GEOM Dataset: 3D Molecular Conformer Generation
Get a practical overview of the GEOM dataset and learn how it’s advancing 3D molecular machine learning by bridging static graphs and dynamic reality.
Get a practical overview of the GEOM dataset and learn how it’s advancing 3D molecular machine learning by bridging static graphs and dynamic reality.
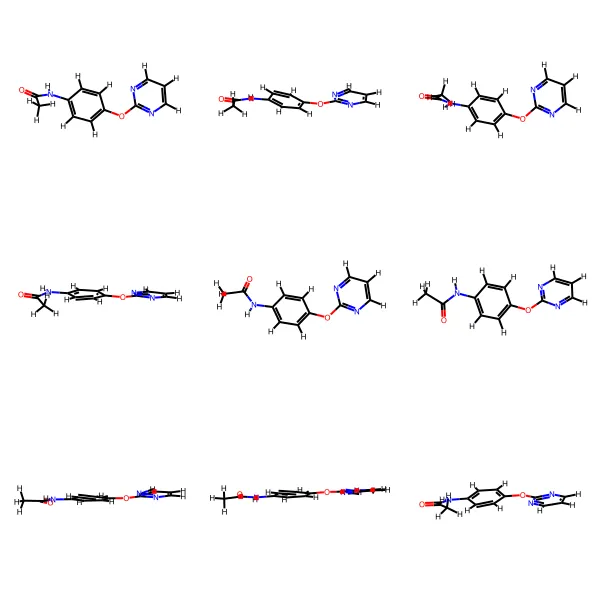
An end-to-end data factory for molecular machine learning that transforms raw chemical formulas (e.g., C6H14) into labeled 3D conformer datasets, using MAYGEN for structural isomer enumeration, RDKit for 3D embedding, and physics-based featurization to address data scarcity in computational drug discovery.
What happens when you achieve 99.8% accuracy on sarcasm detection? You might have accidentally built a domain classifier. A cautionary ML tale about dataset bias.
Only 2% of congressional bills become law. We analyze 15K bills from 2021-2023 to understand what drives legislative success and failure.

Step-by-step LAMMPS tutorial for simulating copper and platinum adatom diffusion. Learn surface dynamics simulation, trajectory analysis, and how atomic mass affects diffusion for machine learning datasets.
A practical guide to simulating mini-proteins using GROMACS; from alanine dipeptide to tryptophan systems for ML training data generation.
An automated GROMACS pipeline for generating molecular dynamics datasets suitable for machine learning, simulating capped dipeptides across nine residue types with 0.1 ps force-output resolution and atomic force extraction for training Neural Network Potentials.
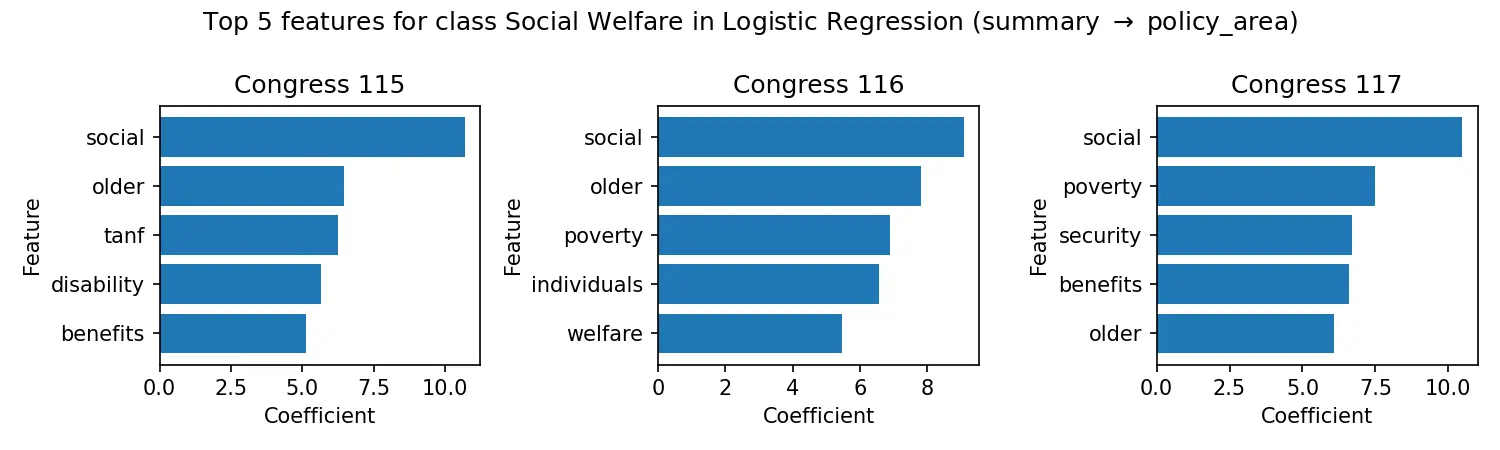
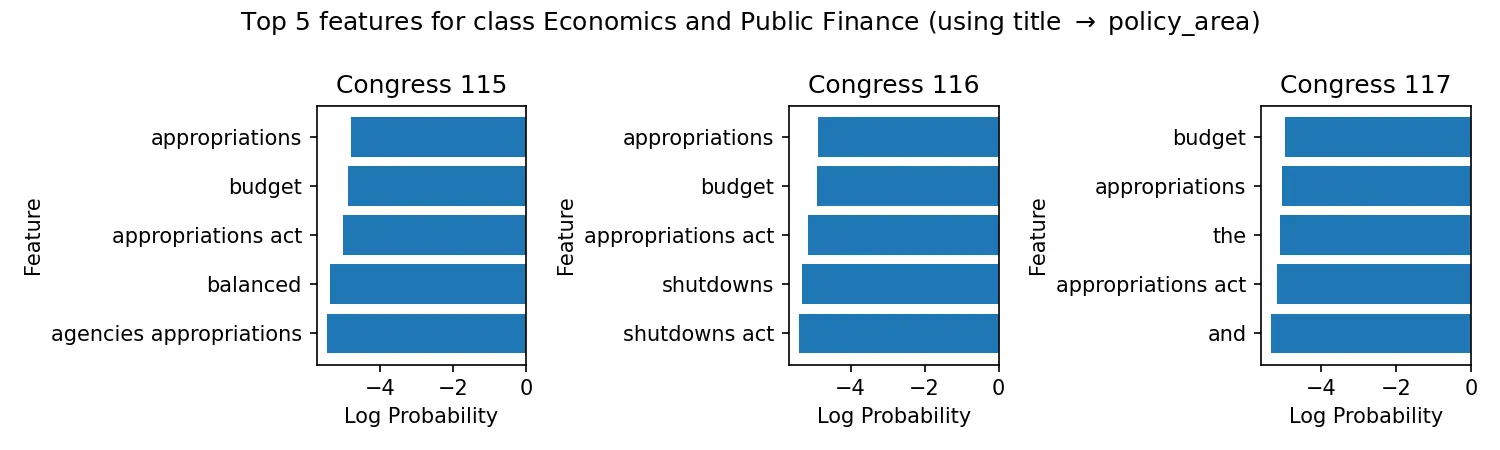
A computational social science project that built a 47,000+ bill dataset from Congress.gov (115th-117th Congresses), with a co-sponsorship legislative graph and TF-IDF baseline models for 33-class policy-area classification (up to ~0.89 weighted F1 on full text), now available on Hugging Face.

Bachelor’s thesis introducing PyConversations, an open-source library that normalizes over 308 million posts from Twitter, Reddit, Facebook, and 4chan into a unified data model for cross-platform social media research.
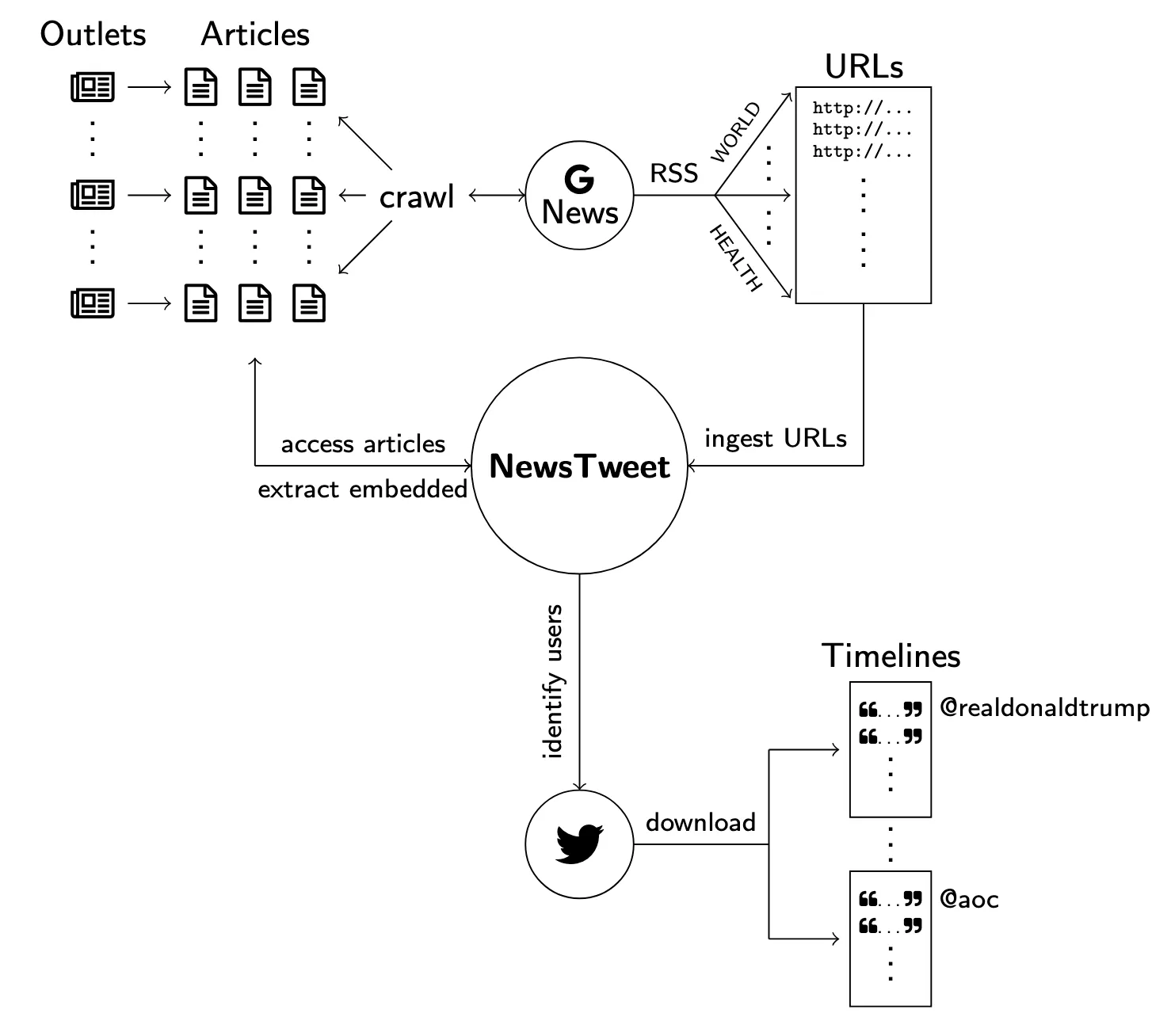
We introduce NewsTweet, a dataset and pipeline for studying embedded tweets in digital journalism, revealing that 13% of Google News articles incorporate tweets and providing insights into how social media becomes newsworthy.
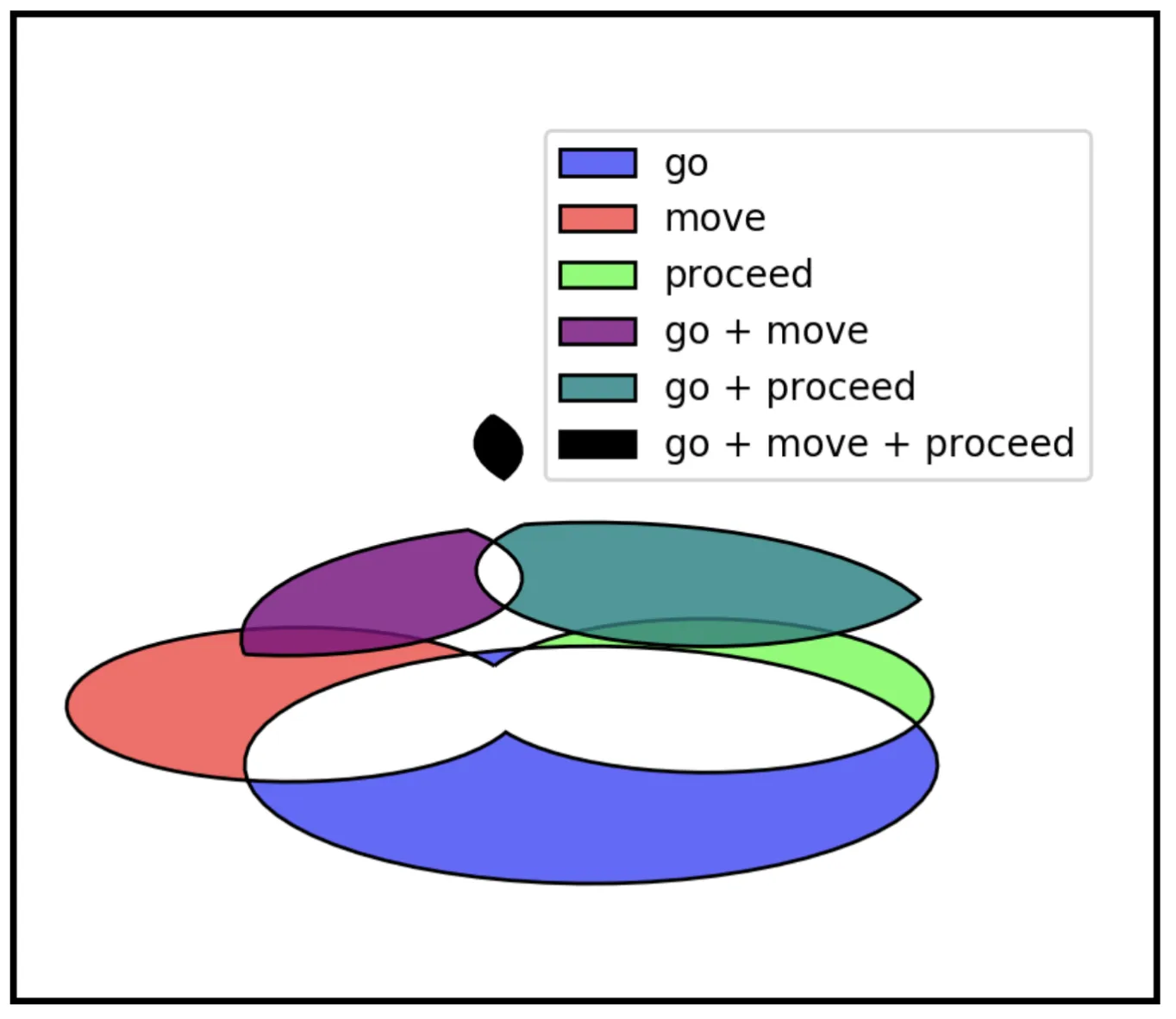
We present an unsupervised algorithm for inducing semantic networks from Wiktionary’s crowd-sourced data, creating a WordNet-like resource more than 5x larger than Princeton WordNet with over 344,000 linked example sentences.

QuAC introduces a conversational QA dataset that models student-teacher interactions, creating context-dependent questions that test systems’ ability to understand dialogue and resolve references.