Relational Inductive Biases in Deep Learning (2018)
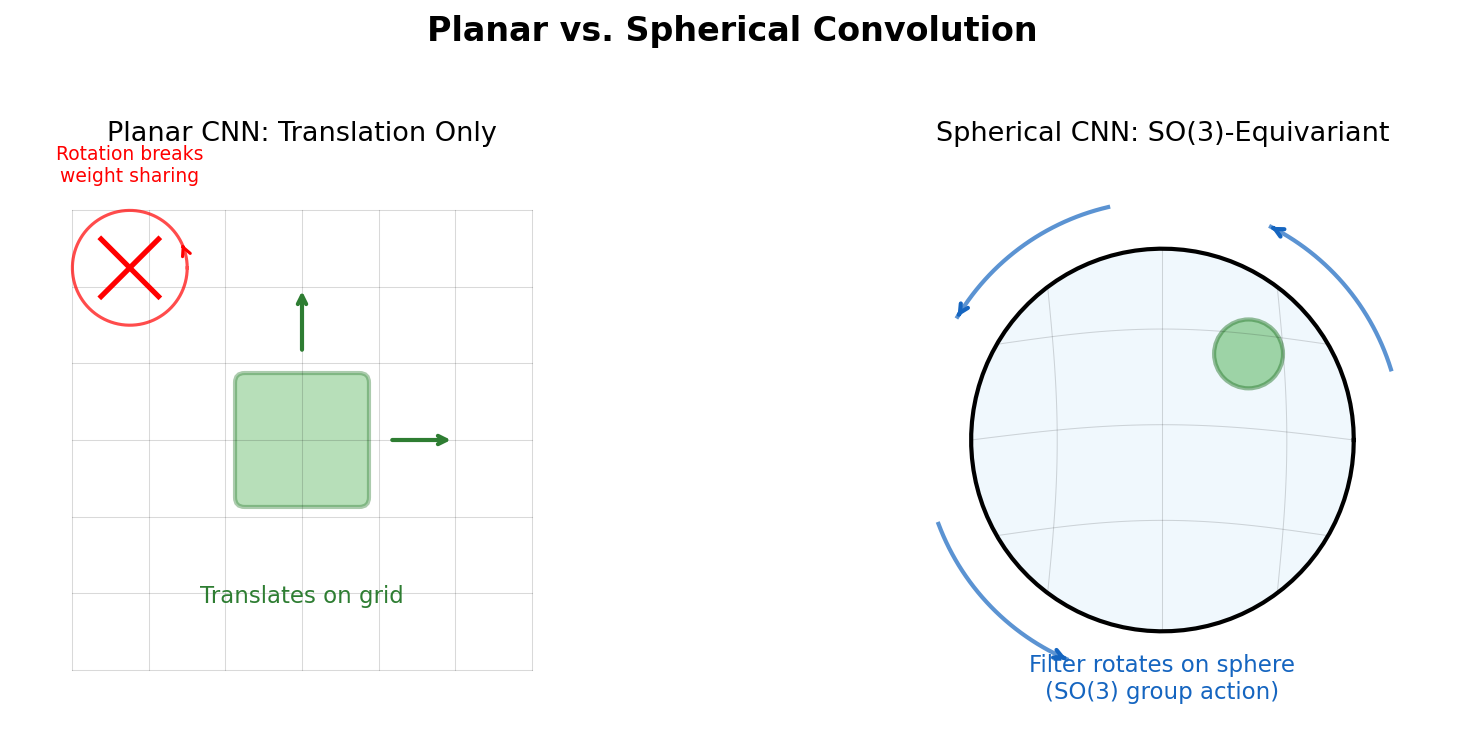
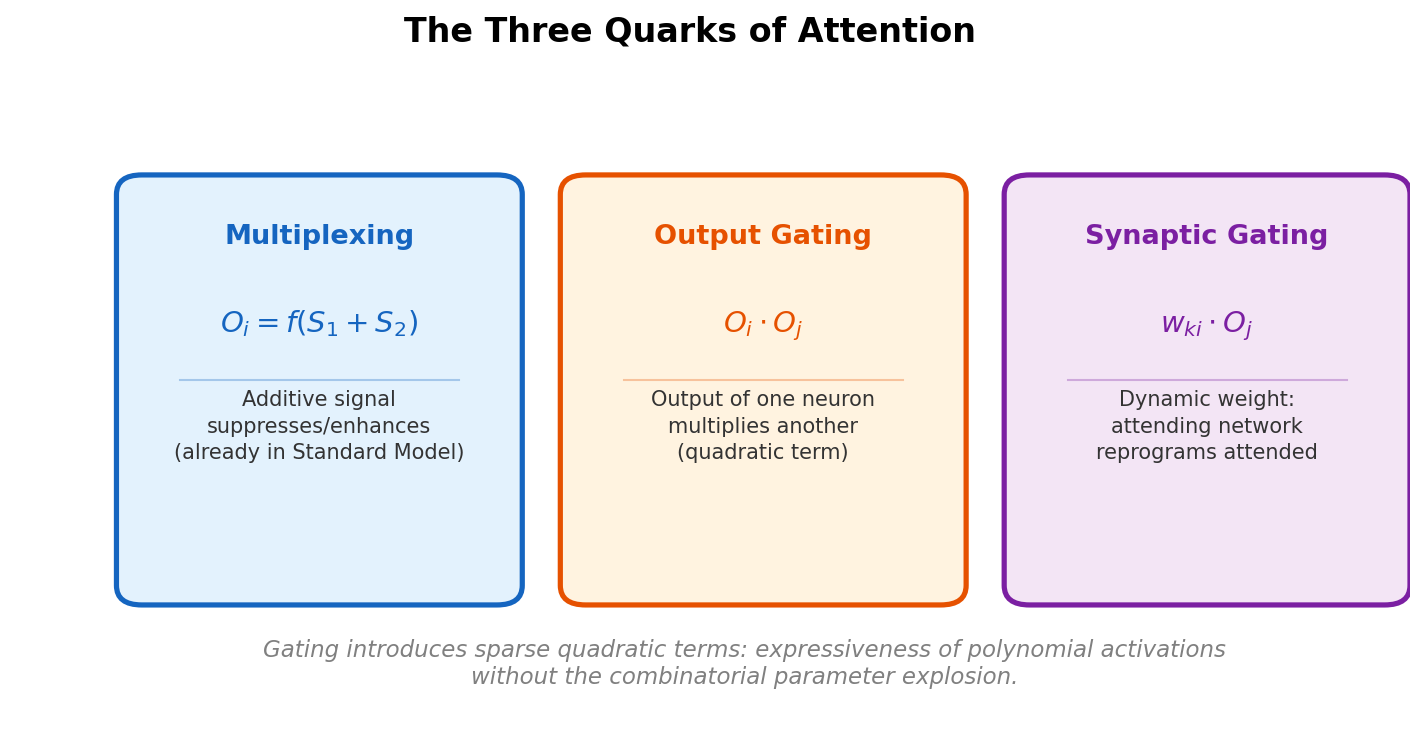
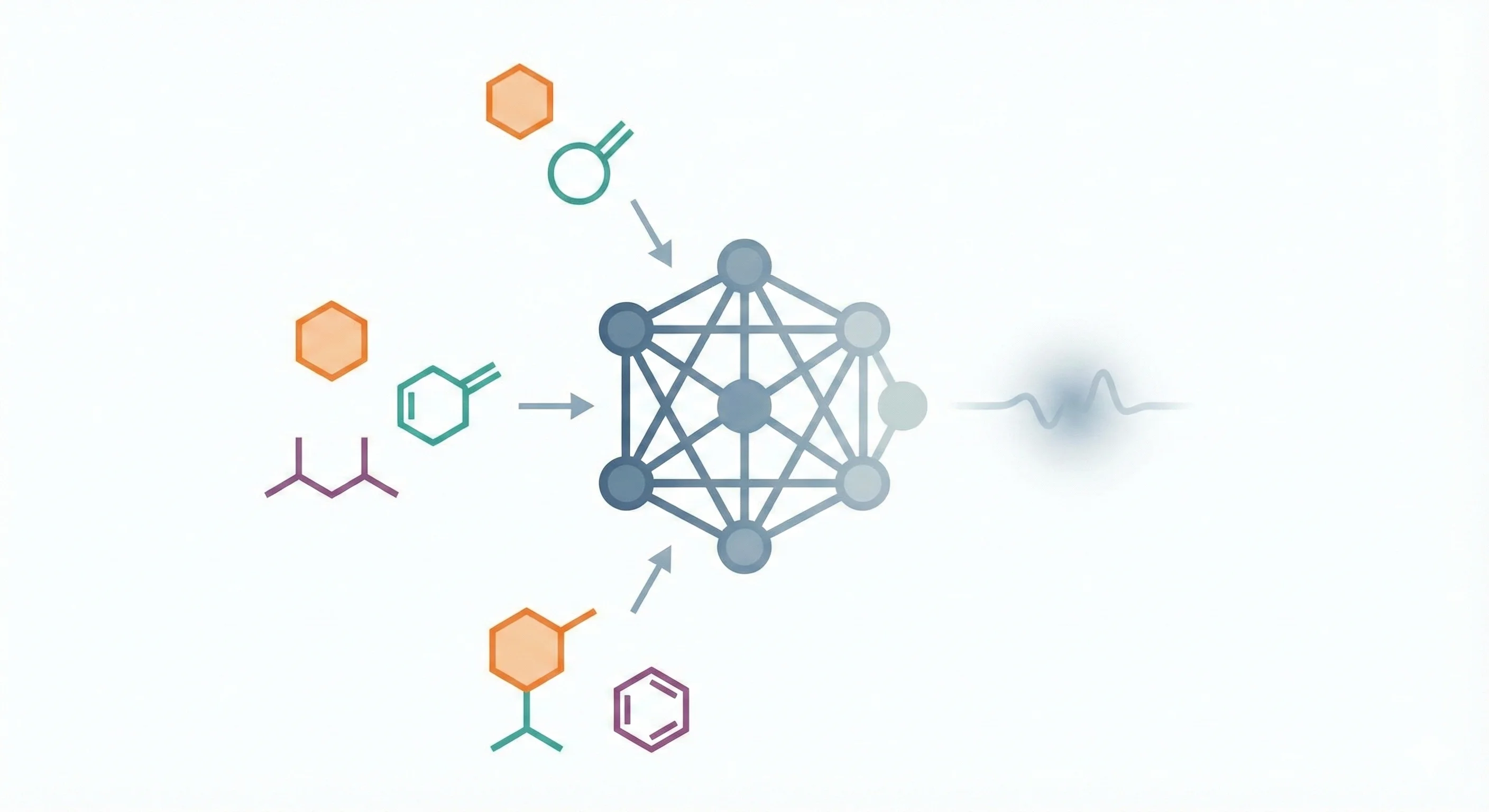
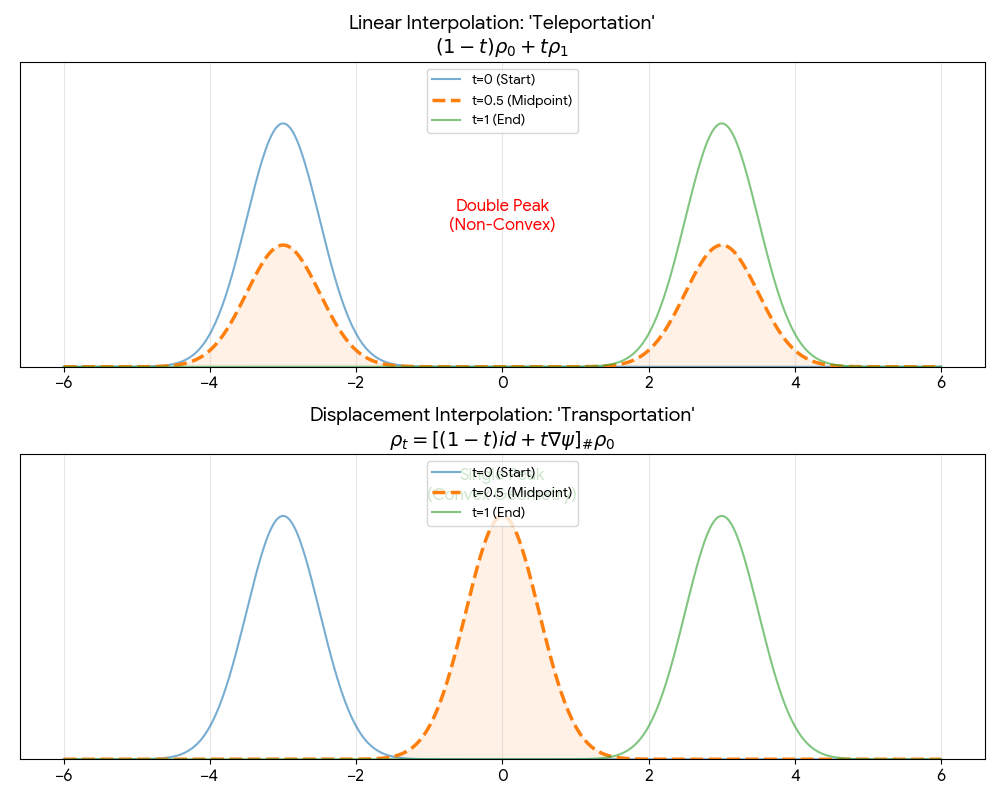
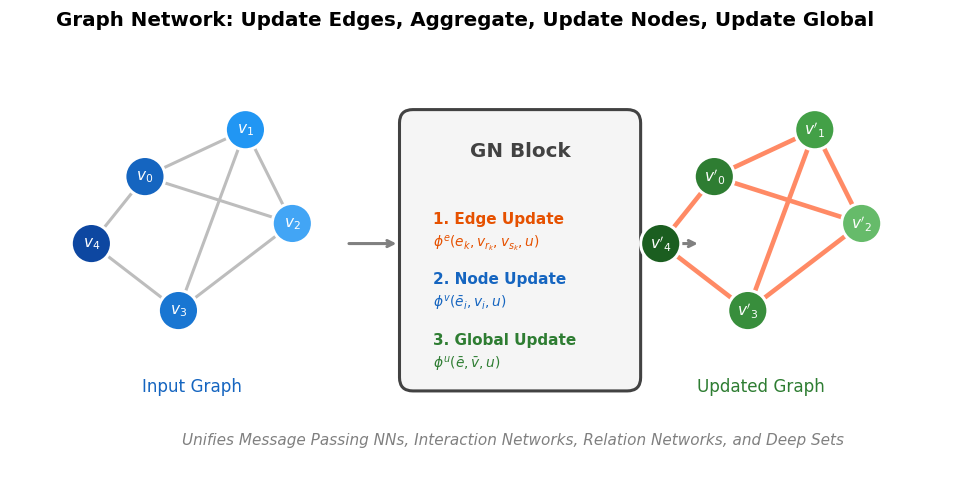
Battaglia et al. argue that combinatorial generalization requires structured representations, systematically analyze the relational inductive biases in standard deep learning architectures (MLPs, CNNs, RNNs), and present the graph network as a unifying framework that generalizes and extends prior graph neural network approaches.