Abstract
Advanced neural network architectures developed for tasks like natural language processing are often transferred to spatiotemporal forecasting without a deep understanding of which components drive their performance. This can lead to suboptimal results and reinforces the view of these models as “black boxes”. In this work, we deconstruct the core mechanisms of Transformers and Recurrent Neural Networks (RNNs) (namely attention, gating, and recurrence). We then build and test novel hybrid architectures to identify which components are most effective. A key finding is that while adding recurrence is detrimental to Transformers, augmenting RNNs with attention and neural gating consistently improves their forecasting accuracy. Our study reveals that a seldom-used architecture, the Recurrent Highway Network (RHN) enhanced with these mechanisms, emerges as the top-performing model for forecasting high-dimensional chaotic systems.
Key Contributions
- Systematic Ablation: Deconstructed Transformers and RNNs into core mechanisms (attention, gating, recurrence) to isolate performance drivers
- Novel Hybrid Architectures: Synthesized and tested new combinations of neural primitives for spatiotemporal forecasting
- RHN Superiority: Demonstrated that attention-augmented Recurrent Highway Networks outperform standard Transformers on high-dimensional chaotic systems
- Robustness Analysis: Validated models across both clean physics simulations and noisy real-world industrial datasets
The Engineering Problem
In modern ML, a common anti-pattern is the blind transfer of architectures from one domain (like NLP) to another (like physical forecasting) without understanding the underlying mechanics. This “black box” approach leads to suboptimal compute usage and performance ceilings.
My goal was to break these architectures down. I treated the core mechanisms of Transformers and RNNs (Gating, Attention, and Recurrence) as orthogonal basis vectors. By decoupling these components, we could synthesize and test hybrid architectures to find the optimal configuration for spatiotemporal forecasting.
Methodological Approach
We engineered a modular framework to mix and match neural primitives. We systematically evaluated:
- Gating Mechanisms: Testing Additive, Learned Rate, and Input-Dependent variants
- Attention: Implementing multi-headed attention with relative positional biases
- Recurrence: Testing standard cells (LSTM, GRU) against deeper transition cells like Recurrent Highway Networks (RHN)


This rigorous ablation study allowed us to isolate exactly which mathematical operation was driving performance gain.
Key Findings
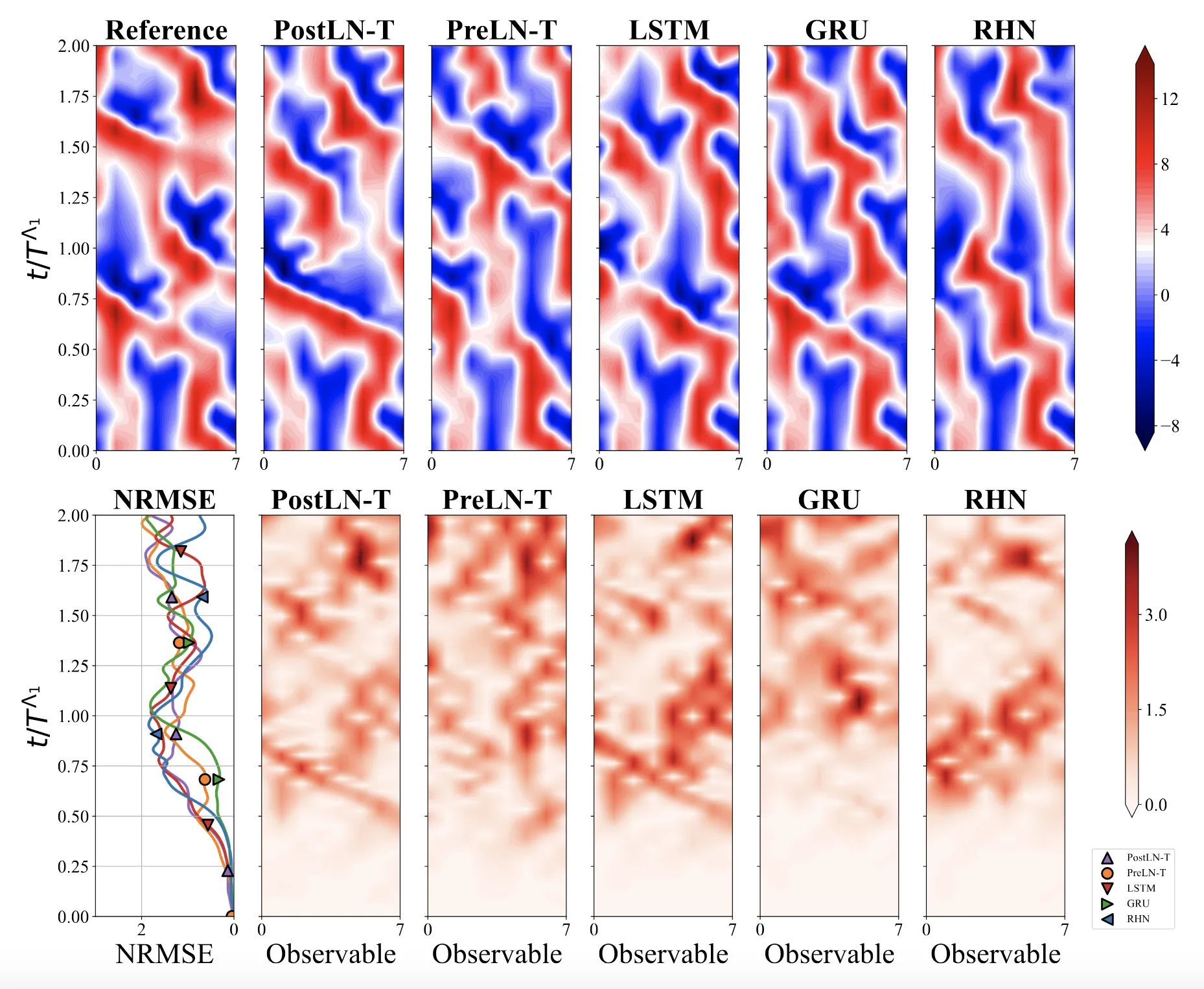
The RHN is a Sleeping Giant
The industry has pivoted hard to Transformers. To understand why this might be suboptimal for physics, one must look at the systems we are modeling.
For high-dimensional chaotic systems like the Multiscale Lorenz-96 shown below, we found that a Recurrent Highway Network (RHN) augmented with Attention and Neural Gating was the top-performing architecture. This novel hybrid exceeded the forecasting accuracy of standard Transformers, suggesting that deeper recurrence (processing depth per timestep) is crucial for complex dynamics.

Transformers: Recurrence Hurts, Gating Helps
We attempted to force recurrence into Transformers to give them “memory,” but it consistently hurt performance. However, Neural Gating significantly improved Transformer robustness. For real-world, noisy data (traffic, weather), the Pre-Layer Normalization (PreLN) Transformer with added gating proved to be the most robust model.
Augmenting the Old Guard
We tested on the Kuramoto-Sivashinsky equation, a model of turbulence and flame fronts. We found that legacy architectures (LSTMs, GRUs) are under-optimized. By adding modern Attention mechanisms to these older cells, we improved their performance by over 40% in some chaotic regimes.

Real-World Robustness: Beyond the Lab
While chaotic systems test the limits of theory, we also validated our models on seven standard industrial datasets, including Electricity Transformer Temperature (ETT), Traffic Flow, and Weather data.
Unlike the clean physics simulations, these datasets contain real-world noise and irregularities. In this environment, the Pre-Layer Normalization (PreLN) Transformer proved to be the most robust architecture. While it didn’t always beat the RHN on pure chaos, its stability makes it a strong default choice for general time-series forecasting tasks where training speed and reliability are paramount.
Why This Matters
This work demonstrates a move away from “state-of-the-art chasing” toward first-principles AI engineering.
- For Production: We identified that while Transformers train 25-50% faster, optimized RNNs offer superior inference accuracy for physical systems. This allows for informed trade-offs between training budget and deployment precision.
- For Research: We established that architectural components should be treated as tunable hyperparameters, not fixed constraints. By carefully selecting these mechanisms, practitioners can design models better suited for the specific challenges of dynamical systems forecasting.
The ablation framework here, treating architectural components as independently tunable factors and measuring their marginal contribution, shaped how later evaluation work is structured. The same principle of isolating variables rather than comparing end-to-end black boxes appears in the document processing research, from benchmark construction in page stream segmentation to grounded evaluation in GutenOCR.
Related Work
The methodology here shares a design philosophy with EigenNoise, which similarly decomposes a neural mechanism (word vector initialization) into theoretically grounded components to isolate what drives performance. Both papers treat model components as testable hypotheses rather than fixed architectural choices.
For broader context on where this fits in the portfolio’s Scientific Machine Learning arc, see the Research overview.
Citation
@misc{heidenreich2024deconstructingrecurrenceattentiongating,
title={Deconstructing Recurrence, Attention, and Gating: Investigating the transferability of Transformers and Gated Recurrent Neural Networks in forecasting of dynamical systems},
author={Hunter S. Heidenreich and Pantelis R. Vlachas and Petros Koumoutsakos},
year={2024},
eprint={2410.02654},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2410.02654}
}