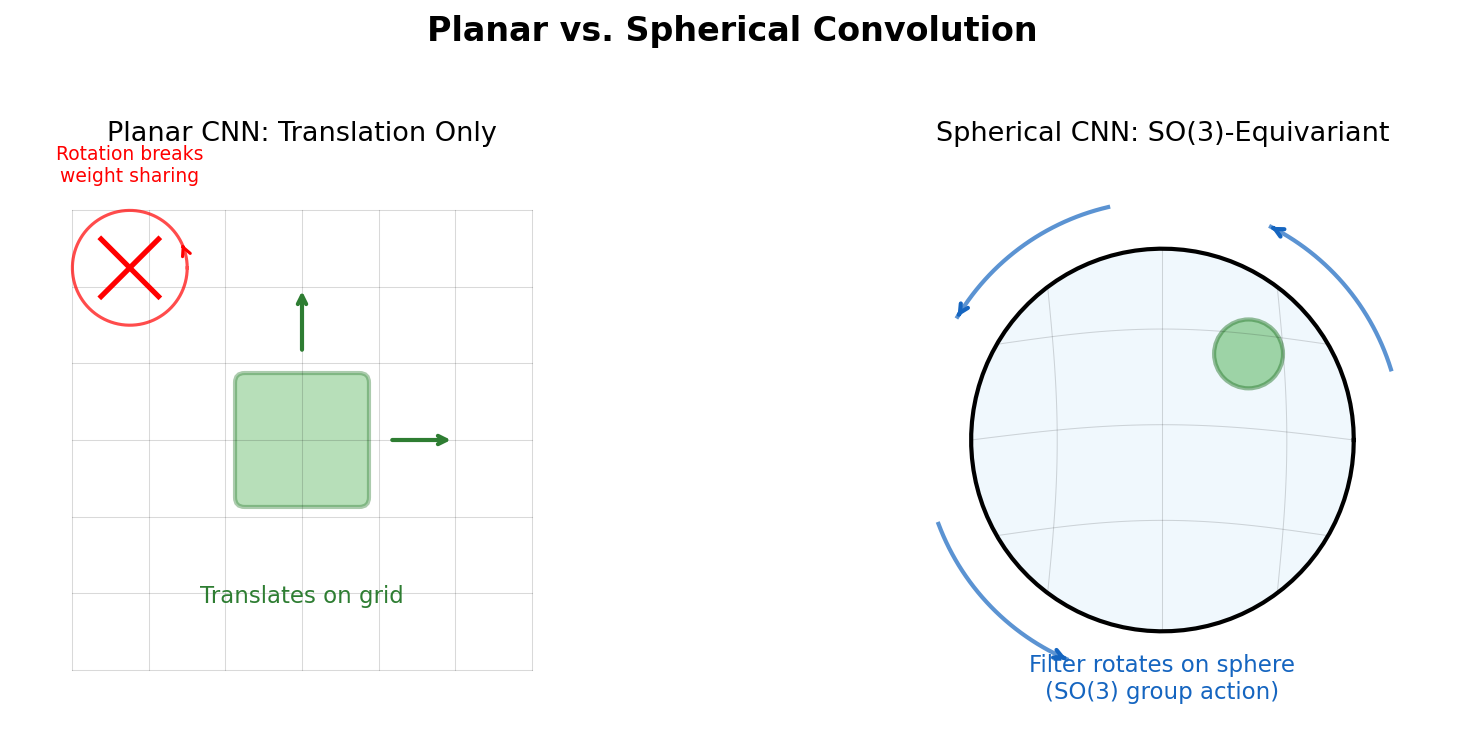
Fuchs et al. introduce the SE(3)-Transformer, which combines self-attention with SE(3)-equivariance for 3D point clouds and graphs. Invariant attention weights modulate equivariant value messages from tensor field networks, resolving angular filter constraints while enabling data-adaptive, anisotropic processing.