Abstract
Page Stream Segmentation (PSS), the task of correctly dividing a sequence of pages into distinct documents, is a critical first step in automated document processing pipelines. Research in this area has been held back by the lack of high-quality, public datasets.
In this work, we address this issue by enhancing an existing benchmark, TabMe, with commercial-grade Optical Character Recognition (OCR) to create TabMe++. This new version significantly reduces noise and improves text detection, highlighting the critical importance of OCR quality for document understanding tasks.
We then conduct the first evaluation of large, decoder-based language models (LLMs) on the PSS task. Our findings show that models like Mistral-7B, when fine-tuned using parameter-efficient methods, decisively outperform smaller encoder-based models and traditional baselines. For instance, our best model correctly segments 80% of document streams in the test set without any errors.
Key Contributions
- Enhanced Public Benchmark (TabMe++): Re-processed the entire TabMe dataset with commercial OCR, correcting significant text recognition errors and reducing blank pages by over 80% (from 2.27% to 0.38%)
- First Application of Large Decoder-Based LLMs to PSS: Systematically evaluated and fine-tuned billion-parameter, decoder-only LLMs for page stream segmentation
- State-of-the-Art Performance: Demonstrated that fine-tuned decoder models achieve superior results on TabMe++, significantly outperforming previous encoder-based and multimodal approaches
- OCR Quality Analysis: Quantified the dramatic impact that high-quality OCR has on PSS model performance through comparative experiments
The Evolution of Page Stream Segmentation
The paper systematizes the history of PSS into three distinct algorithmic eras, revealing a clear trajectory toward semantic understanding:
- The Heuristic Era: Early systems relied on handcrafted rules and region-specific pattern matching (e.g., looking for headers/footers), which failed to generalize across heterogeneous documents.
- The Encoder Era: The field moved to “learning-based” methods using Convolutional Neural Networks (CNNs) and later Transformer encoders like LayoutLM and LEGAL-BERT. While better, these often required complex multimodal architectures.
- The Decoder Era (New Contribution): This work establishes the viability of the third era: using billion-parameter generative models (decoder-only LLMs) which simplify the architecture while dramatically improving semantic reasoning.
Blog Post: Read the full story of these eras in The Evolution of Page Stream Segmentation.
Key Evaluation Metrics
Beyond standard F1 scores, the study evaluates models on metrics that directly translate to operational costs:
- Straight-Through Processing (STP): The percentage of document streams segmented perfectly, requiring zero human intervention. The fine-tuned Mistral-7B achieved an STP of 0.800, meaning 80% of streams were fully automated. In contrast, the traditional XGBoost baseline achieved only 0.074.
- Minimum Number of Drag-and-Drops (MNDD): A proxy for human effort, measuring how many pages a human would need to move to correct the segmentation. The best LLM reduced this “effort metric” by over 13x compared to the XGBoost baseline (0.81 vs 10.85).
Document-Level Precision and Recall
We define a ground truth segmentation $\mathcal{G}$ and a predicted segmentation $\mathcal{P}$. A “True Positive” is defined strictly as a document present in both sets ($\mathcal{P} \cap \mathcal{G}$). The metrics are calculated as:
$$P = \frac{|\mathcal{P} \cap \mathcal{G}|}{|\mathcal{P} \cap \mathcal{G}| + |\mathcal{P} \setminus \mathcal{G}|}$$
$$R = \frac{|\mathcal{P} \cap \mathcal{G}|}{|\mathcal{P} \cap \mathcal{G}| + |\mathcal{G} \setminus \mathcal{P}|}$$
This rigorous definition ensures that a model is only rewarded if it gets both the start and end boundaries of a document correct.
Technical Innovation
Our approach combines commercial-grade OCR processing with parameter-efficient fine-tuning of large language models. We addressed two main bottlenecks: data quality and model efficiency.
Data Remediation
The original TabMe dataset relied on Tesseract OCR, which introduced significant noise. By reprocessing the images with Microsoft OCR, we reduced the number of “blank” pages from 2.27% to just 0.38%, recovering critical features like titles and ID numbers that were previously lost.
Model Architecture
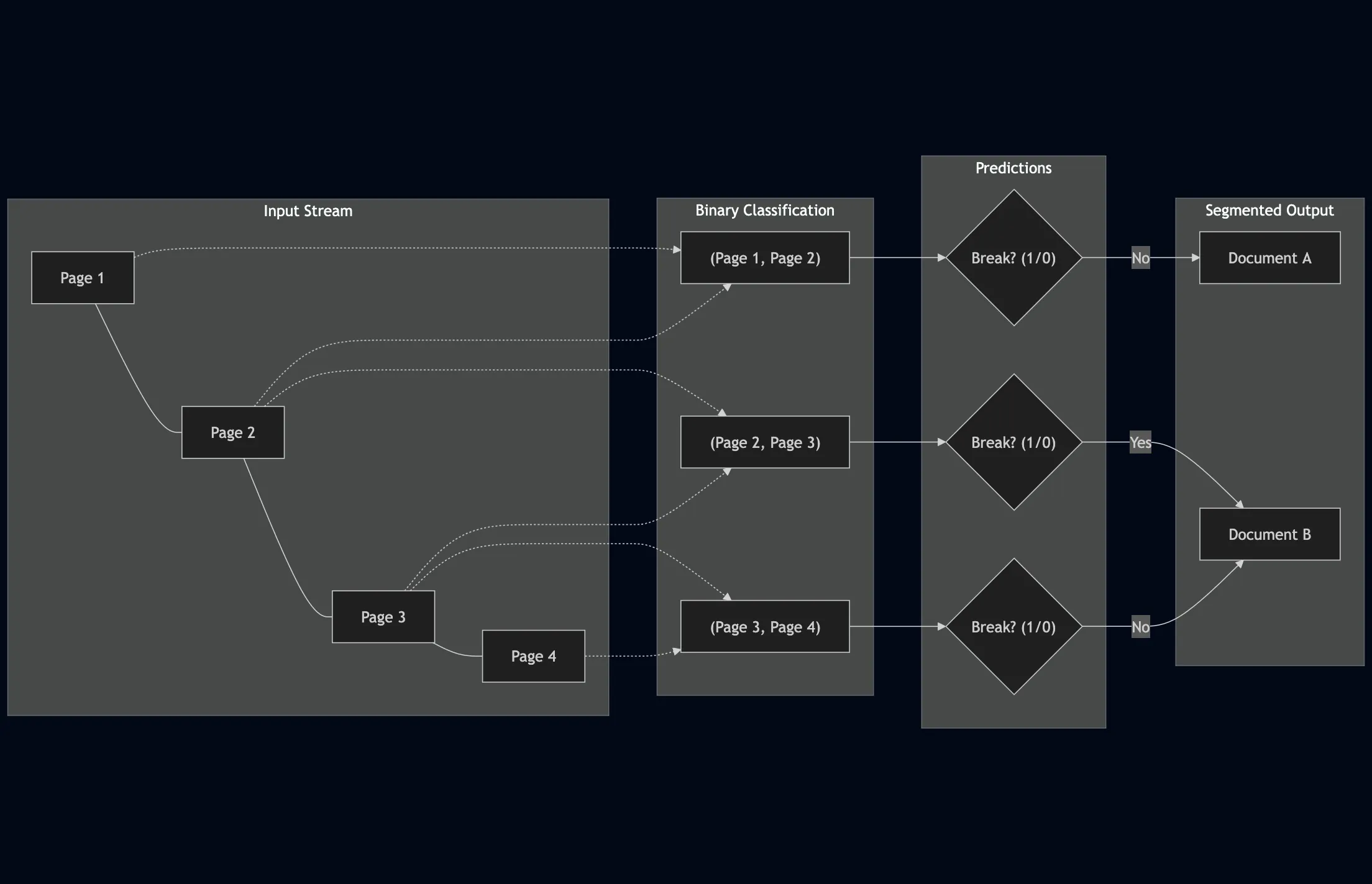
We formulated the task as a binary classification of page pairs: predicting if a “break” exists between Page $N$ and Page $N+1$.
Problem Formulation
The task is treated as a binary classification problem over a window of pages. For a specific page $p_i$, the model predicts a binary label $y_i$ based on a window of adjacent pages $(p_{i-l}, \ldots, p_i, \ldots, p_{i+r})$. In this work, we strictly defined the window as:
$$l=1, \quad r=0$$
This means the decision for page $p_i$ is made solely based on the pair $(p_{i-1}, p_i)$.
Efficient Tuning
We utilized Low-Rank Adaptation (LoRA) and 4-bit quantization to fine-tune Mistral-7B and Phi-3-mini on consumer-grade hardware (single NVIDIA H100), proving that PSS does not require massive compute clusters.
Why This Matters
Page Stream Segmentation is the critical first step in any automated document processing pipeline. If a system fails to correctly separate documents, all downstream tasks (like classification or data extraction) will operate on corrupted inputs. By demonstrating that parameter-efficiently fine-tuned LLMs can achieve an 80% straight-through processing rate, this work provides a viable path toward fully automating high-volume document workflows.
Beyond the path to automation, this work gives the research community improved evaluation tools: the enhanced TabMe++ dataset and the quantified impact of OCR quality on PSS performance have direct applications in commercial document processing pipelines.
We later extended these findings to real-world industrial deployment and analyzed model calibration challenges in our follow-up COLING Industry paper on LLMs for Insurance Document Automation. The calibration challenges that emerged from that deployment are explored in depth in The Reliability Trap: When 99% Accuracy Isn’t Enough.
Citation
@misc{heidenreich2024largelanguagemodelspage,
title={Large Language Models for Page Stream Segmentation},
author={Hunter Heidenreich and Ratish Dalvi and Rohith Mukku and Nikhil Verma and Neven Pičuljan},
year={2024},
eprint={2408.11981},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.11981}
}