Abstract
Page Stream Segmentation (PSS) is critical for automating document processing in industries like insurance, where unstructured document collections are common. This paper explores the use of large language models (LLMs) for PSS, applying parameter-efficient fine-tuning to real-world insurance data. Our experiments show that LLMs outperform baseline models in segmentation accuracy. We find that stream-level calibration remains a significant challenge. We evaluate post-hoc calibration and Monte Carlo dropout, finding they offer limited improvement, highlighting the need for future work in this area for high-stakes applications.
This work builds on our earlier research establishing the TabMe++ benchmark and decoder-based LLM approach, extending those methods to real-world industrial deployment.
Blog Post: For a narrative overview of the reliability and calibration findings discussed in this paper, see The Reliability Trap: When 99% Accuracy Isn’t Enough.
Key Contributions
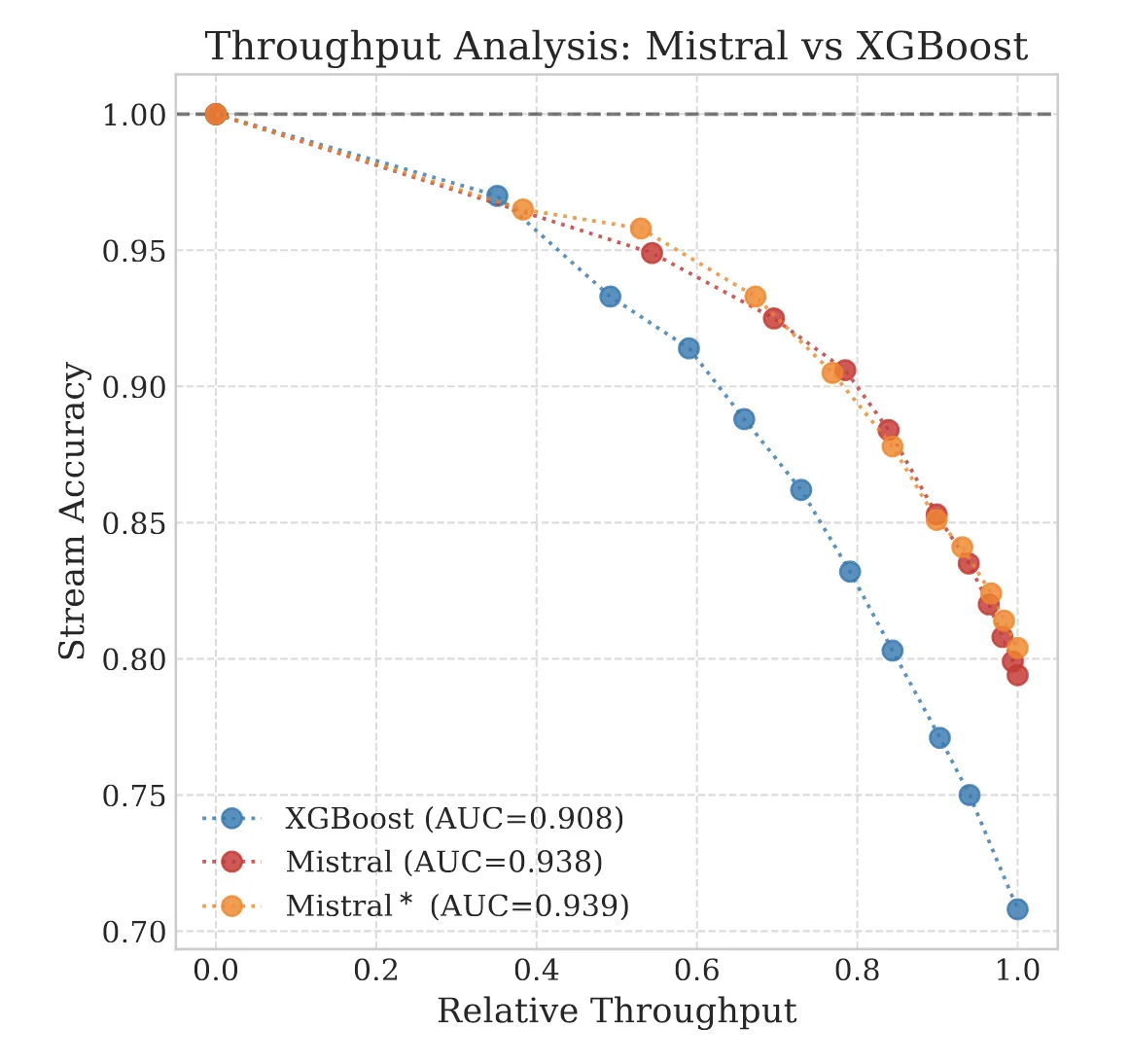
- Real-World Evaluation: Applied small-to-mid-sized LLMs (Phi-3.5-mini, Mistral-7B) to a proprietary insurance dataset, outperforming strong baselines like XGBoost in segmentation accuracy.
- Parameter-Efficient Fine-Tuning: Successfully used parameter-efficient fine-tuning (PEFT) to adapt LLMs for the specialized task of page stream segmentation.
- Calibration Complexity: Found that post-hoc calibration and Monte Carlo dropout offer limited improvement at the stream level, keeping human-in-the-loop workflows necessary for high-stakes automation (see stream-level confidence analysis below).
- Throughput Analysis: Introduced an accuracy-vs-throughput framework to quantify how much volume can be safely automated at strict confidence thresholds.
Stream-Level Confidence
A key insight from this work is why calibration becomes increasingly difficult as documents grow longer. We define stream-level confidence as the product of individual page-level confidences:
$$C = \prod_{i=1}^{N} C_i$$
where $C_i$ is the confidence for page $i$ and $N$ is the number of pages in the stream. This multiplicative relationship means that even small page-level errors compound aggressively. As streams grow longer, confidence drops rapidly, making it difficult to set reliable thresholds for automation.

Technical Implementation
Models & Fine-Tuning
We fine-tuned Mistral-7B-v0.3 and Phi-3.5-mini (4-bit quantized) using QLoRA. Training was performed efficiently on a single NVIDIA H100 GPU using the Unsloth library and Hugging Face’s TRL.
- Stack: Unsloth + TRL
- Config: Rank $r=16$, Alpha $\alpha=16$
Dataset
The study utilized a proprietary insurance dataset consisting of 7.5k document streams (44.7k pages). This real-world data includes medical records, legal contracts, and police reports, offering a more challenging and realistic evaluation than synthetic benchmarks.
Prompting Strategy
We framed the task as binary classification over a local context window (previous page + current page). Models were prompted to output valid JSON indicating the start of a new document.
Impact
This work demonstrates both the promise and the current limitations of using LLMs in high-stakes industrial applications. LLMs can significantly improve segmentation accuracy over traditional methods, but performance metrics alone are not sufficient for deployment. For sectors like insurance, stream-level calibration is an open problem that must be solved before full automation becomes responsible.
Citation
@inproceedings{heidenreich2025page,
title={Page Stream Segmentation with LLMs: Challenges and Applications in Insurance Document Automation},
author={Heidenreich, Hunter and Dalvi, Ratish and Verma, Nikhil and Getachew, Yosheb},
booktitle={Proceedings of the 31st International Conference on Computational Linguistics: Industry Track},
pages={305--317},
year={2025}
}