Abstract
We introduce a novel unsupervised algorithm for inducing semantic networks from noisy, crowd-sourced data. By framing network construction as a “relationship disambiguation” task, we process the entirety of Wiktionary to build a massive, WordNet-like semantic resource. The resulting network is an order of magnitude larger than Princeton WordNet and features over 344,000 linked example sentences (vs. WordNet’s 68k). Evaluation on standard word similarity benchmarks demonstrates that our fully data-driven approach yields semantic structures competitive with expert-annotated resources.
Key Contributions
- Unsupervised Hierarchy Induction: We propose a deterministic algorithm to construct a Directed Acyclic Graph (DAG) of senses from pairwise relationships, effectively inducing a semantic hierarchy without human supervision.
- A Massive Semantic Resource: We release a dataset enriched with hundreds of thousands of semantically linked usage examples, serving as a critical resource for tasks like Word Sense Disambiguation (WSD).
- Novel Disambiguation Framework: We model “relationship disambiguation” using a Laplacian kernel and FastText embeddings to filter noisy user annotations.
- Open-Source Infrastructure: We provide a full pipeline for downloading, parsing, and constructing networks from Wiktionary data.
Technical Approach
The core of our method addresses the noise inherent in crowd-sourced dictionaries. We frame the problem as Latent Semantic Network Induction:
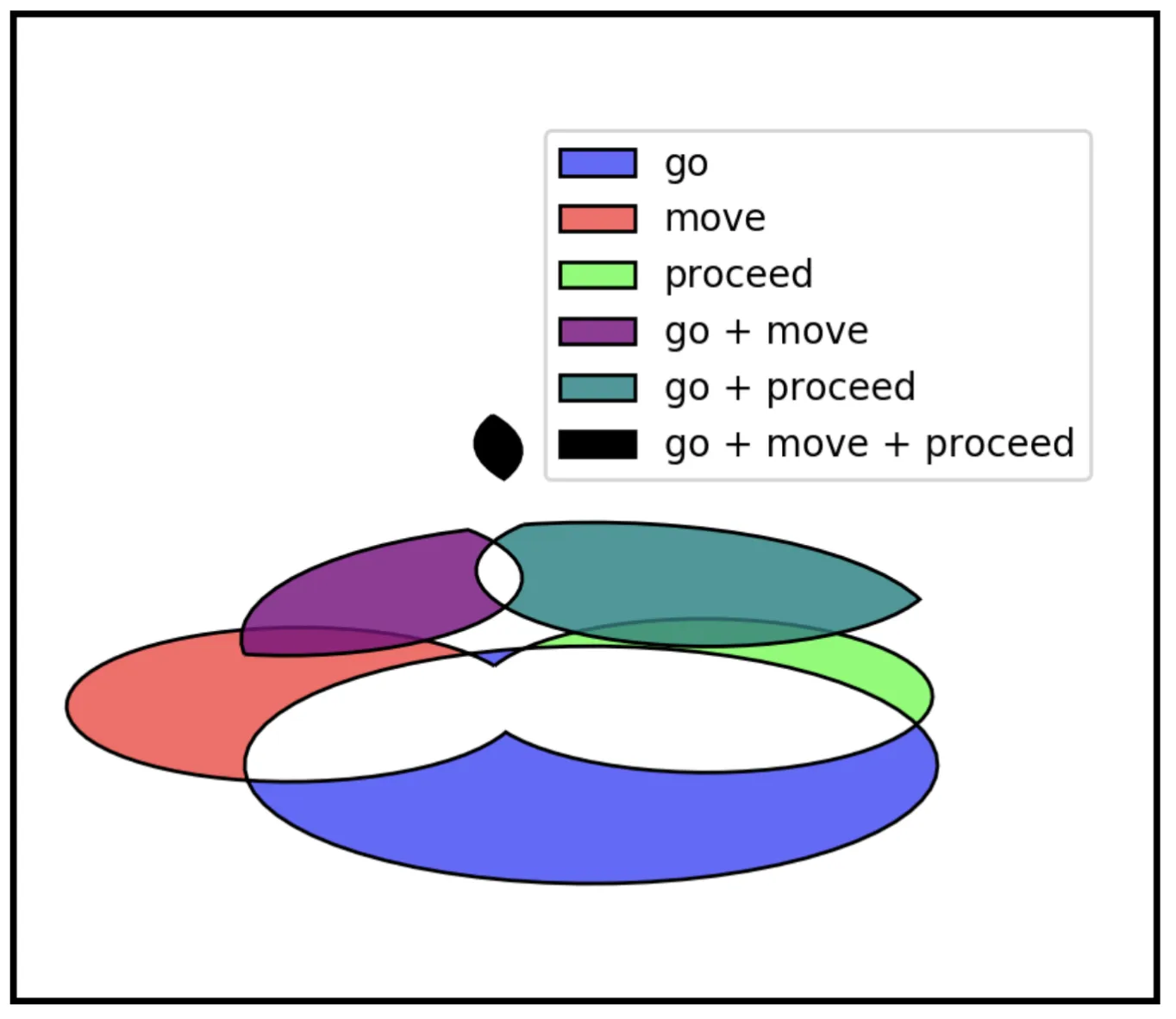
- Relationship Disambiguation: For every linked pair of words (e.g., go ~ proceed), we define a semantic subspace using their definitions. We utilize FastText embeddings and a Laplacian kernel to identify which specific definitions participate in the relationship.
- Hierarchy Construction: We apply a custom intersection algorithm that treats more general senses as the “overlap” between specific definition sets. We formalize this as a set-theoretic “hole punching” operation, where a general sense $t$ is defined by the intersection of definition sets $\mathbb{D}’$, excluding any broader intersections:
$$f^{-1}(t) = \left(\bigcap_{\mathbb{D}’} D_{u\sim v}\right) \setminus \left(\bigcup_{\mathbb{D} \supset \mathbb{D}’} \bigcap_{\mathbb{D}} D_{u\sim v}\right)$$
Evaluation & Validation
The primary achievement is scale: our induced network contains over 344,000 linked example sentences, compared to Princeton WordNet’s 68,000 (more than 5x the coverage), built entirely from crowd-sourced data without expert annotation.
Beyond scale, the network holds up semantically. On standard noun-similarity benchmarks (RG-65), the unsupervised network achieves a Spearman rank correlation of $\rho = 0.83$, matching the performance of Explicit Semantic Analysis (ESA) models built on expert-annotated WordNet ($\rho = 0.82$). The point is not that we beat WordNet by 0.01. It is that a fully automated approach over noisy Wiktionary data produces a resource of comparable quality at 5x the scale.
Why This Matters
Building high-quality linguistic resources typically requires expensive expert annotation. Princeton WordNet took decades of lexicographer effort. This work demonstrates that an unsupervised algorithm over crowd-sourced data can produce a resource of comparable semantic quality at more than 5x the scale. For ML practitioners, that matters: larger coverage means more training signal for downstream tasks like Word Sense Disambiguation. For this portfolio, it shows early experience building structured NLP datasets from scratch, a theme that continues in later work on large-scale document corpora.
Related Work
For a theoretical treatment of word semantics from the same collaboration, including the first analytical solution to Word2Vec’s softmax objective, see Analytical Solution to Word2Vec Softmax & Bias Probing.
Citation
@inproceedings{heidenreich2019latent,
title={Latent semantic network induction in the context of linked example senses},
author={Heidenreich, Hunter and Williams, Jake},
booktitle={Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019)},
pages={170--180},
year={2019}
}