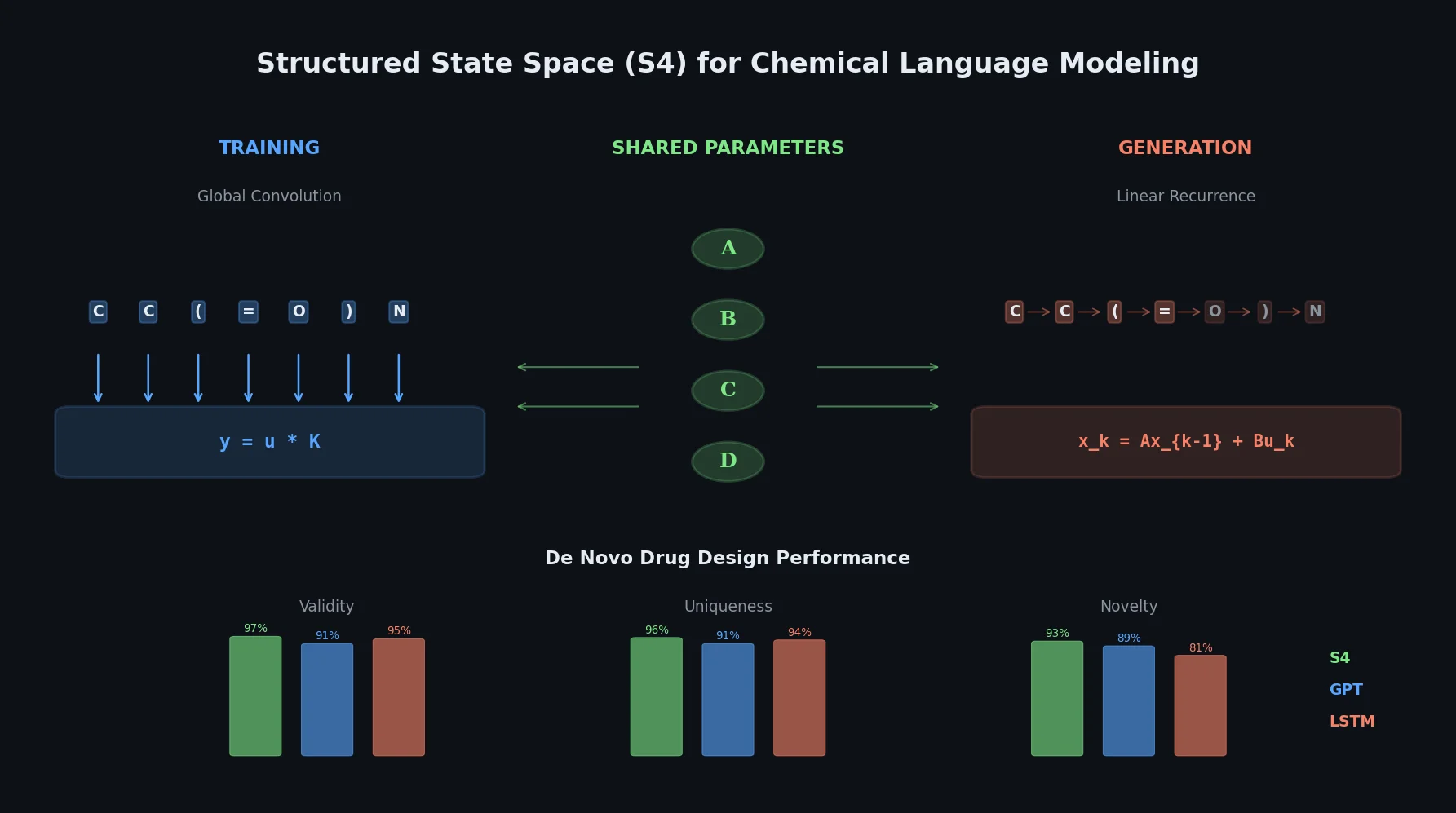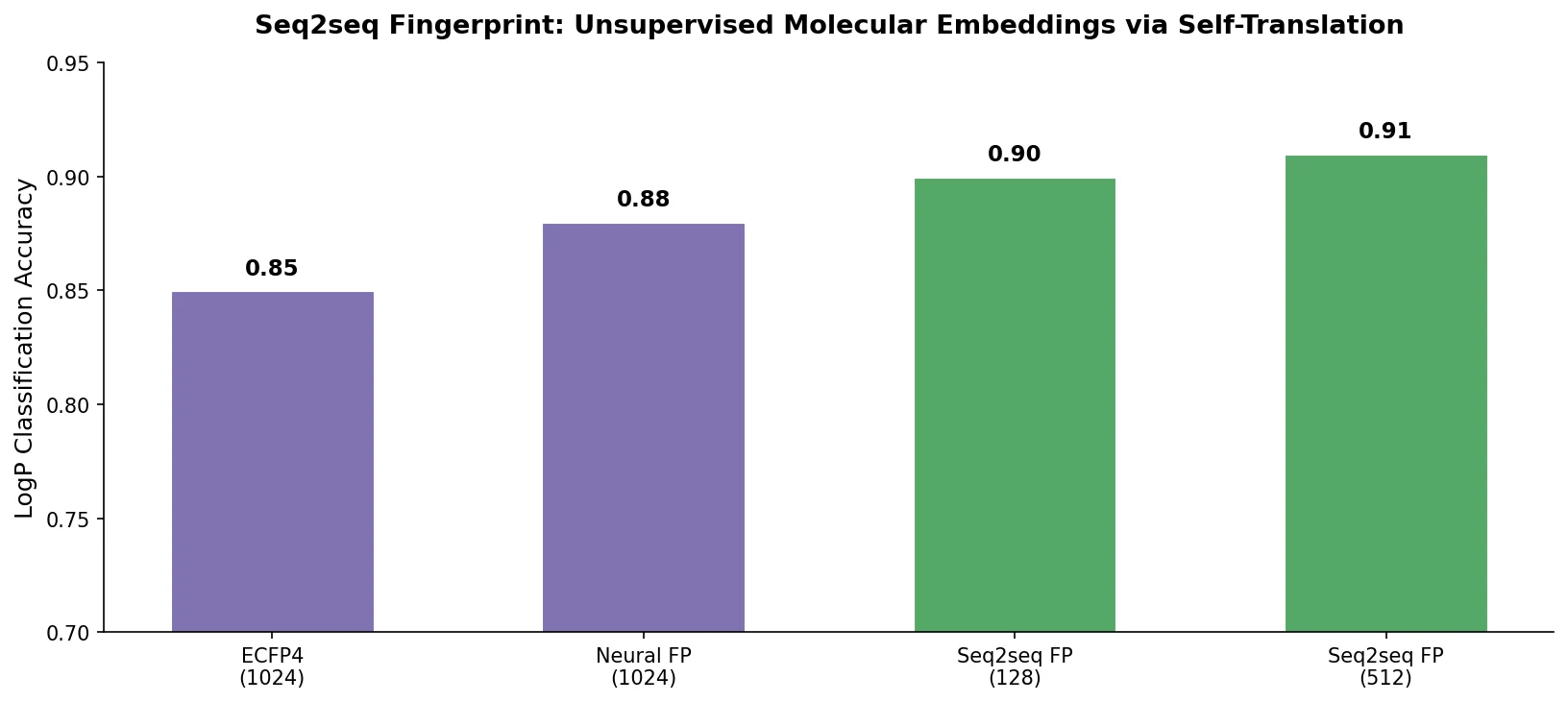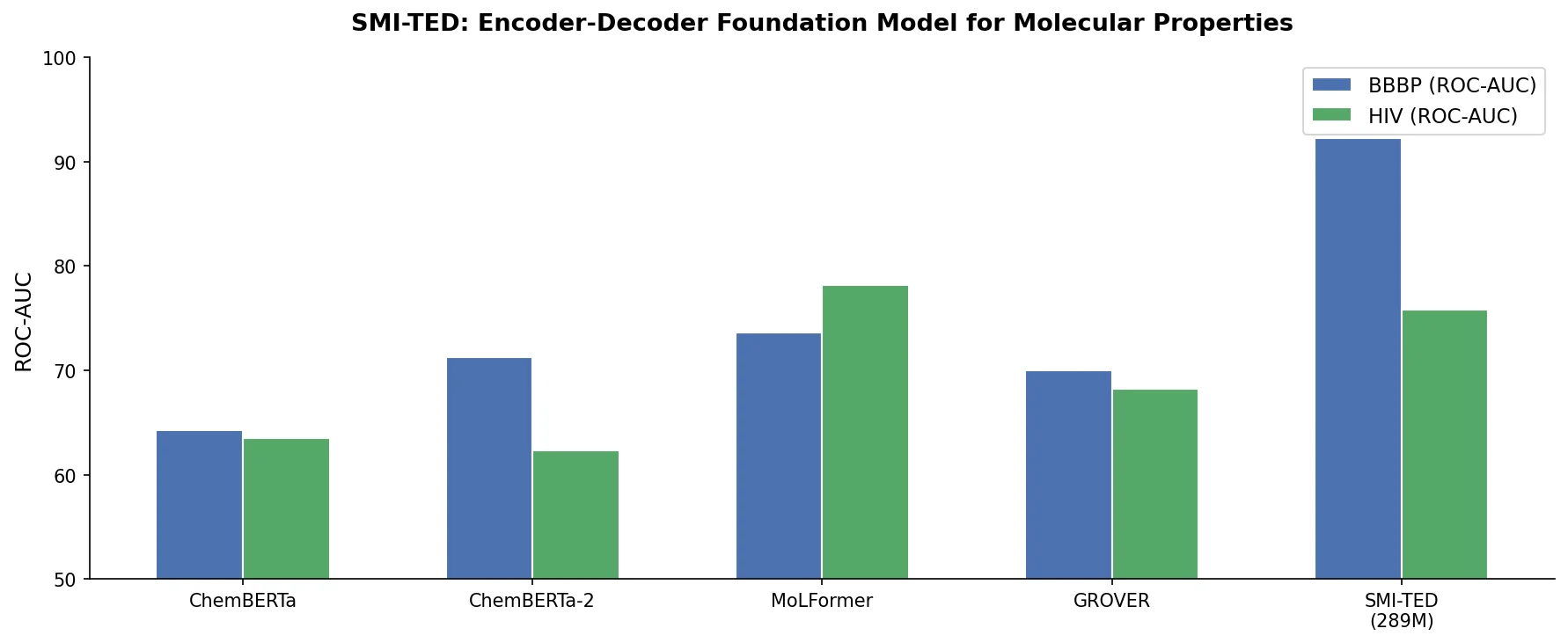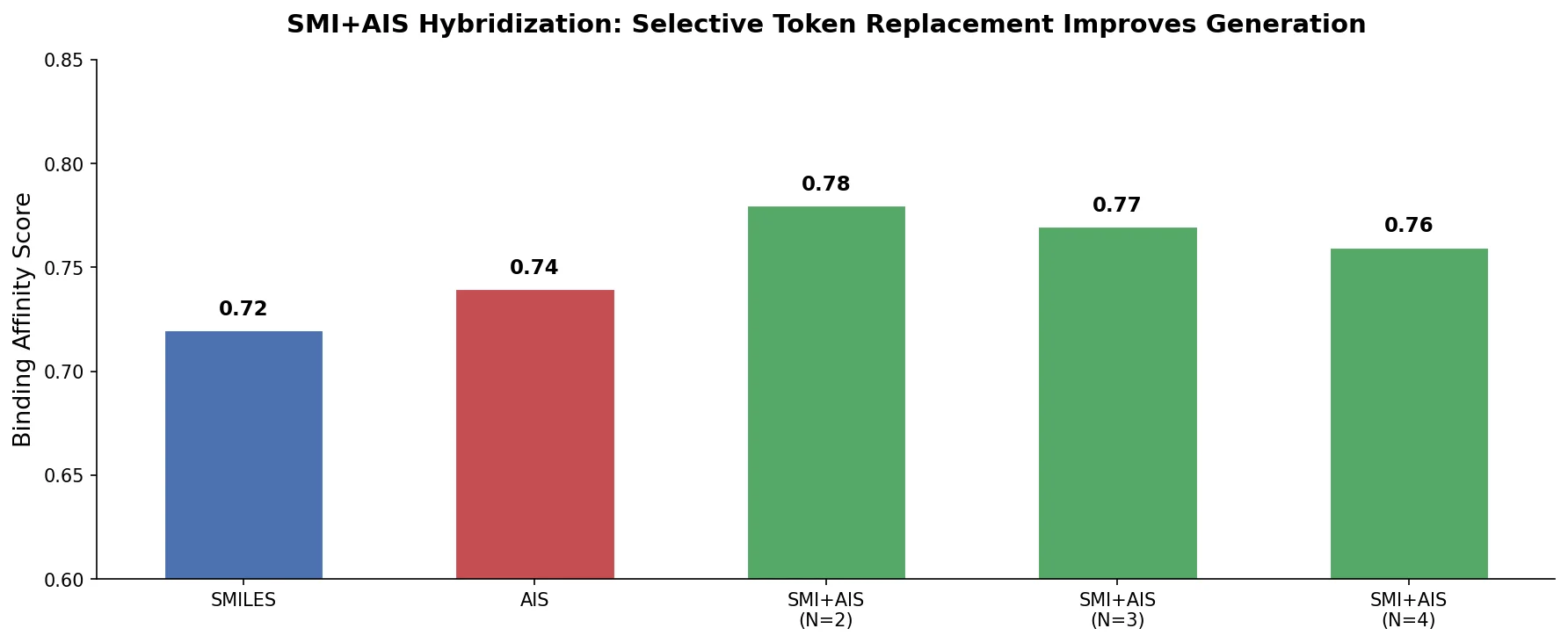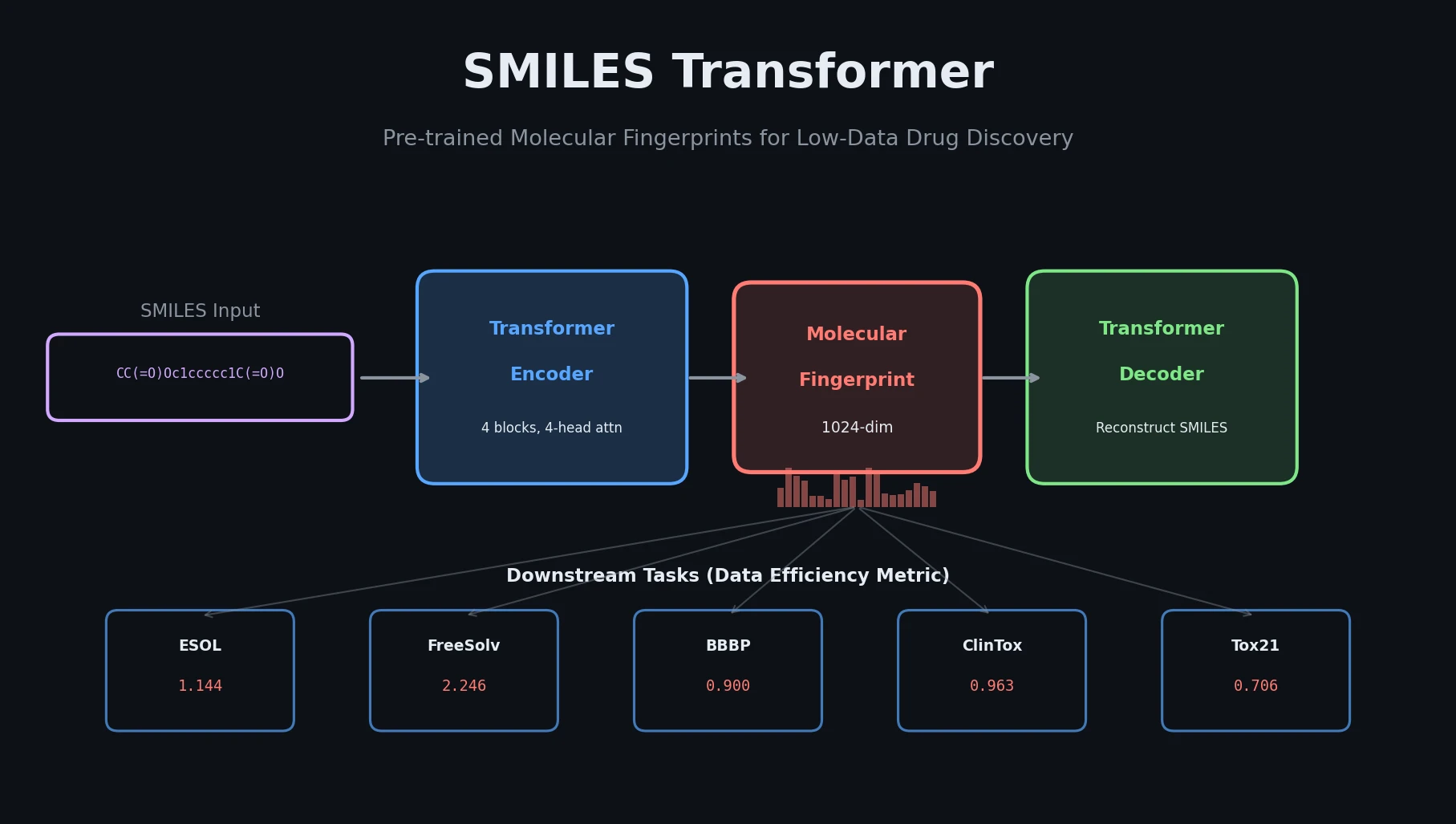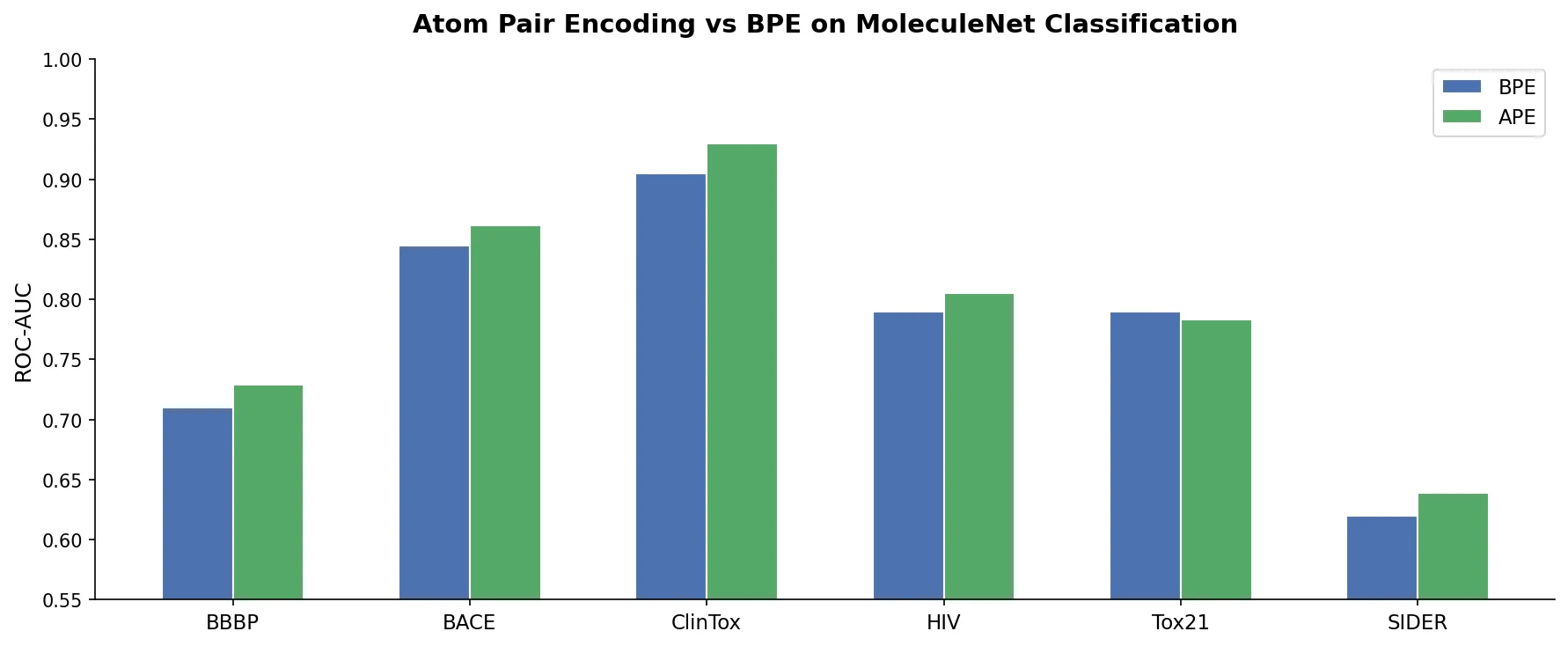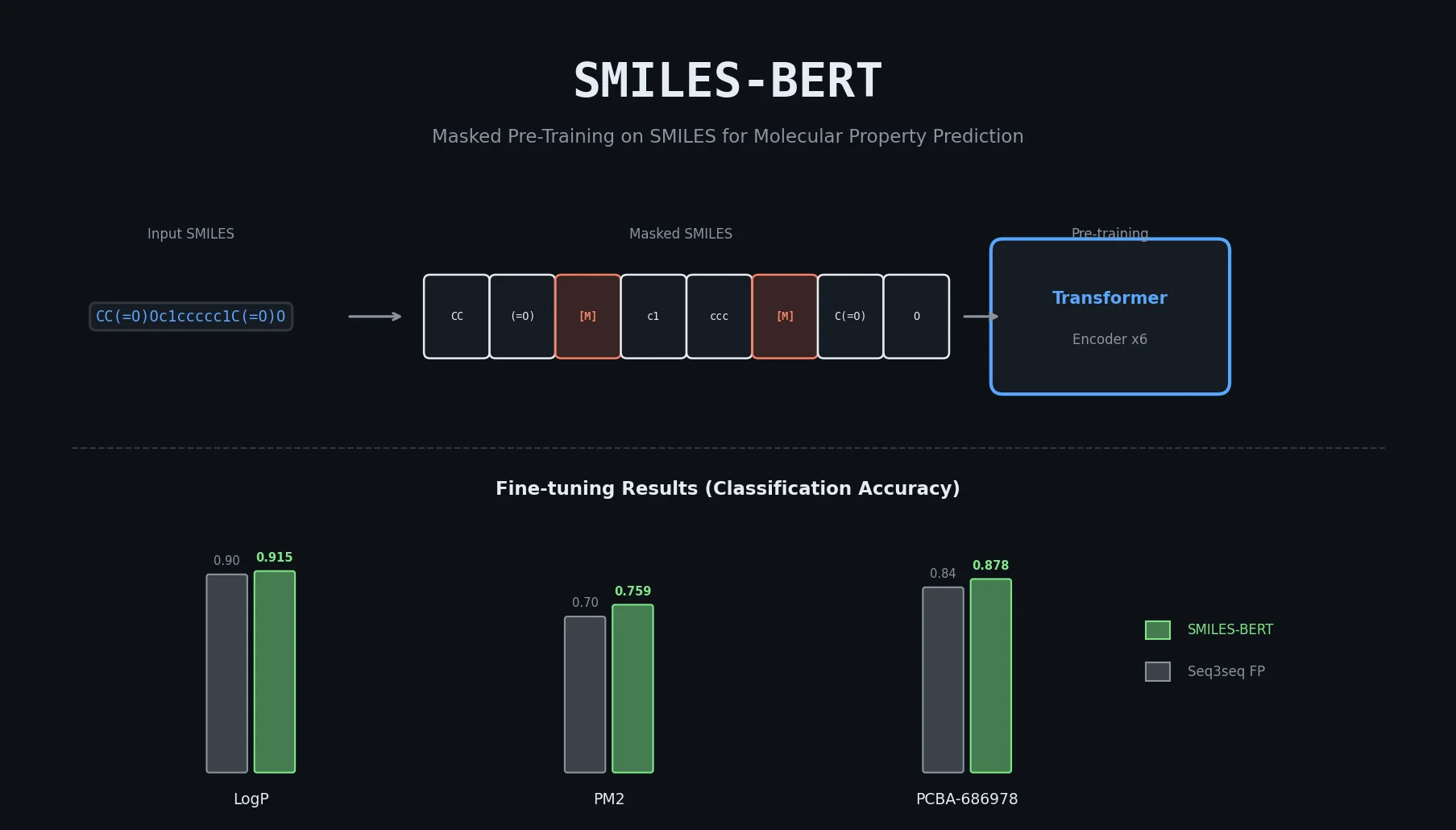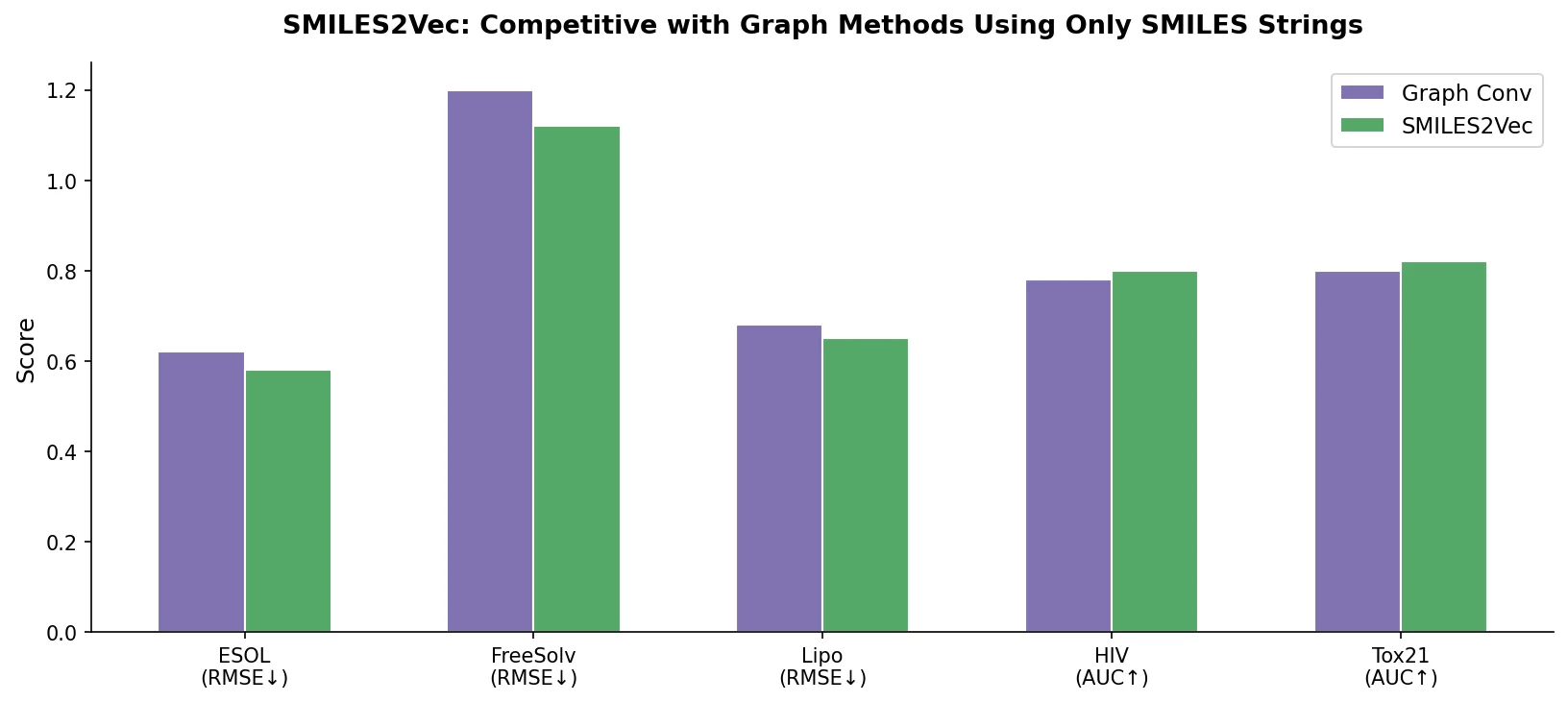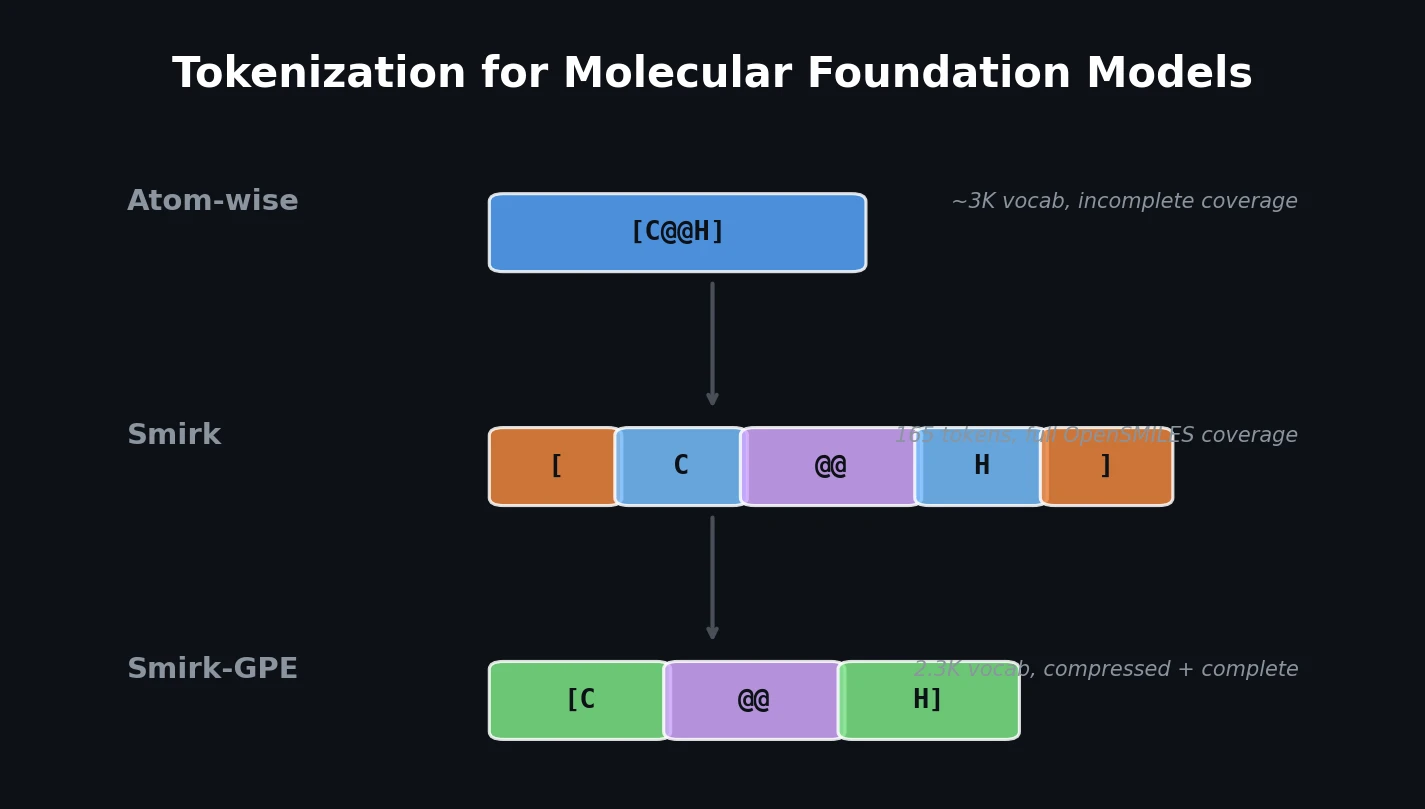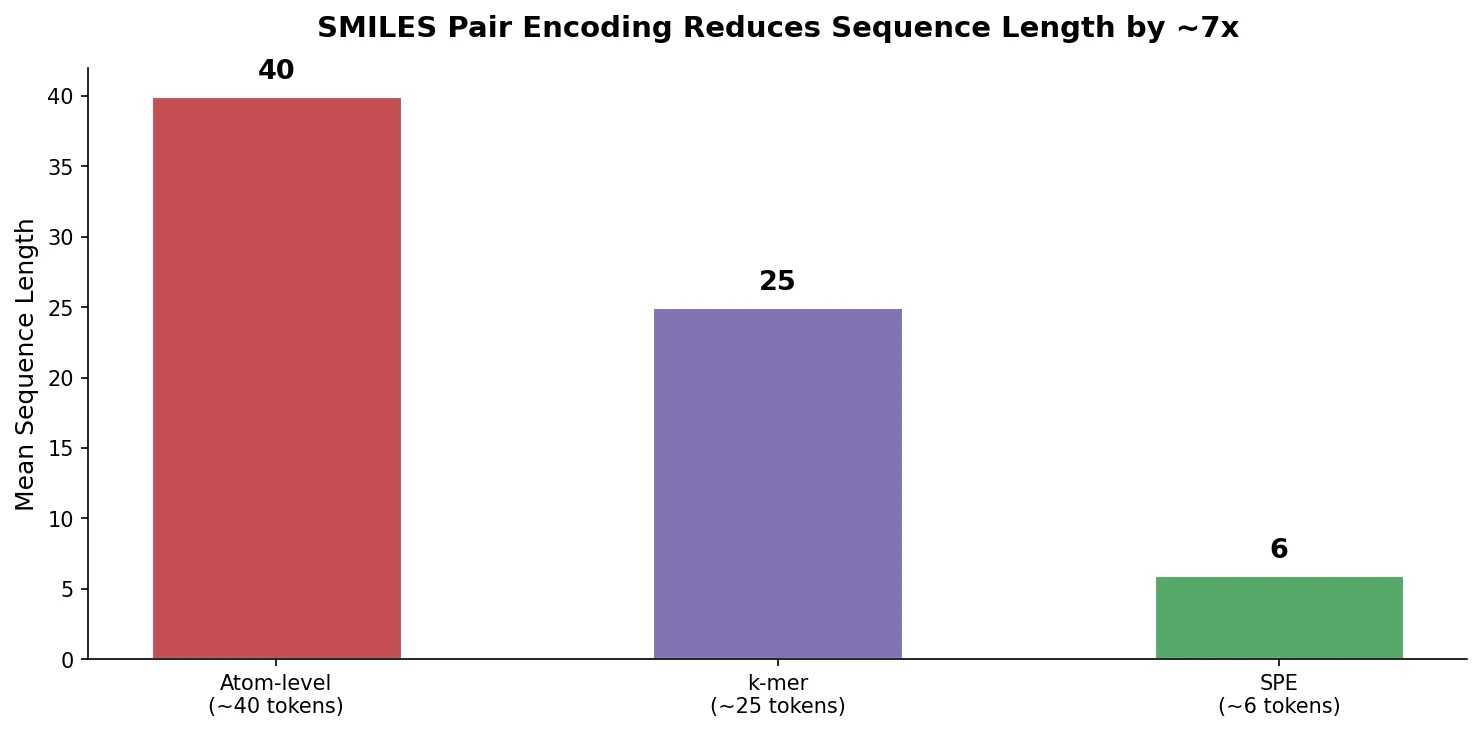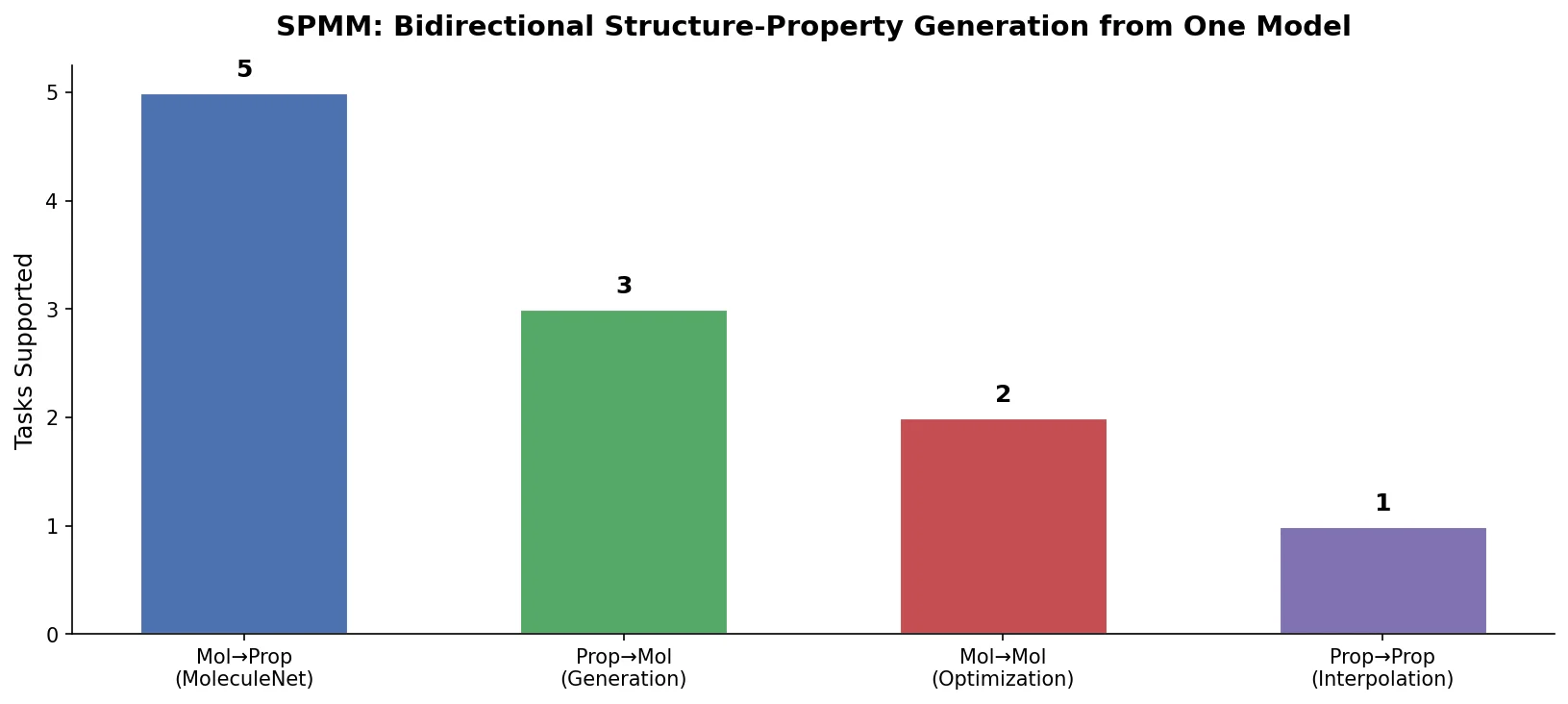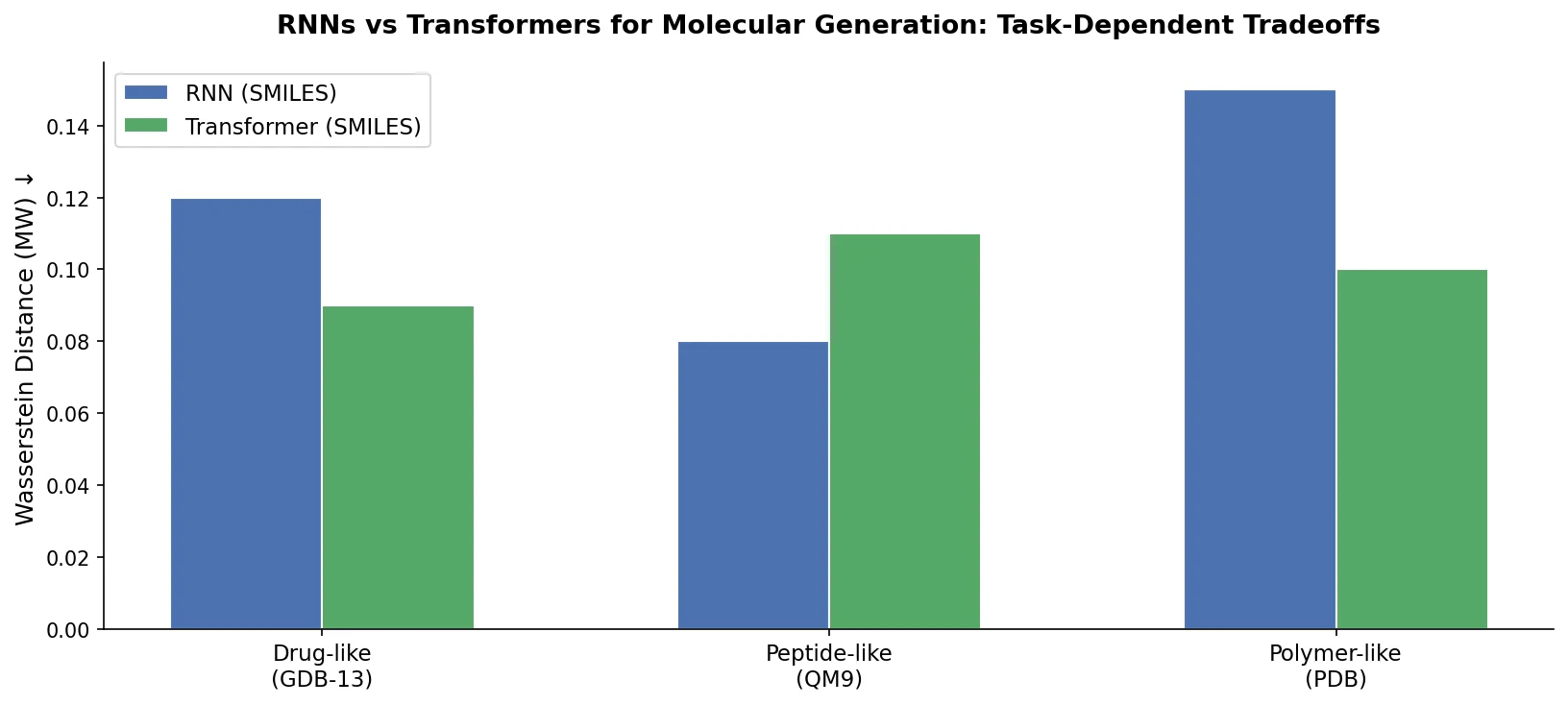
RNNs vs Transformers for Molecular Generation Tasks
Compares RNN-based and Transformer-based chemical language models across three molecular generation tasks of increasing complexity, finding that RNNs excel at local features while Transformers handle large molecules better.