Abstract
We developed EigenNoise, a method to initialize word vectors using zero pre-training data. By deriving a co-occurrence matrix solely from the theoretical harmonic structure of language (Zipf’s Law), this project demonstrates that we can mathematically synthesize a “warm-start” for NLP models. This approach challenges the reliance on massive corpora for initialization and offers a competitive alternative for low-resource environments.
Key Contributions
- Algorithmic Innovation: Created a data-free initialization scheme by modeling independent co-occurrence statistics and applying eigen-decomposition
- Theoretical Grounding: Leveraged the harmonic statistical structure of language to derive representations from first principles
- Information-Theoretic Evaluation: Utilized Minimum Description Length (MDL) probing to rigorously measure the information content and regularity of the learned representations
- Efficiency: Demonstrated that EigenNoise vectors, once fine-tuned, match the performance of GloVe vectors (trained on Gigaword) despite seeing no pre-training text
Technical Implementation
The core insight is that “noise” in language follows a predictable distribution.
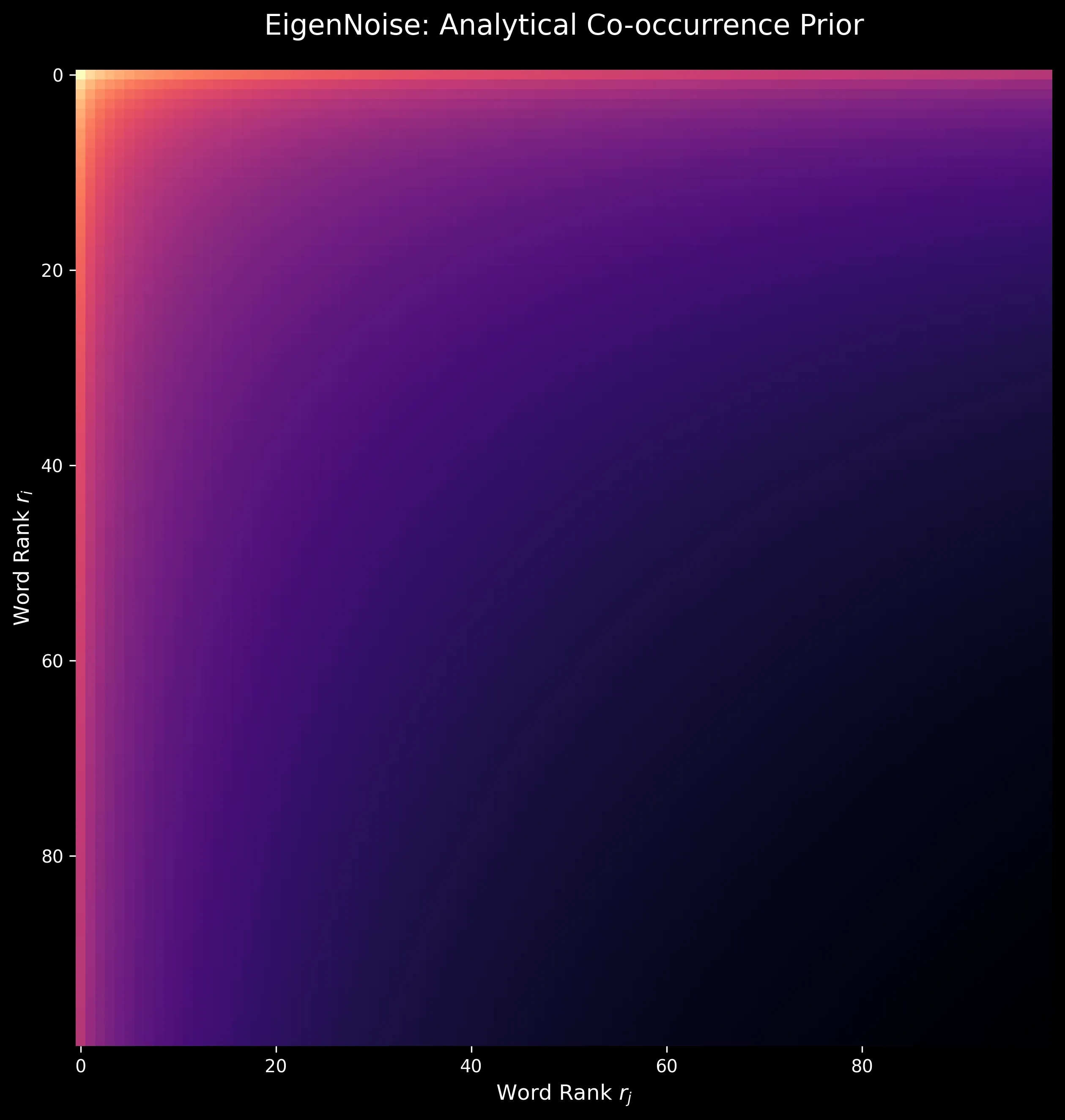
- Modeling: We model the “null hypothesis” of text, how words would co-occur if they were statistically independent but followed Zipfian rank-frequency. This yields a theoretical co-occurrence matrix $\hat{X}$:
$$\hat{X}_{ij} = \frac{2mN}{r_i r_j H_N}$$
Where $r_i$ is the rank of word $i$, $N$ is vocabulary size, $m$ is the context window size, and $H_N$ is the $N$-th harmonic number.
Factorization: We then solve for the word vectors by performing an eigen-decomposition on this matrix, extracting the top $d$ components to form the representation space.
Probing: Validated performance using MDL probing on CoNLL-2003 and TweetEval benchmarks.
Why This Matters
This research explores how much structure can emerge from frequency statistics alone, with no text exposure at all. The central finding is that EigenNoise vectors, derived purely from Zipf’s Law, reach competitive performance with GloVe after fine-tuning. This is evidence that a significant portion of what we call “learned linguistic knowledge” is a consequence of word frequency distributions, not semantic exposure to real text.
In 2026, small pretrained models are freely available and handle most low-resource initialization needs, so the practical case for data-free initialization is narrower than it was in 2022. The theoretical contribution remains relevant: EigenNoise establishes a clean null hypothesis for what word vectors look like when only frequency information is present. For interpretability researchers trying to disentangle frequency artifacts from genuine semantic content, this baseline has value independent of the initialization use case.
The MDL probing methodology applied here also contributes beyond the main result. Unlike task accuracy, MDL measures how much information a representation encodes and how compactly, providing a more principled lens for evaluating representational quality. EigenNoise’s co-occurrence prior is grounded directly in the Independent Frequencies Model (IFM) introduced in the companion Word2Vec factorization paper. Together, the two works form a coherent theoretical line: the IFM characterizes the frequency-driven baseline of embedding space, and EigenNoise operationalizes it as a practical, data-free initialization scheme.
Citation
@misc{heidenreich2022eigennoisecontrastivepriorwarmstart,
title={EigenNoise: A Contrastive Prior to Warm-Start Representations},
author={Hunter Scott Heidenreich and Jake Ryland Williams},
year={2022},
eprint={2205.04376},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2205.04376},
}
Related Work
For the theoretical foundation underlying EigenNoise’s null hypothesis, including the first analytical solution to Word2Vec’s softmax objective, see Analytical Solution to Word2Vec Softmax & Bias Probing.