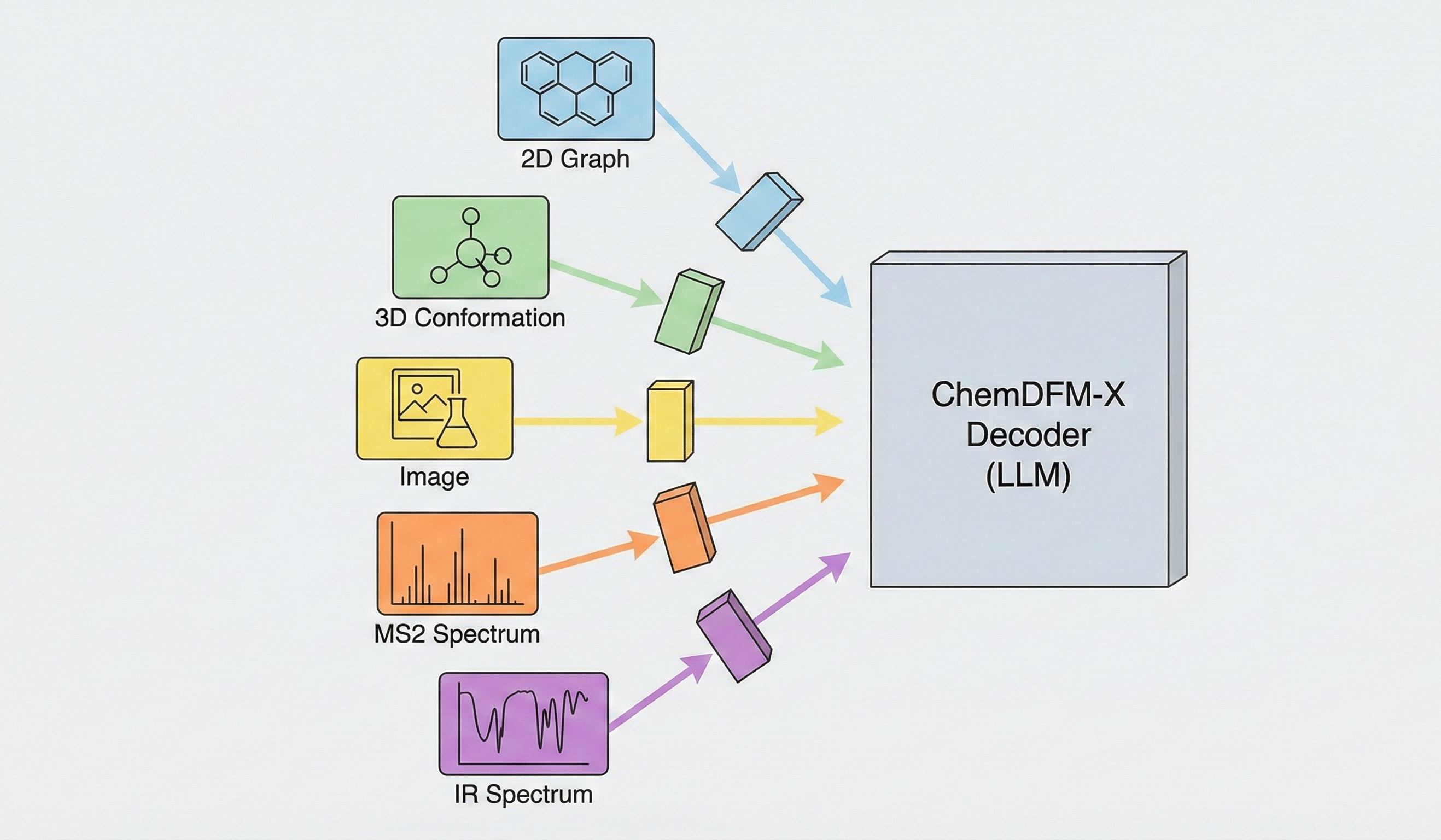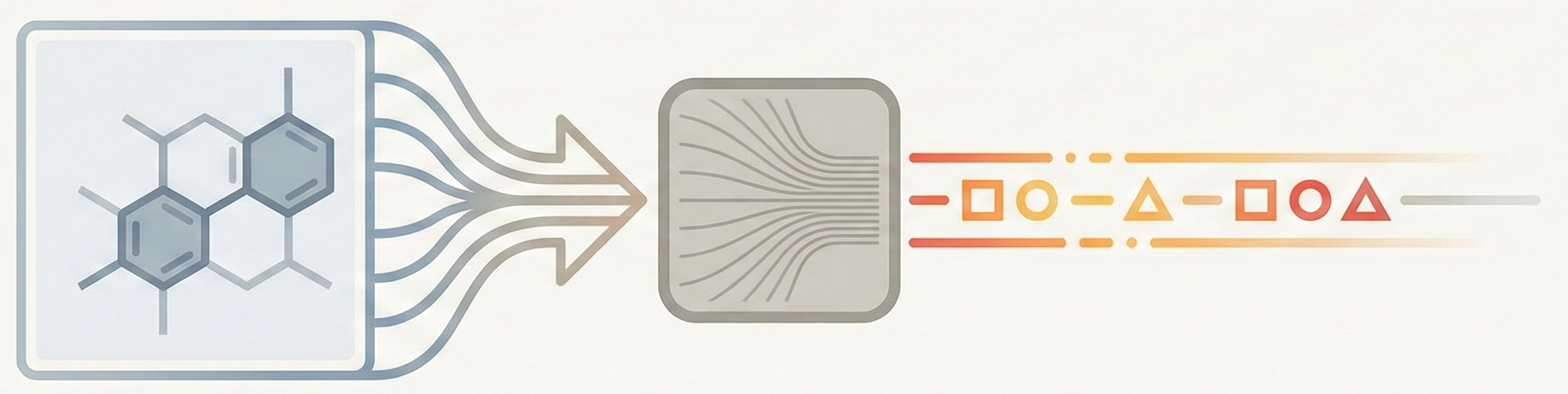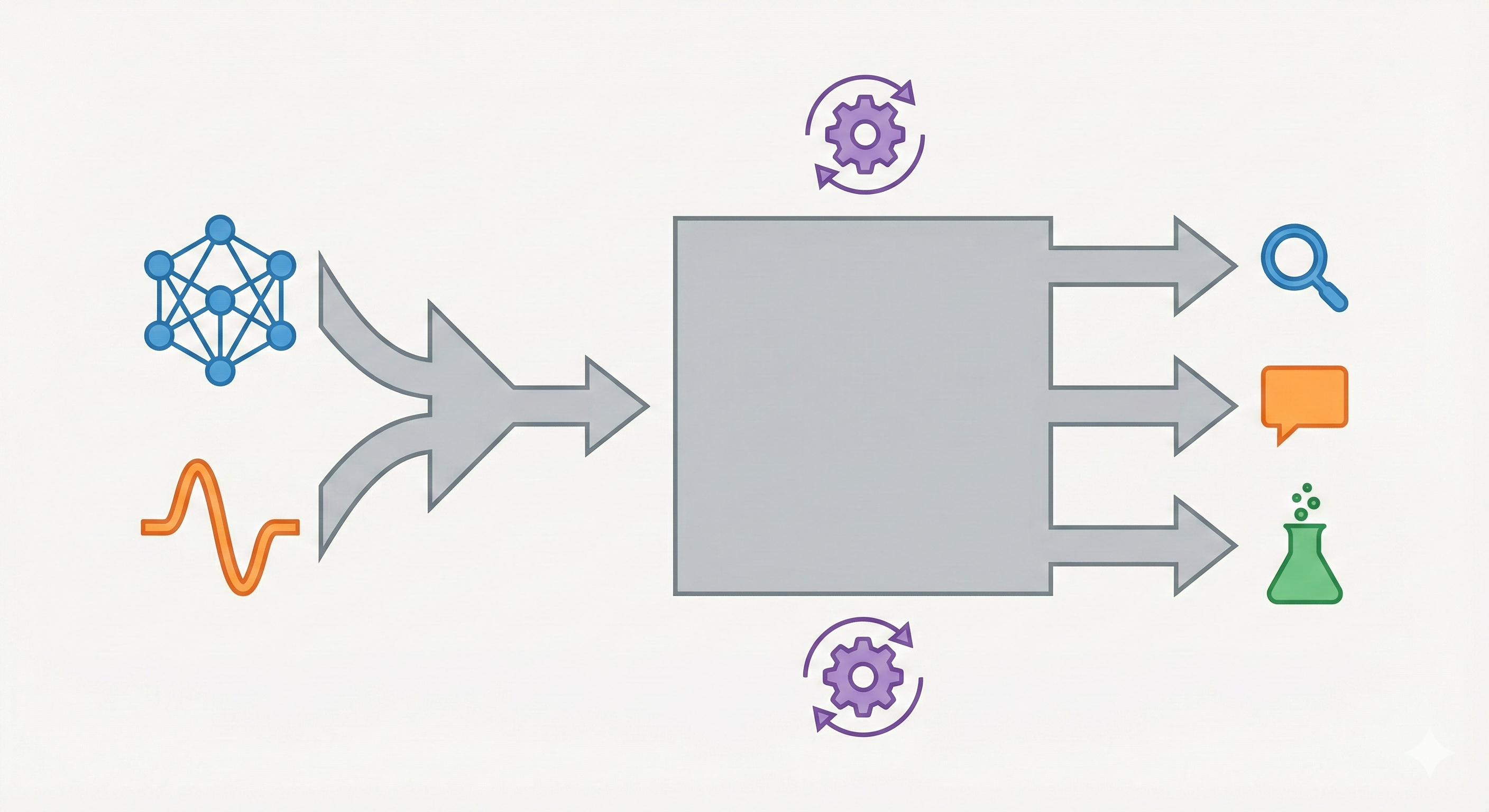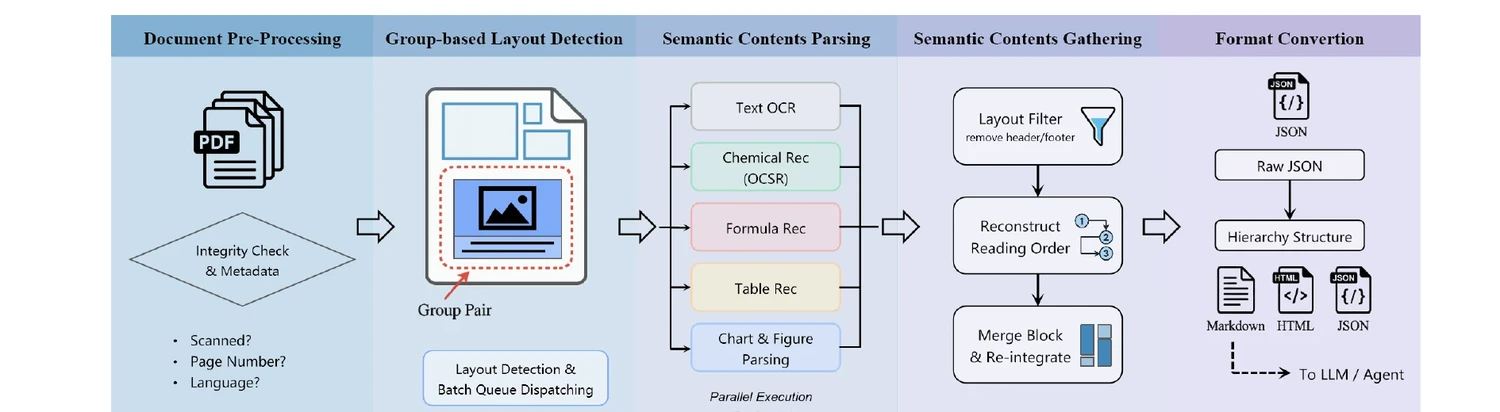
Uni-Parser: Industrial-Grade Multi-Modal PDF Parsing (2025)
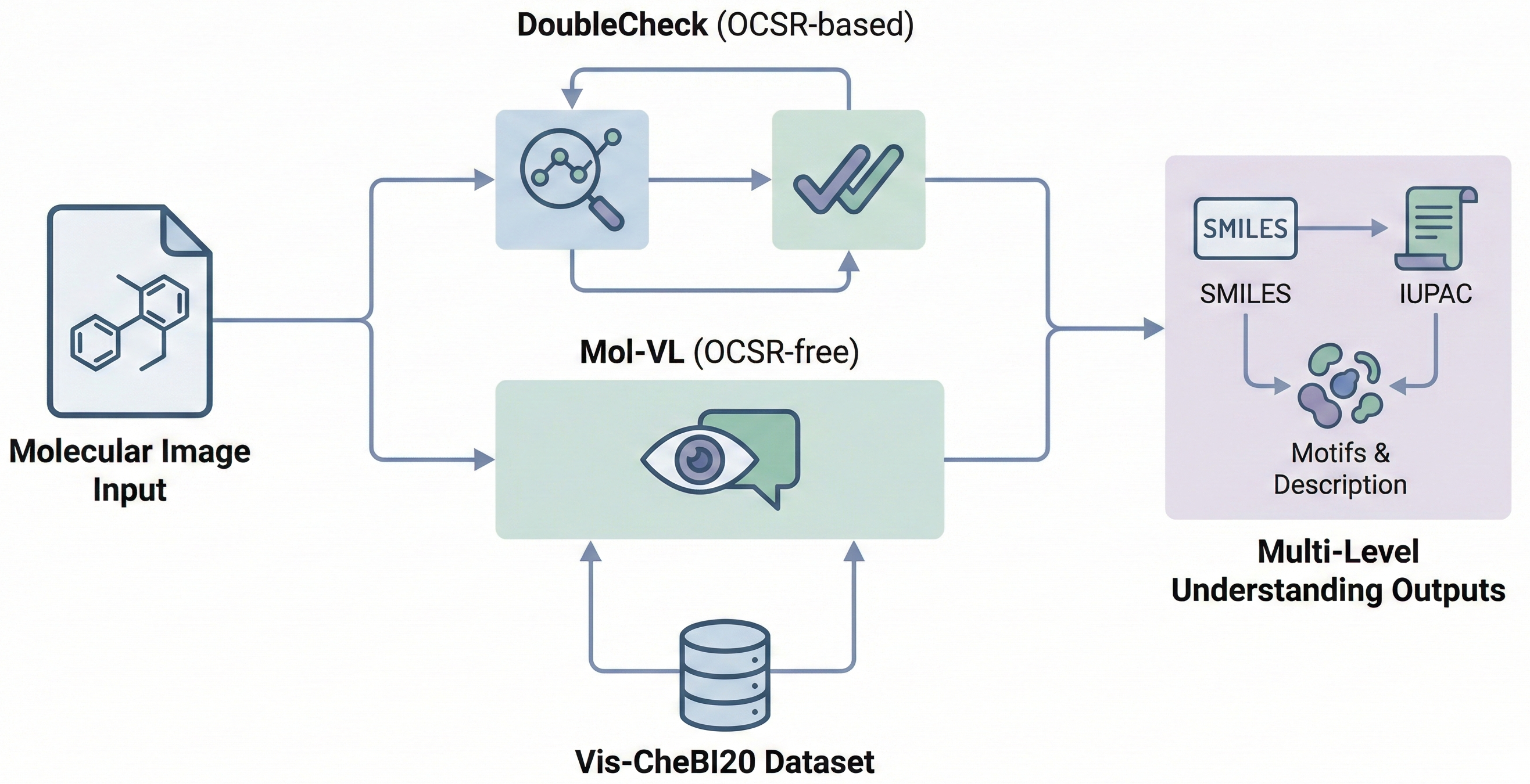
Technical report on Uni-Parser, an industrial-grade document parsing engine that uses a modular multi-expert architecture to parse scientific PDFs into structured representations. Integrates MolParser 1.5 for OCSR, achieving 88.6% accuracy on chemical structures while processing up to 20 pages per second.