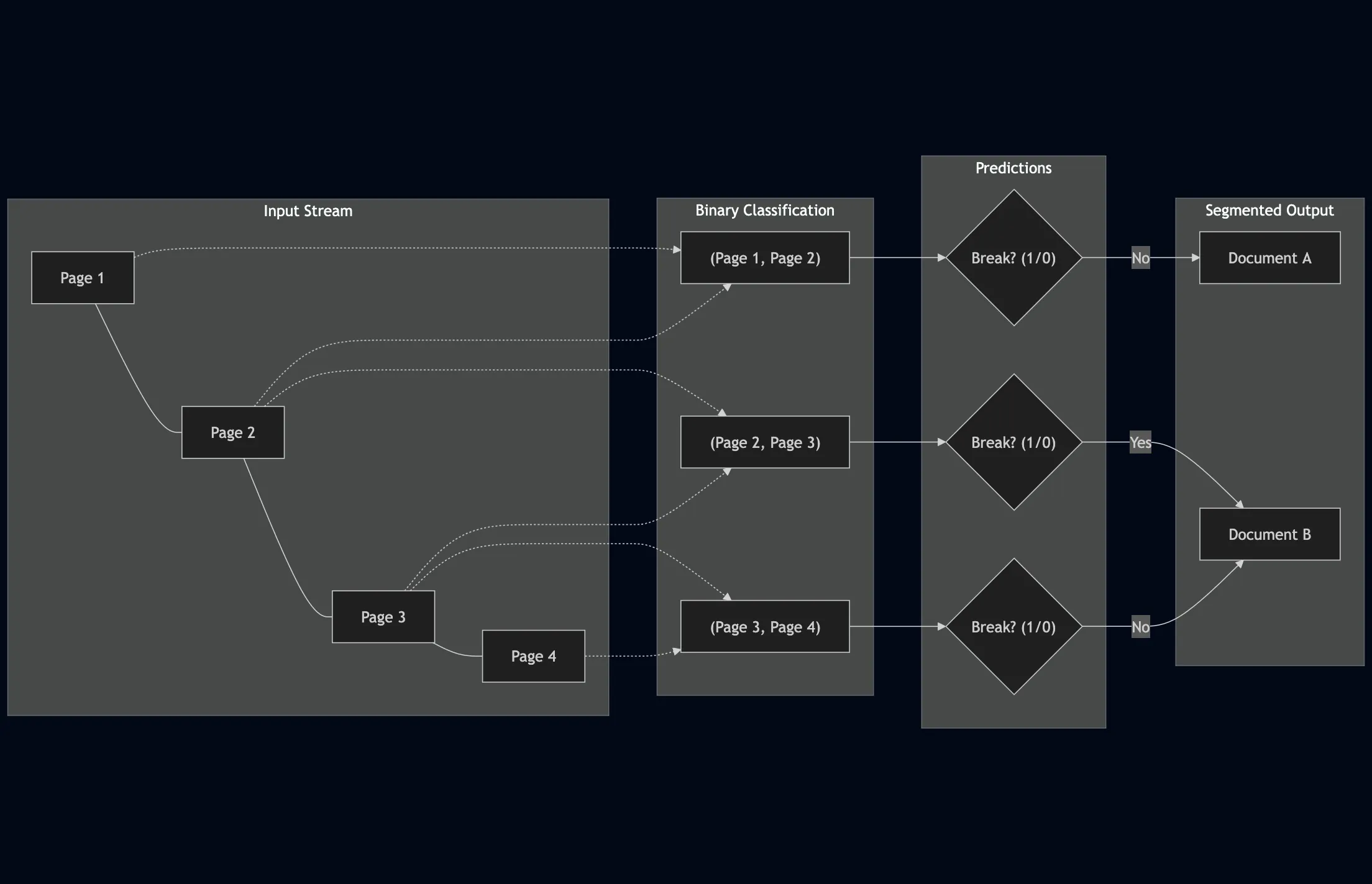
LLMs for Page Stream Segmentation
Enhanced TabMe benchmark for page stream segmentation, creating TabMe++, showing fine-tuned decoder-based LLMs …...
Enhanced TabMe benchmark for page stream segmentation, creating TabMe++, showing fine-tuned decoder-based LLMs …...
A production-grade implementation of Hierarchical Softmax and Negative Sampling, featuring vectorized tree traversals, …...
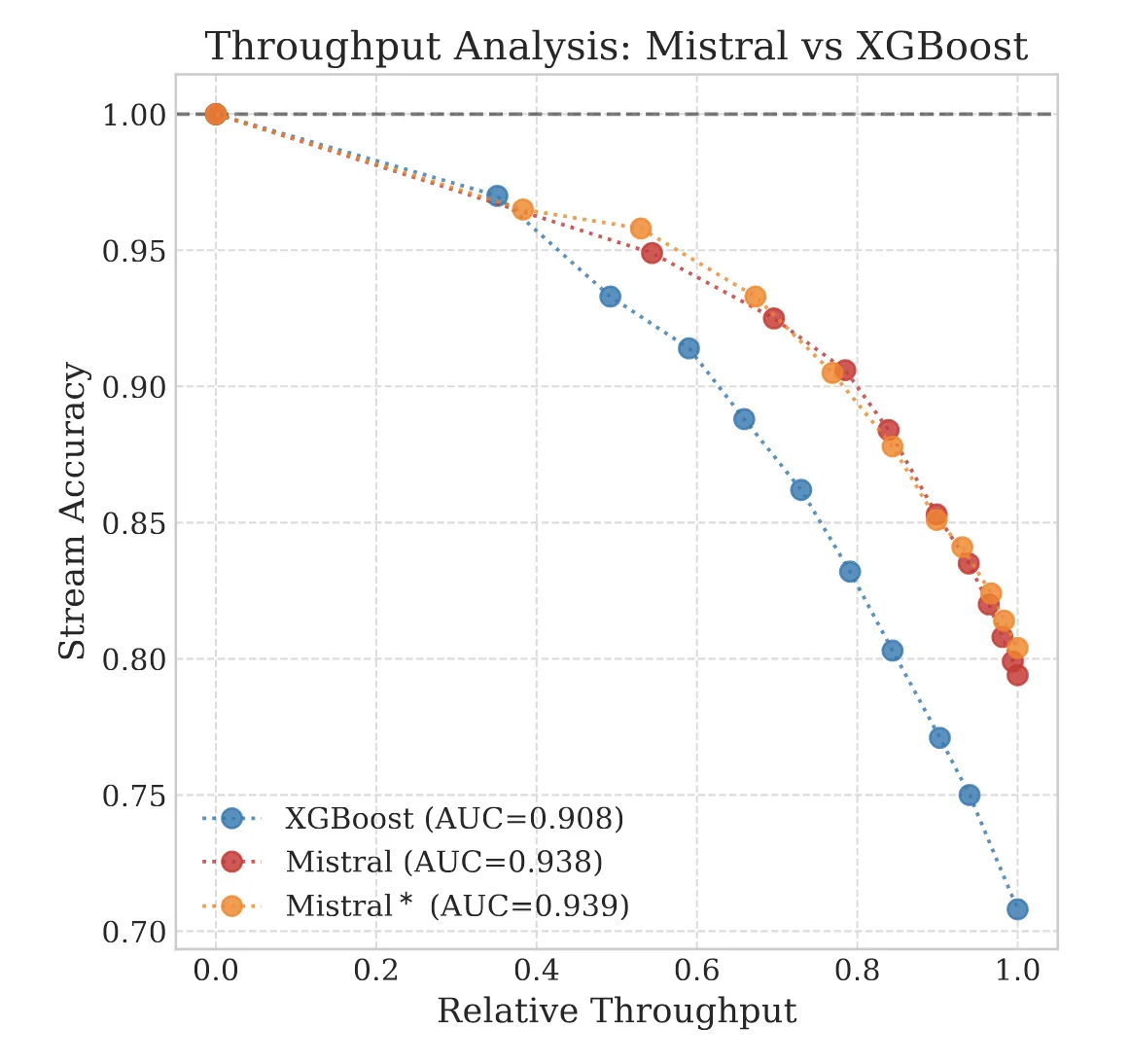
LLM applications for insurance document automation using parameter-efficient fine-tuning and analysis of calibration …...
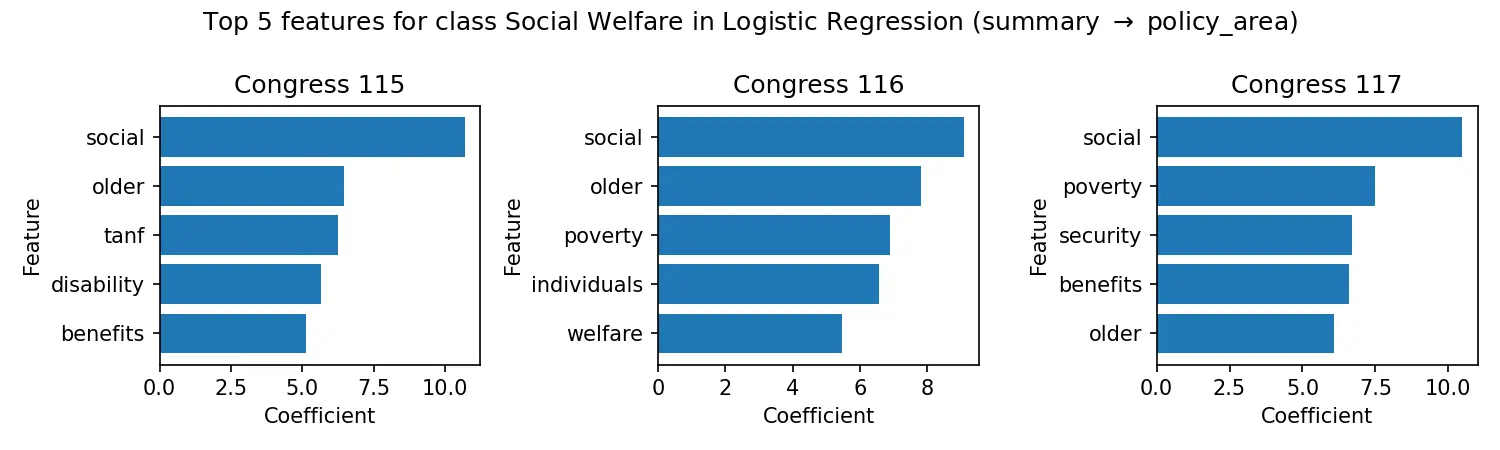
Constructed a 47,000+ bill legislative knowledge graph from Congress.gov, capturing sponsor networks and committee …...
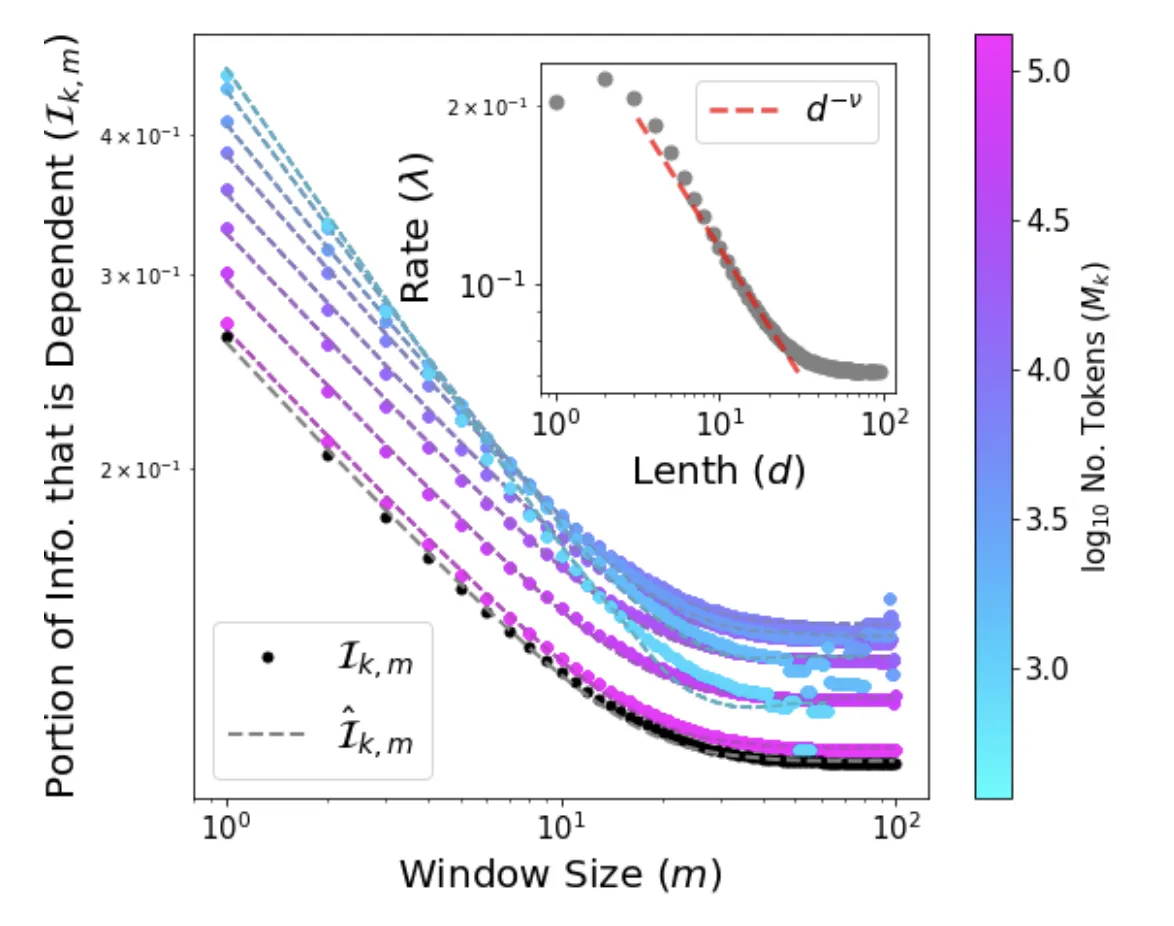
Analytical derivation of Word2Vec's softmax objective factorization and a new framework for detecting semantic bias in …...
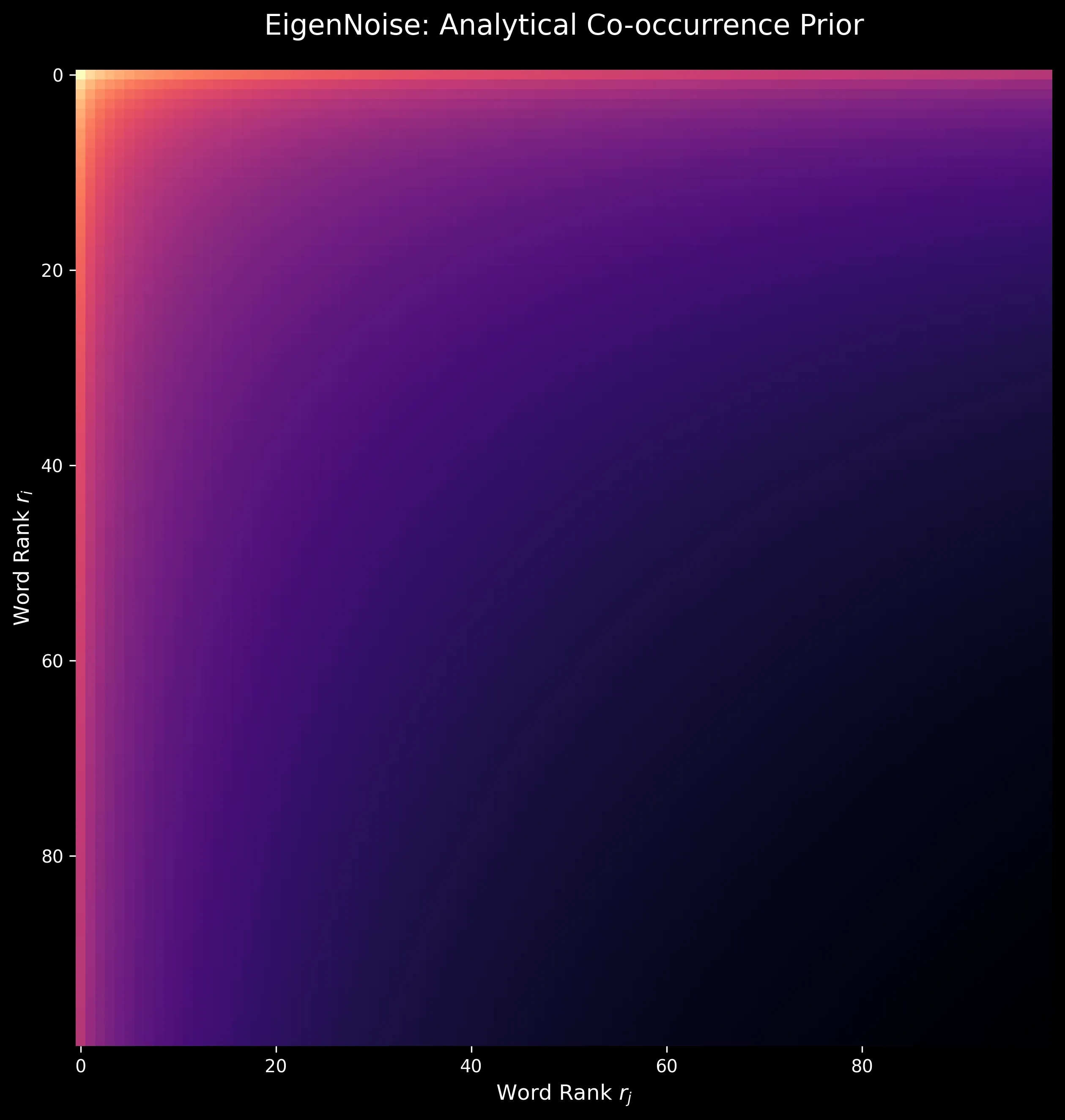
Investigation into EigenNoise, a data-free initialization scheme for word vectors that approaches pre-trained model …...

A comprehensive study on cross-platform social media analysis, introducing the PyConversations library and a unified …...
Undergraduate thesis exploring representation learning for social media text and developing tools for cross-platform …

Investigation into whether universal adversarial triggers can control both topic and stance of GPT-2's generated text …...
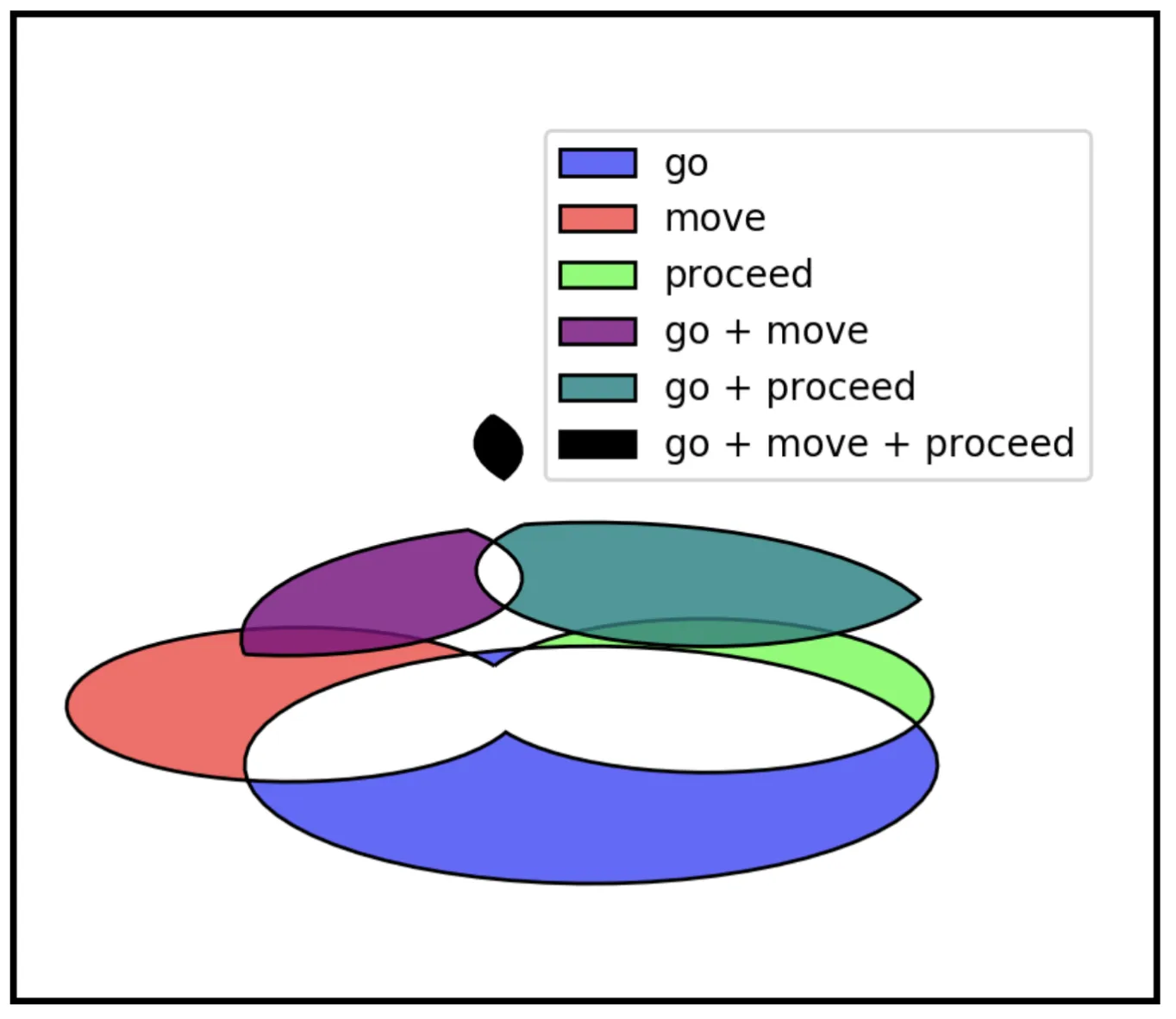
We introduce an unsupervised algorithm for inducing semantic networks from noisy, crowd-sourced data, producing a …...
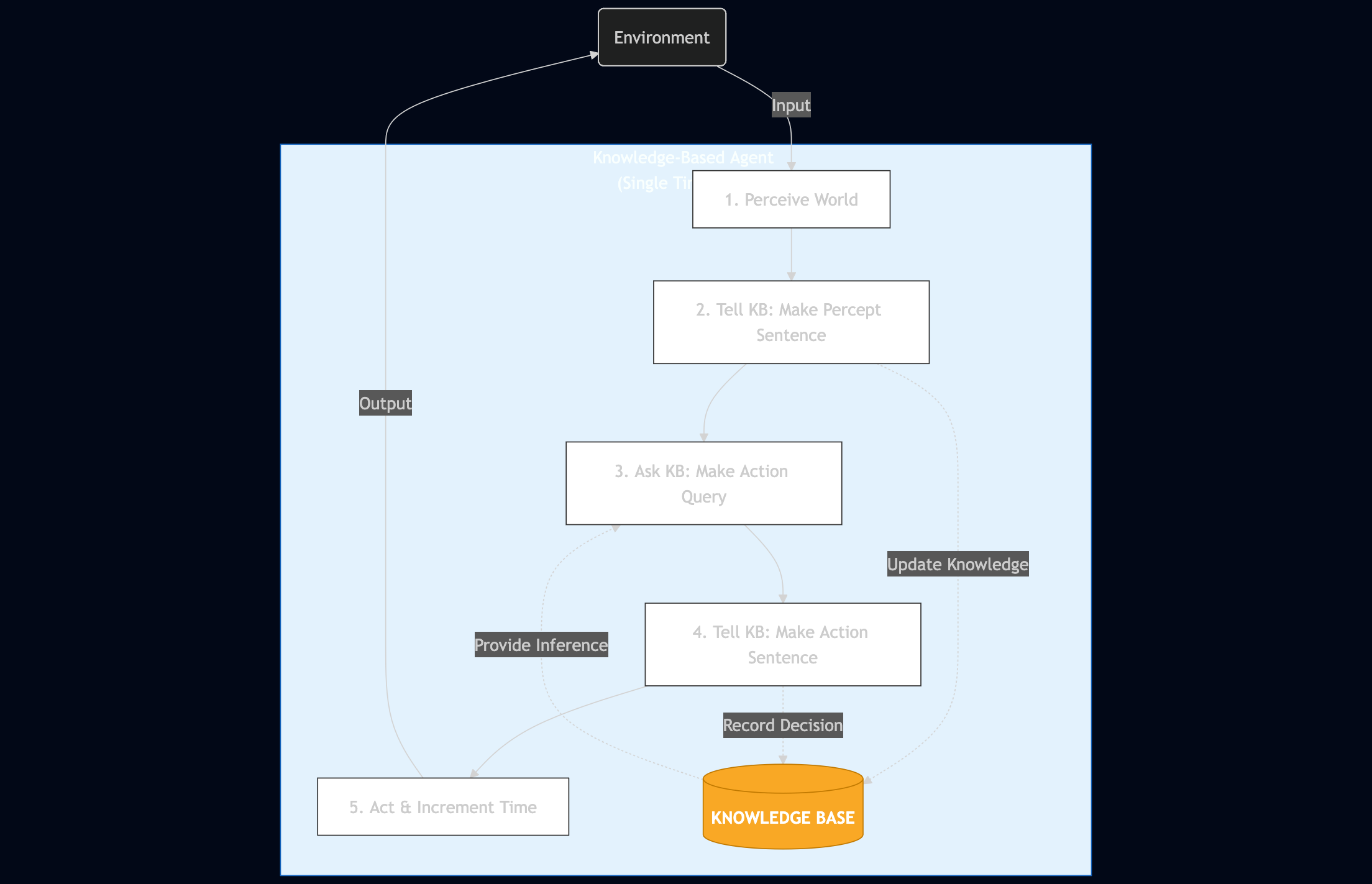
Learn about knowledge-based agents: how AI systems use knowledge bases, reasoning, and inference to build intelligent …

Analysis of QuAC's conversational QA through student-teacher interactions, featuring 100K+ context-dependent questions …