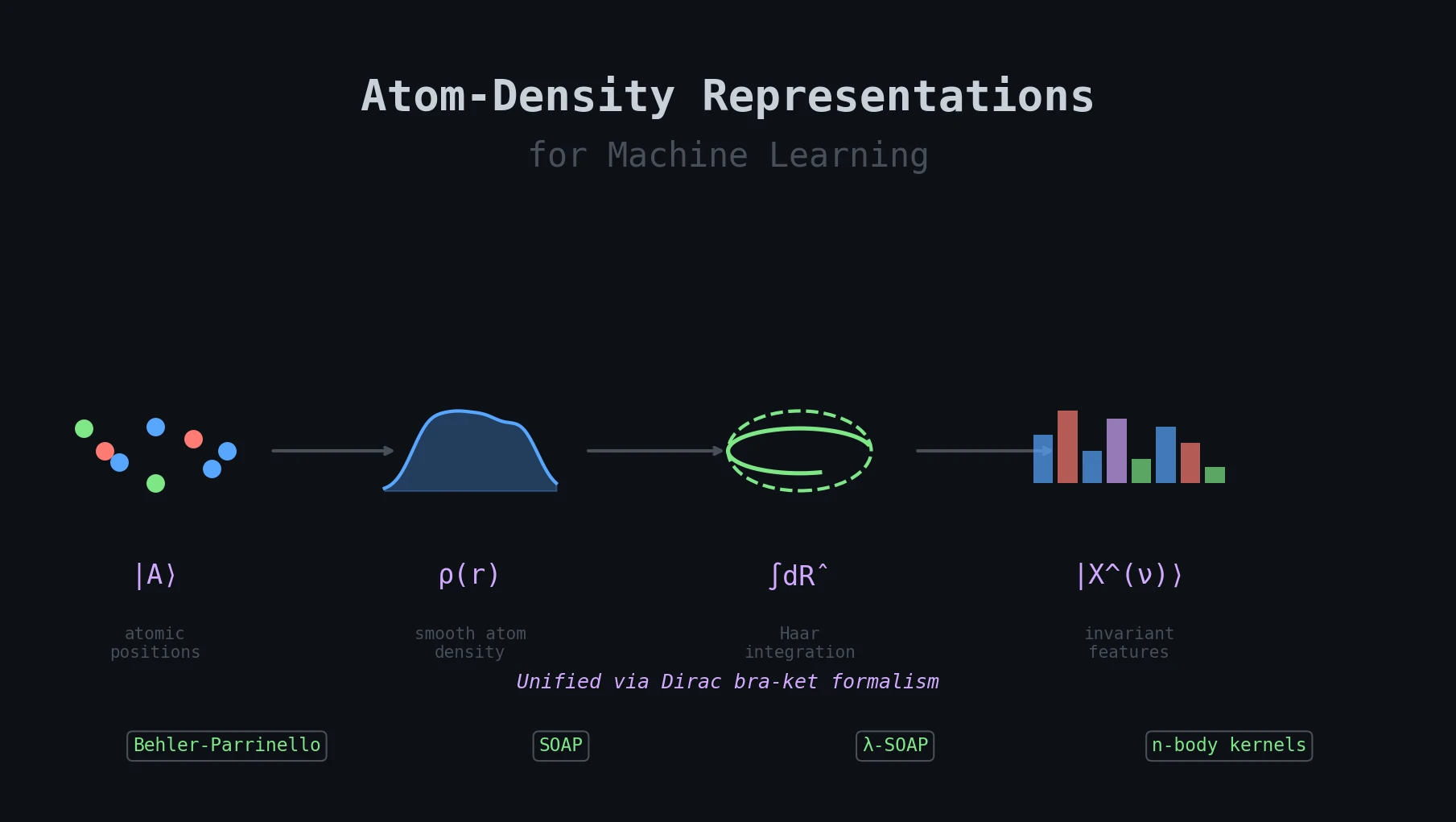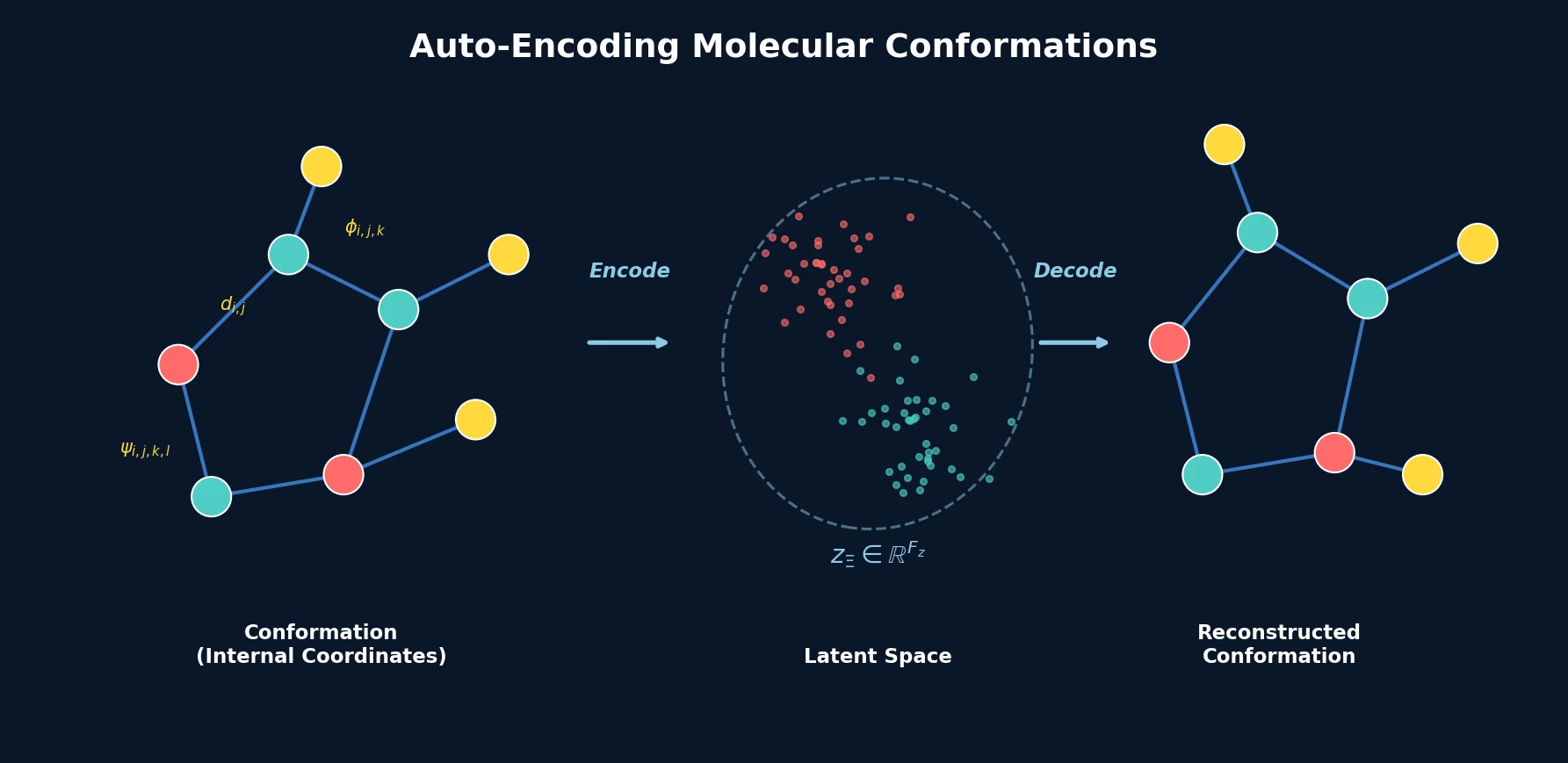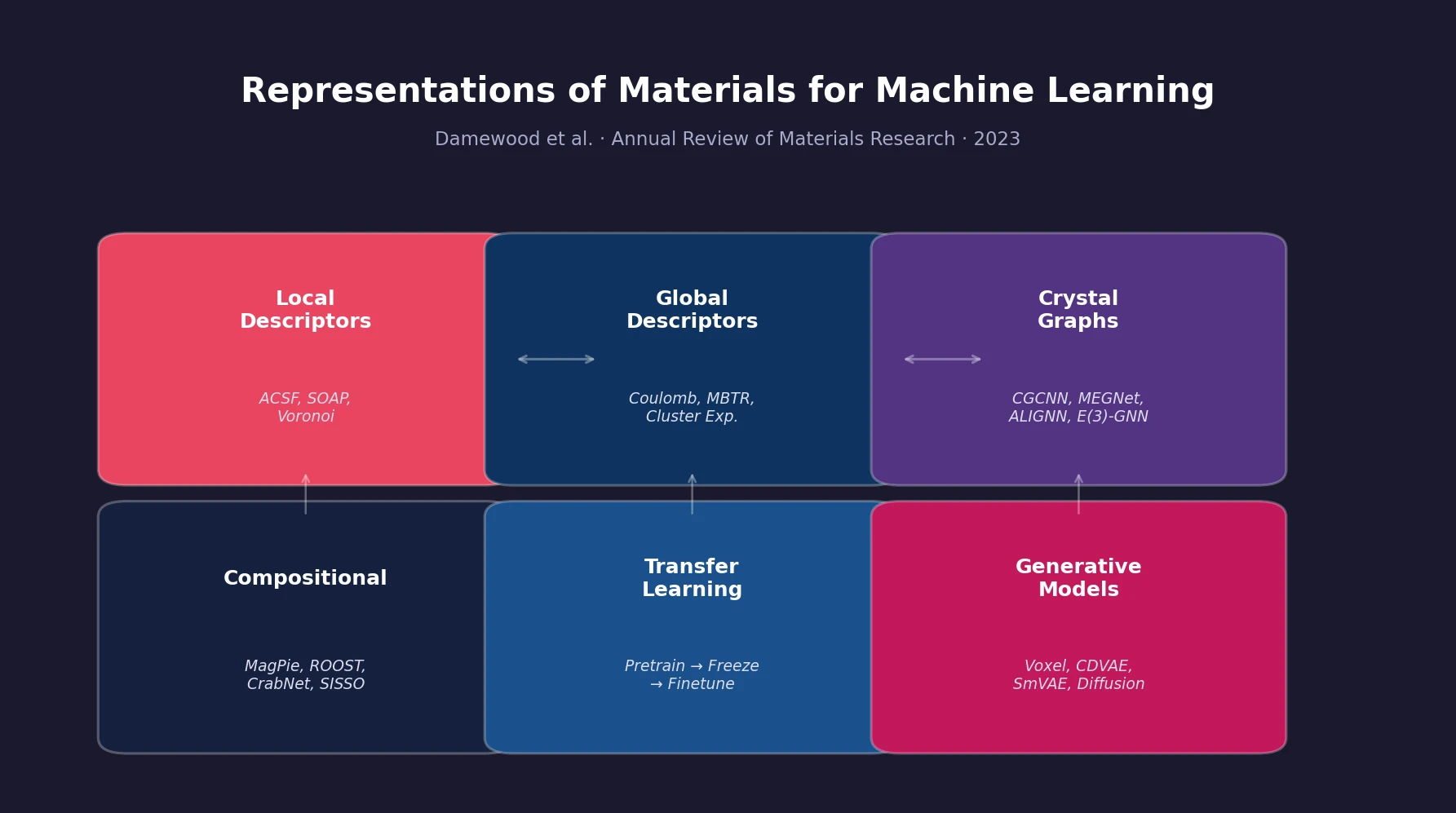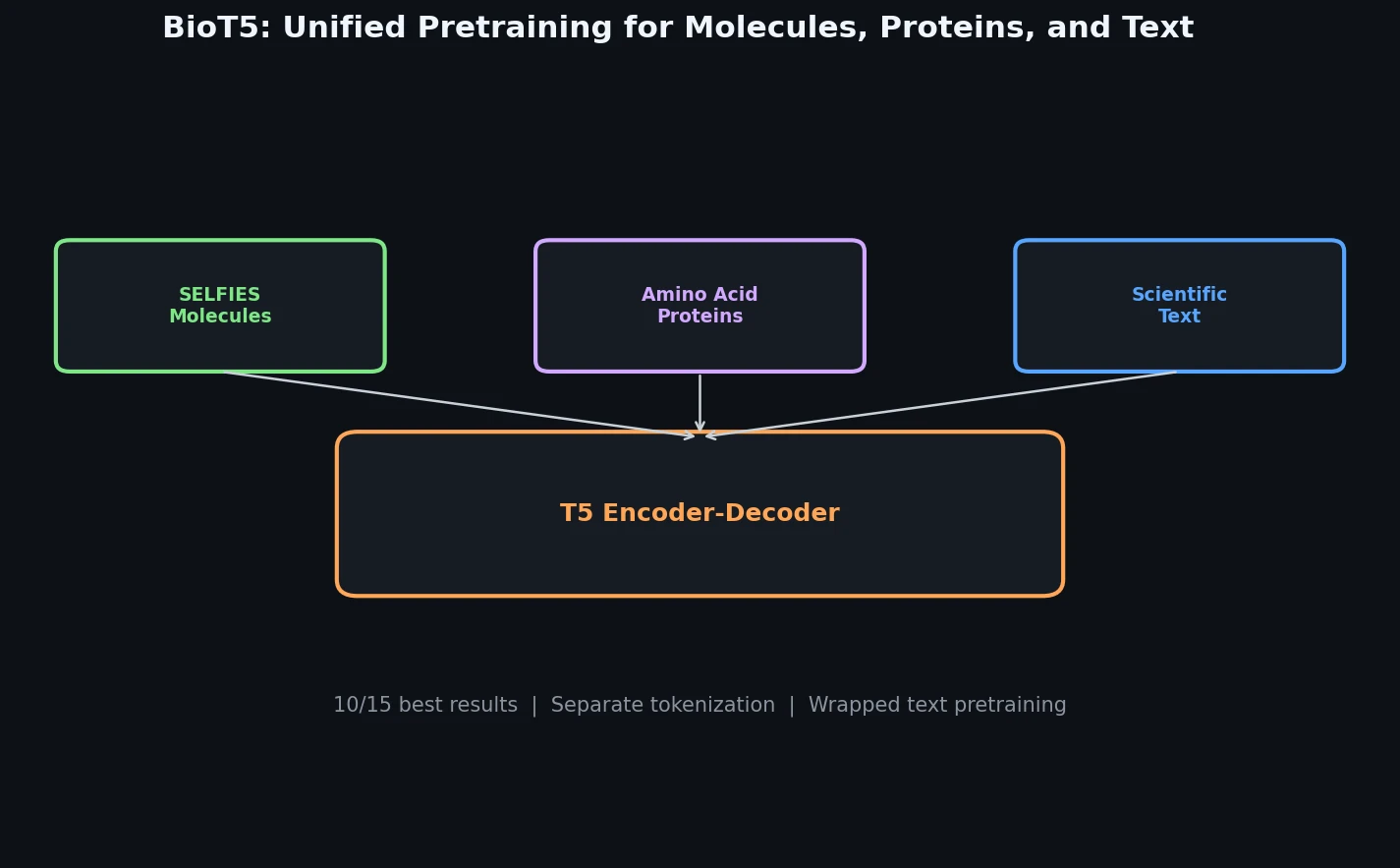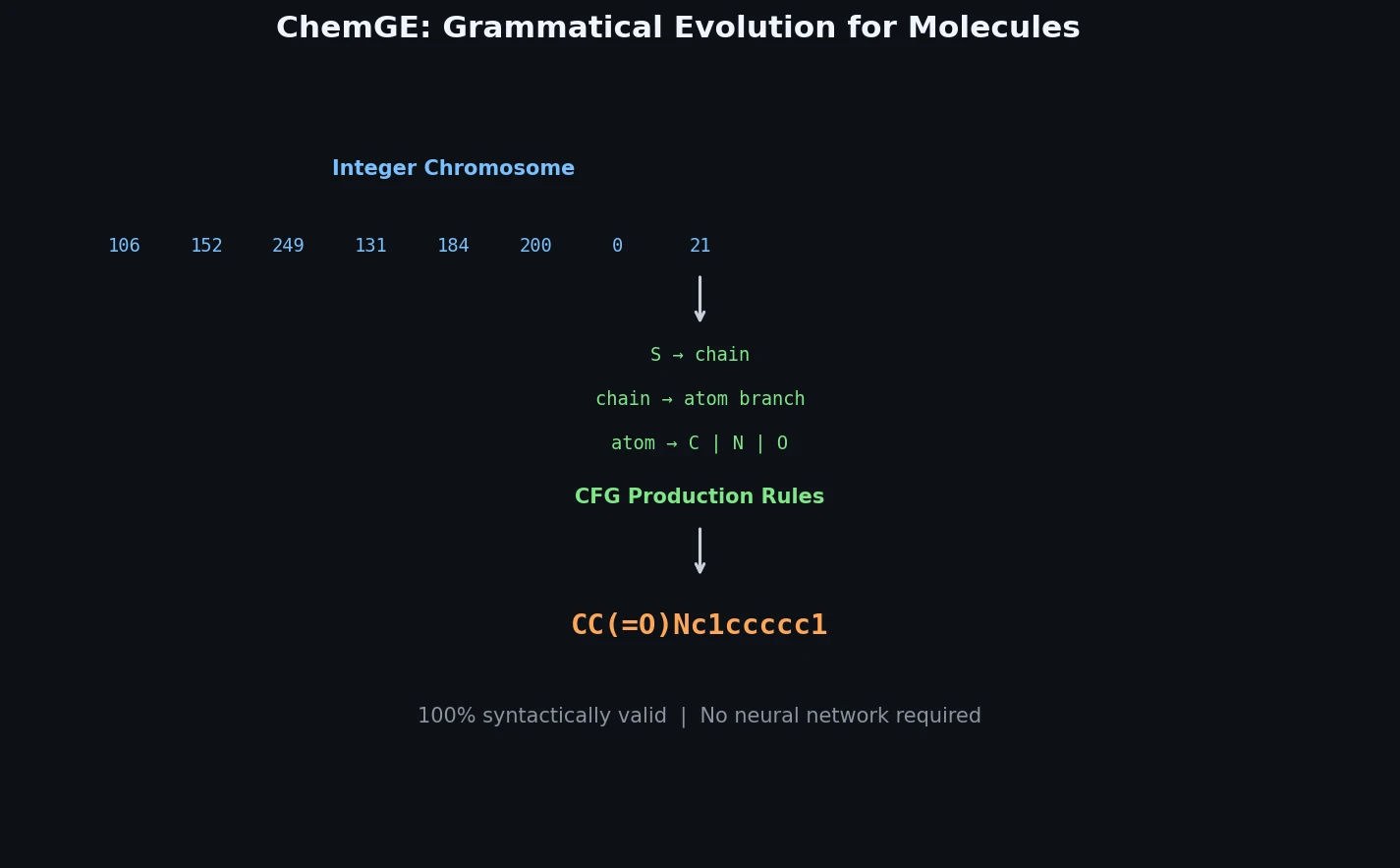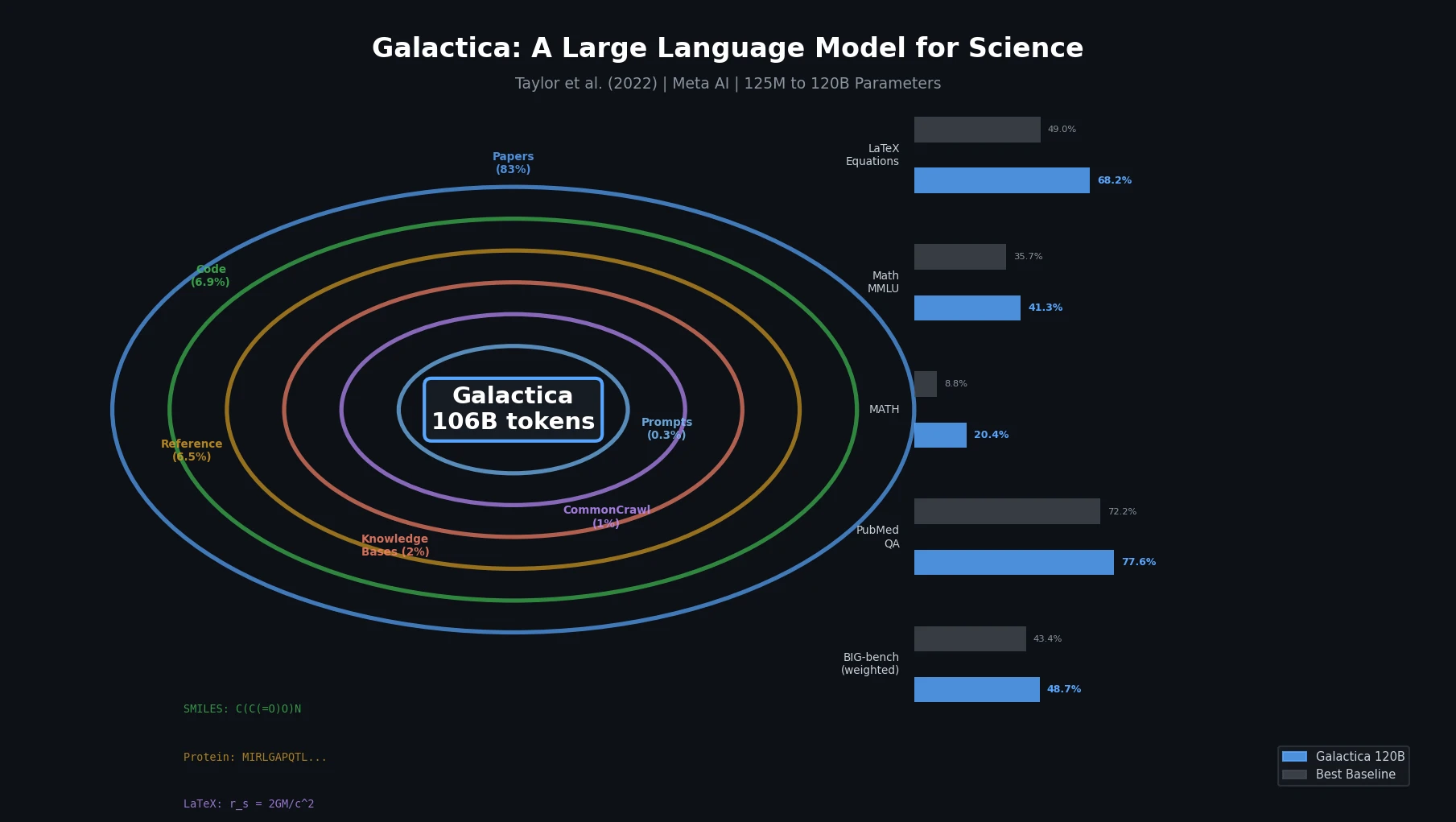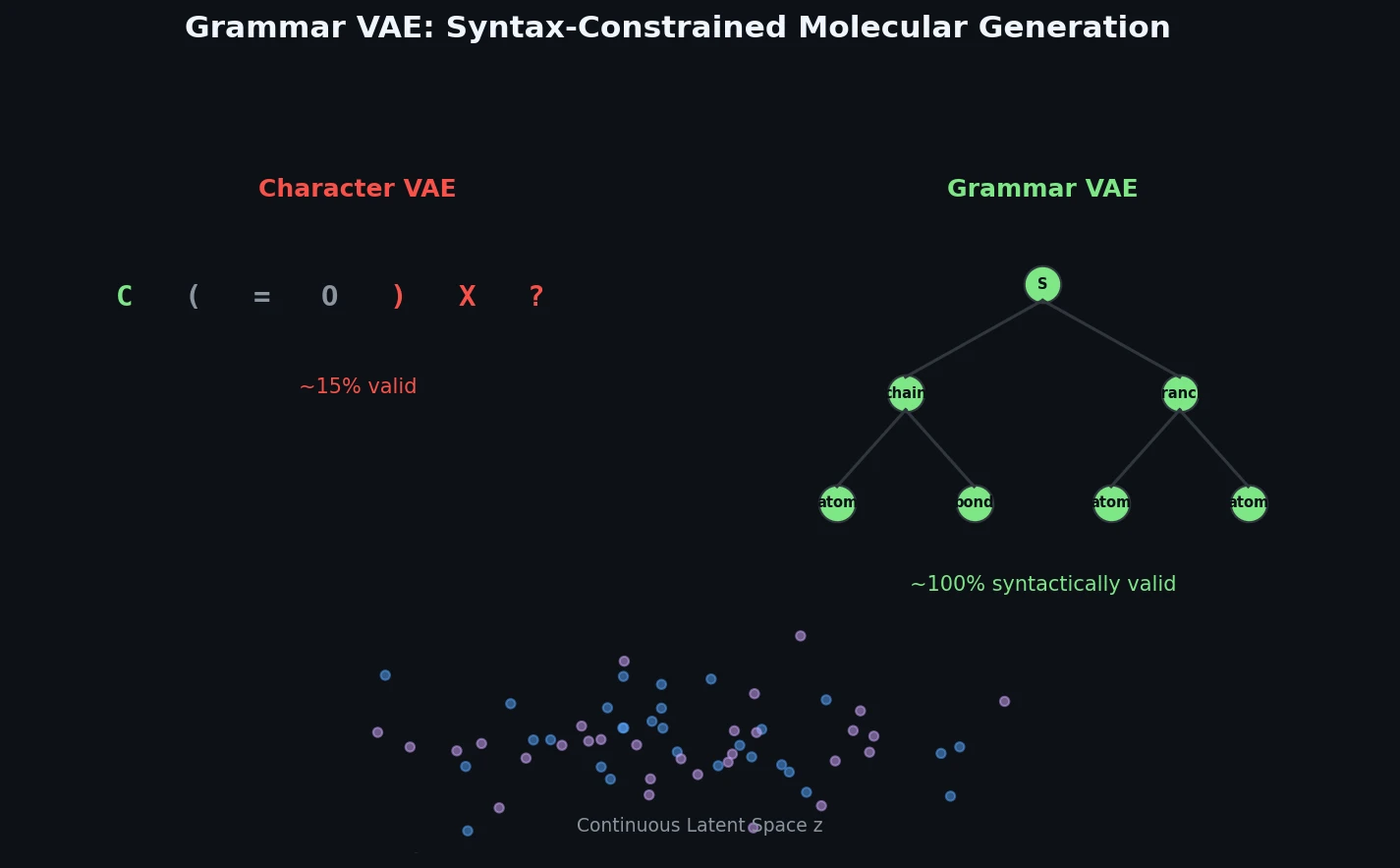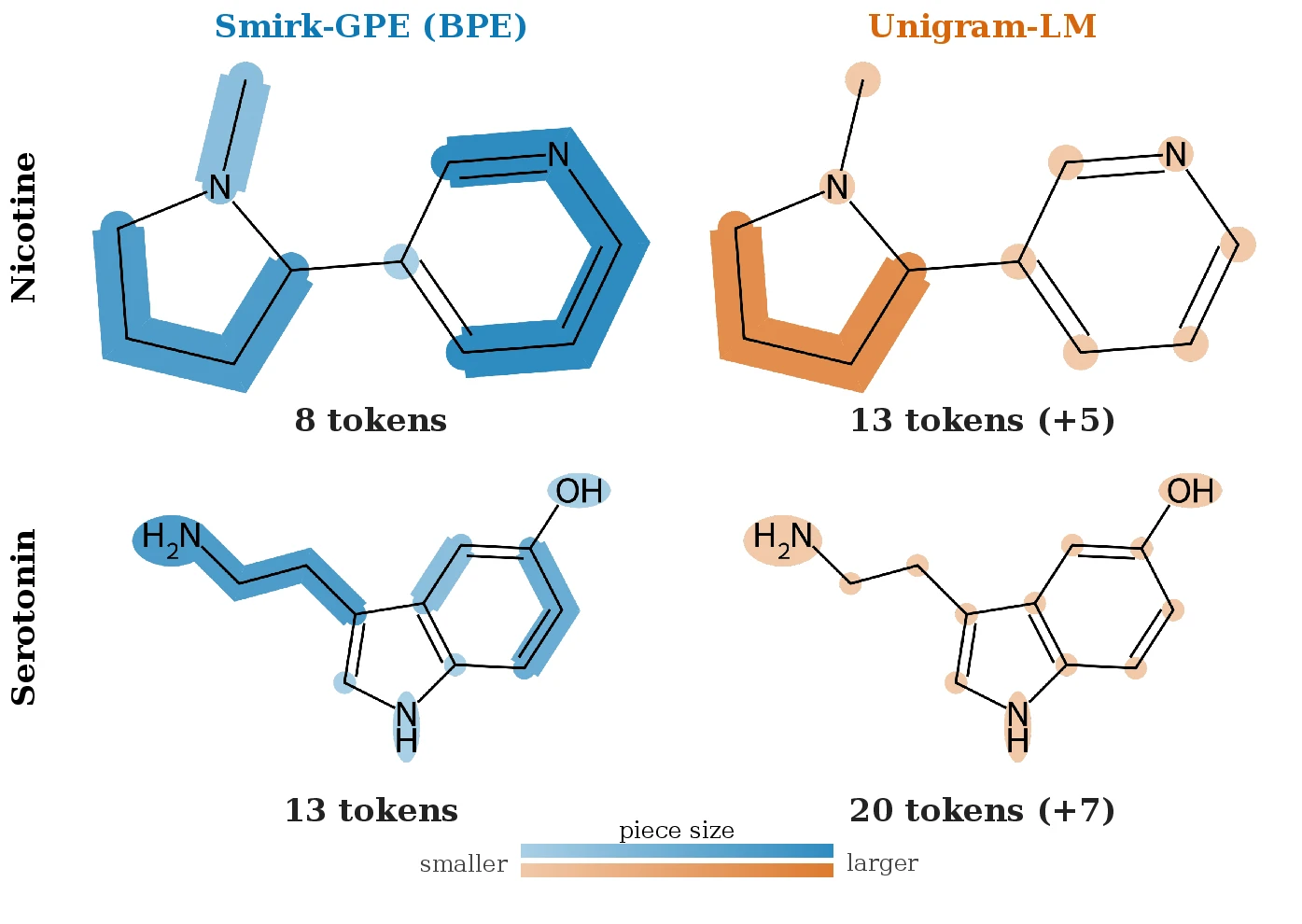
Where to Cut, How Deep: BPE and Unigram-LM on SMILES
A controlled comparison of BPE and Unigram-LM over a fixed chemistry SMILES glyph base. Across 22 matched conditions the two build near-disjoint subword vocabularies, so the subword algorithm is a modeling decision rather than a free default.