Abstract
While the Skip-Gram with Negative Sampling (SGNS) objective for Word2Vec has famously been shown to factorize a shifted PMI matrix, the implicit matrix factorization of the original Softmax objective has remained an open question. In this work, we provide the first known analytical solution to Word2Vec’s softmax-optimized skip-gram algorithm.
We use this derivation to introduce the Independent Frequencies Model (IFM), identifying a “frequency-ratios property” that unifies classical word vector models. This theoretical insight allows us to derive a low-cost, training-free method for measuring semantic bias directly from corpus statistics.
Key Contributions
- Analytical Solution: Provided the first known analytical solution to Word2Vec’s softmax-optimized skip-gram algorithm, proving it factorizes the log-conditional probability matrix.
- Independent Frequencies Model (IFM): Introduced a dense co-occurrence model computable purely from unigram frequencies to act as a null hypothesis for embedding structures.
- Bias Dissonance Metric: Derived a low-cost, training-free method for measuring semantic bias directly from corpus statistics using the frequency-ratios property.
- Data Transparency: Demonstrated how specific corpora exhibit distinct bias profiles, offering a tool for auditing datasets before training large models.
Key Theoretical Results
1. The Softmax Factorization Theorem
We prove that under the log-softmax objective, Word2Vec implicitly converges towards a factorization of the log-conditional probability matrix of the co-occurrence model.
Theorem: For the objective $\mathcal{L}_{\text{soft}} = - \sum _{t,s} F _{t,s}^m \log \varphi (\vec{u}_t \vec{v}_s)$, the algorithm converges to:
$$ \vec{u}_{t}\vec{v}_{s}^{T} = \log\frac{F_{t,s}^{m}}{f_{t}^{m}} $$
where $F_{t,s}^m$ is the co-occurrence count and $f_t^m$ is the marginal frequency. This effectively makes the dot product of the embedding vectors equal to the log-conditional probability of the context word given the target word.
2. The Independent Frequencies Model (IFM)
To understand the baseline behavior of these models, we introduce the IFM, which models a dense co-occurrence matrix computable purely from unigram frequencies:
$$ \hat{F}_{t,s}^{m} = \frac{2m f_t f_s}{M} $$
This model acts as a “null hypothesis” for embedding structures, allowing us to isolate true semantic signals from statistical noise.
Methodological Innovation: Bias Dissonance
Leveraging the frequency-ratios property derived from our factorization, we propose a metric called Dissonance ($\Delta$) to probe semantic bias in data without training a model.
For an analogy $A:B :: C:D$ (e.g., man:king :: woman:queen), we measure the alignment of their corpus frequency ratios. High dissonance indicates that the corpus statistics do not support the analogy, potentially revealing bias or under-representation.
Intuitive Example: If a corpus contains the phrase “man is king” 100 times more often than “woman is queen,” the frequency ratios are misaligned. A perfect, unbiased analogy would have matching ratios (i.e., man relates to king at the same rate woman relates to queen). Any deviation from this symmetry is captured by our dissonance metric, revealing where the data itself encodes asymmetric associations.
$$ \Delta(x,y|\mathcal{D}) = \left| \log\frac{f_{t}f_{\bar{s}}}{f_{s}f_{\bar{t}}} \right| / \max_{l \in \mathcal{V}} { \log f_l } $$
By applying this to the Bigger Analogy Test Set (BATS), we demonstrated how specific corpora (like Wikipedia vs. Google Books) exhibit distinct bias profiles regarding geographic and encyclopedic knowledge.
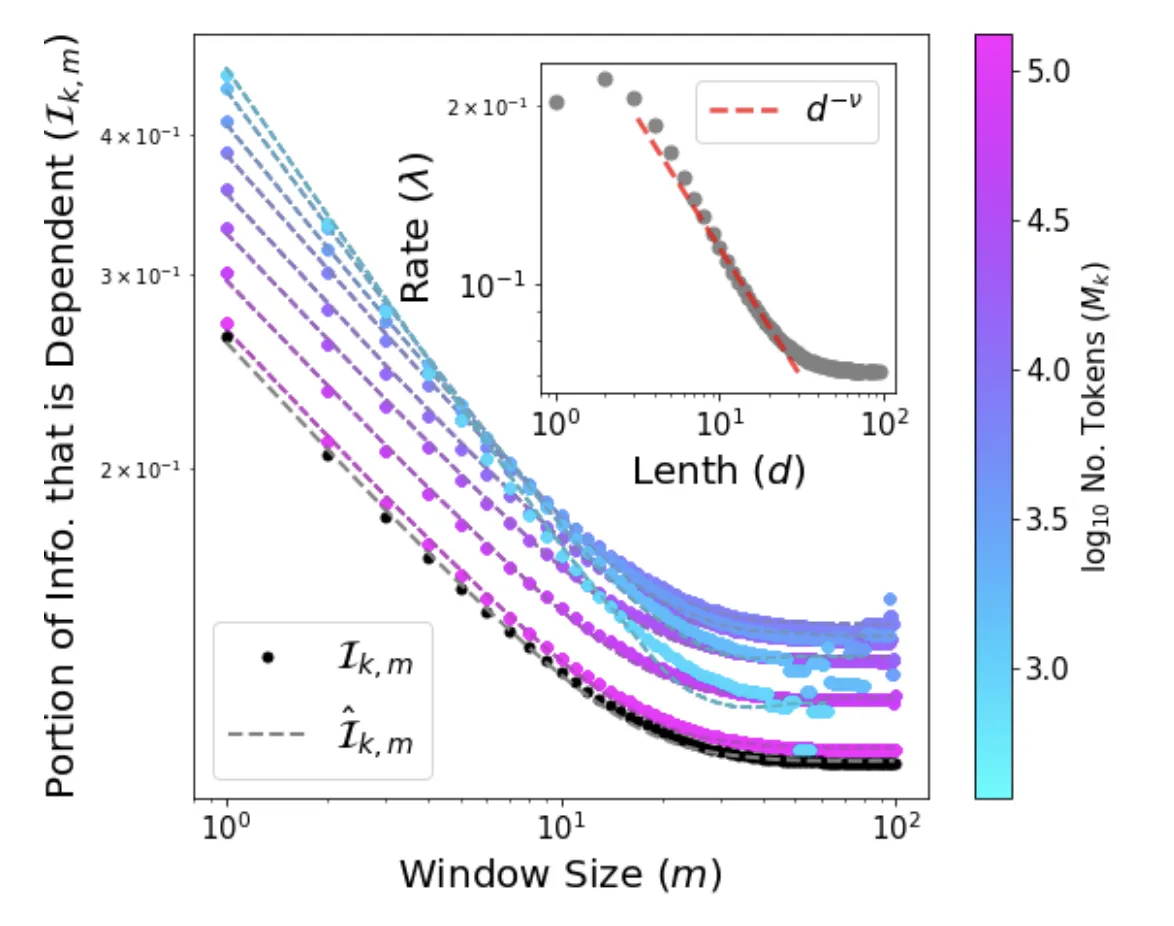
Visualizing Statistical Independence

Impact
This work bridges the gap between empirical success and theoretical foundations in NLP by:
- Solving a fundamental mechanism: Providing the missing factorization proof for Softmax Word2Vec.
- Efficient Pre-training: Suggesting that embedding layers can be “warm-started” using unigram statistics derived from the IFM.
- Data Transparency: Offering a computationally inexpensive tool for auditing datasets for bias before investing resources in training large models.
My Contribution
Jake Williams is the first author and primary driver of this work. He developed the core theory, derived the factorization proofs, designed the dissonance metric, and ran the experiments. My role was supporting: I contributed through critique and refinement during the writing process, but the intellectual heavy lifting belongs to Jake.
Citation
@misc{williams2022knowcompanywordslies,
title={To Know by the Company Words Keep and What Else Lies in the Vicinity},
author={Jake Ryland Williams and Hunter Scott Heidenreich},
year={2022},
eprint={2205.00148},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2205.00148},
}
Related Work
For a complementary analytical approach to word representations, deriving data-free word vector initializations from the same frequency-ratio insights, see EigenNoise: Data-Free Word Vector Initialization.