
GutenOCR: A Grounded Vision-Language Front-End for Documents
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
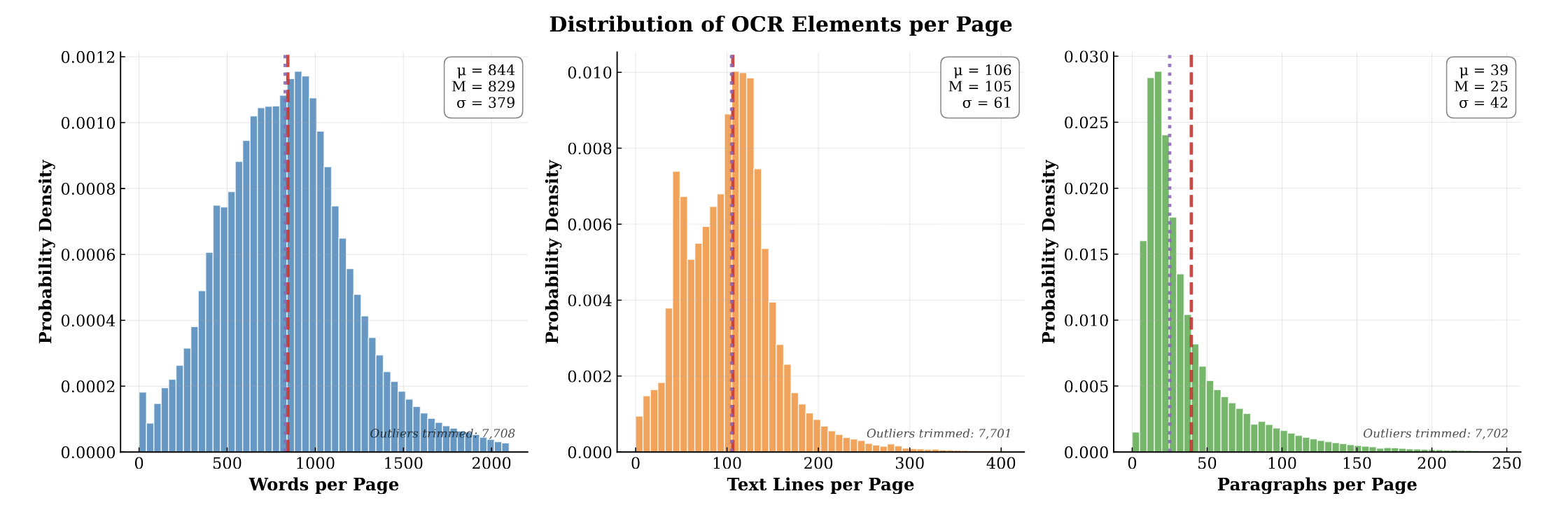
PubMed-OCR provides 1.5M pages of scientific articles with comprehensive OCR annotations and bounding boxes to support layout-aware modeling and document analysis.
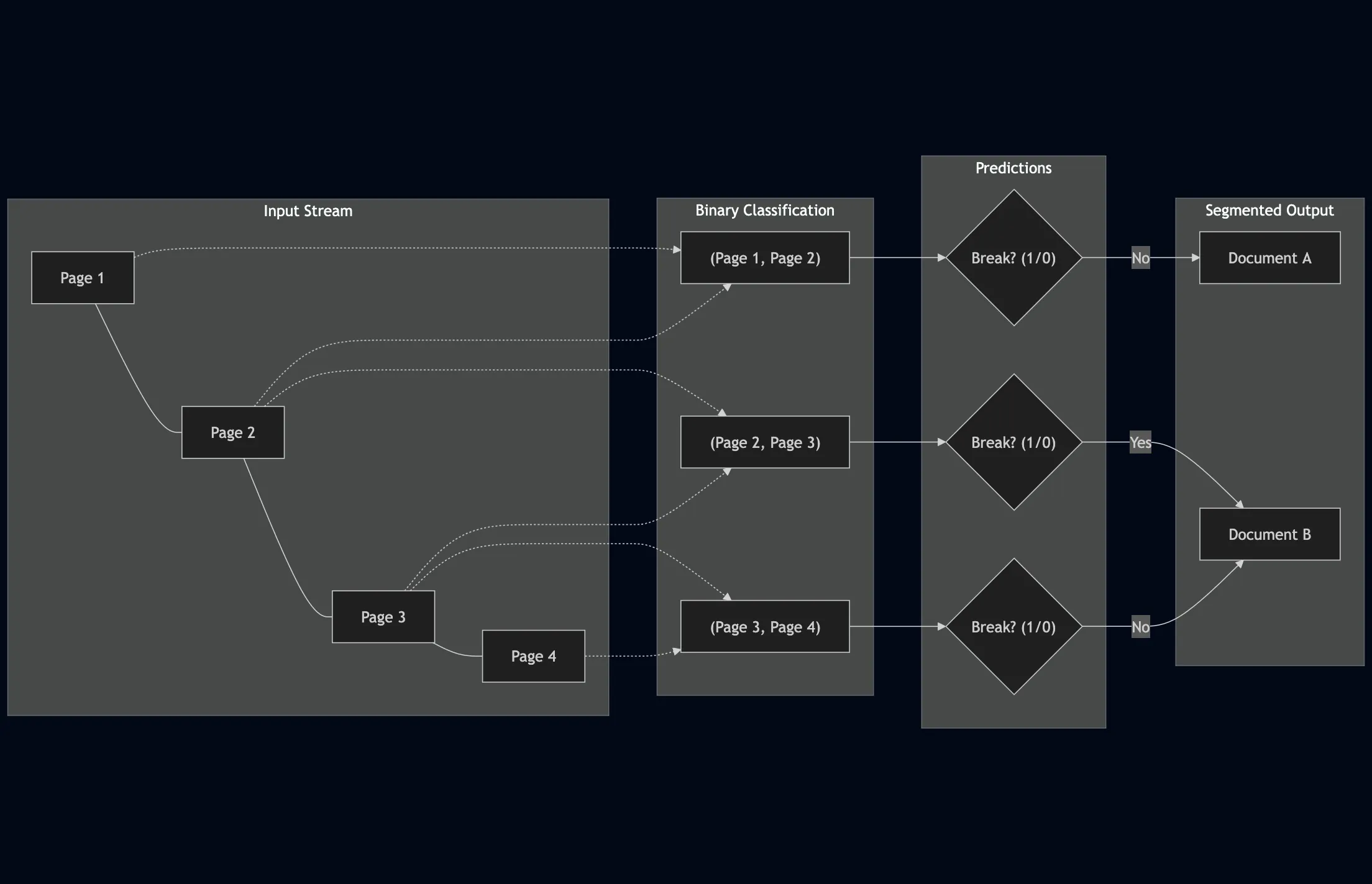
We explore LLM applications for page stream segmentation in insurance document processing, demonstrating that parameter-efficient fine-tuning achieves strong accuracy but revealing significant calibration challenges that limit deployment confidence.
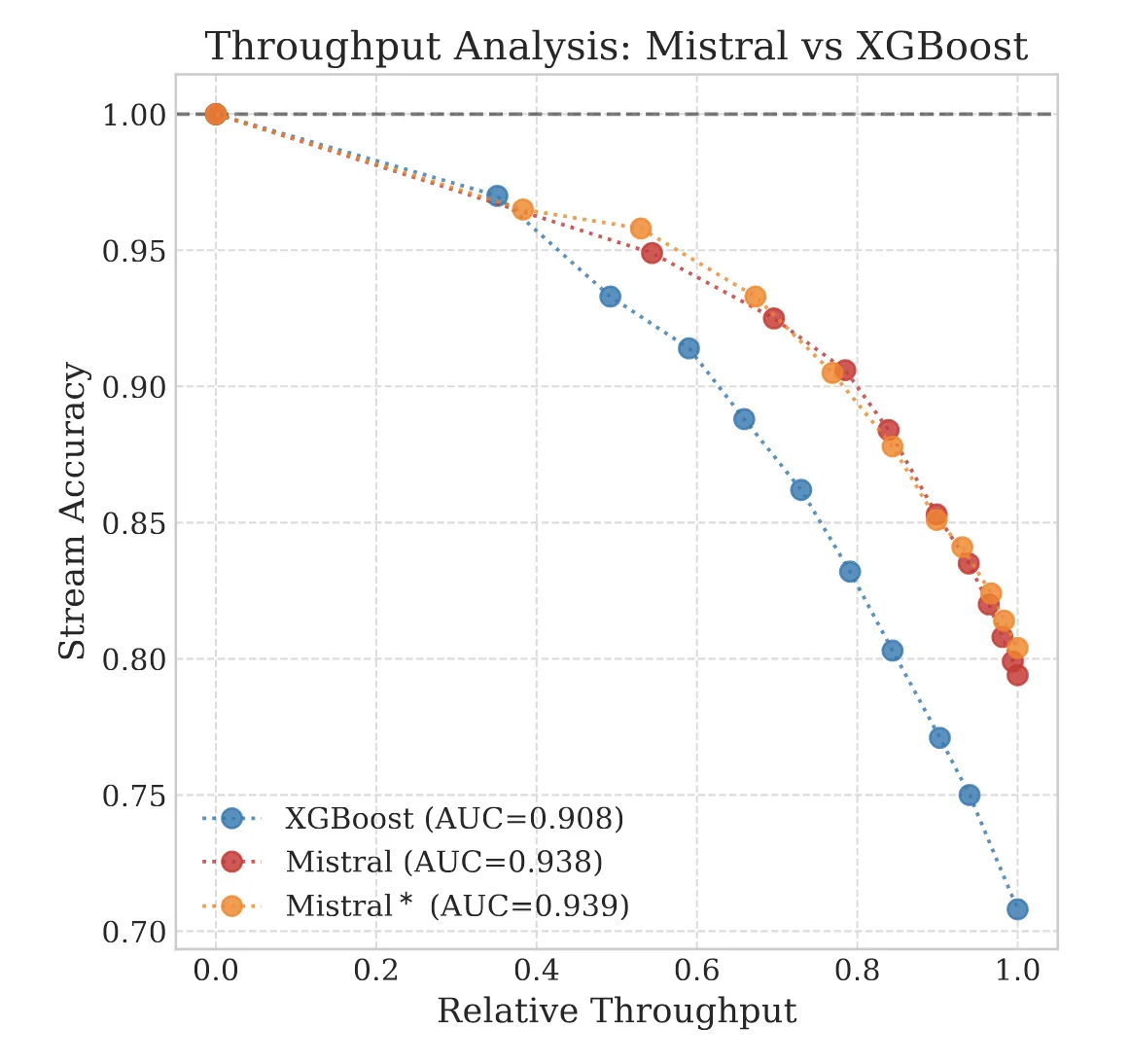
We create TabMe++, an enhanced page stream segmentation benchmark with commercial-grade OCR, and show that parameter-efficiently fine-tuned decoder-based LLMs like Mistral-7B achieve 80% straight-through processing rates, dramatically outperforming encoder-based models.
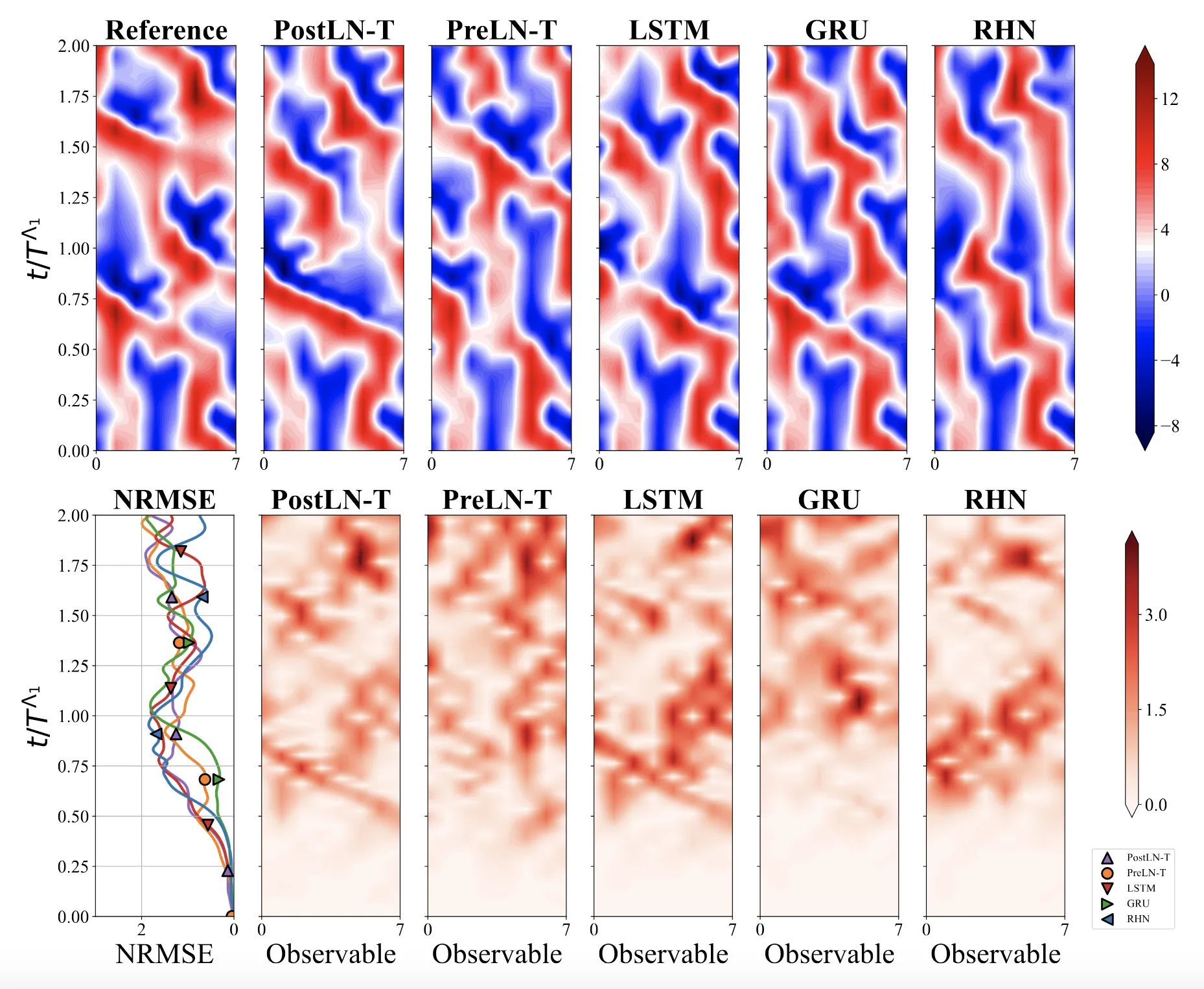
We systematically ablate core mechanisms of Transformers and RNNs, finding that attention-augmented Recurrent Highway Networks outperform standard Transformers on forecasting high-dimensional chaotic systems.
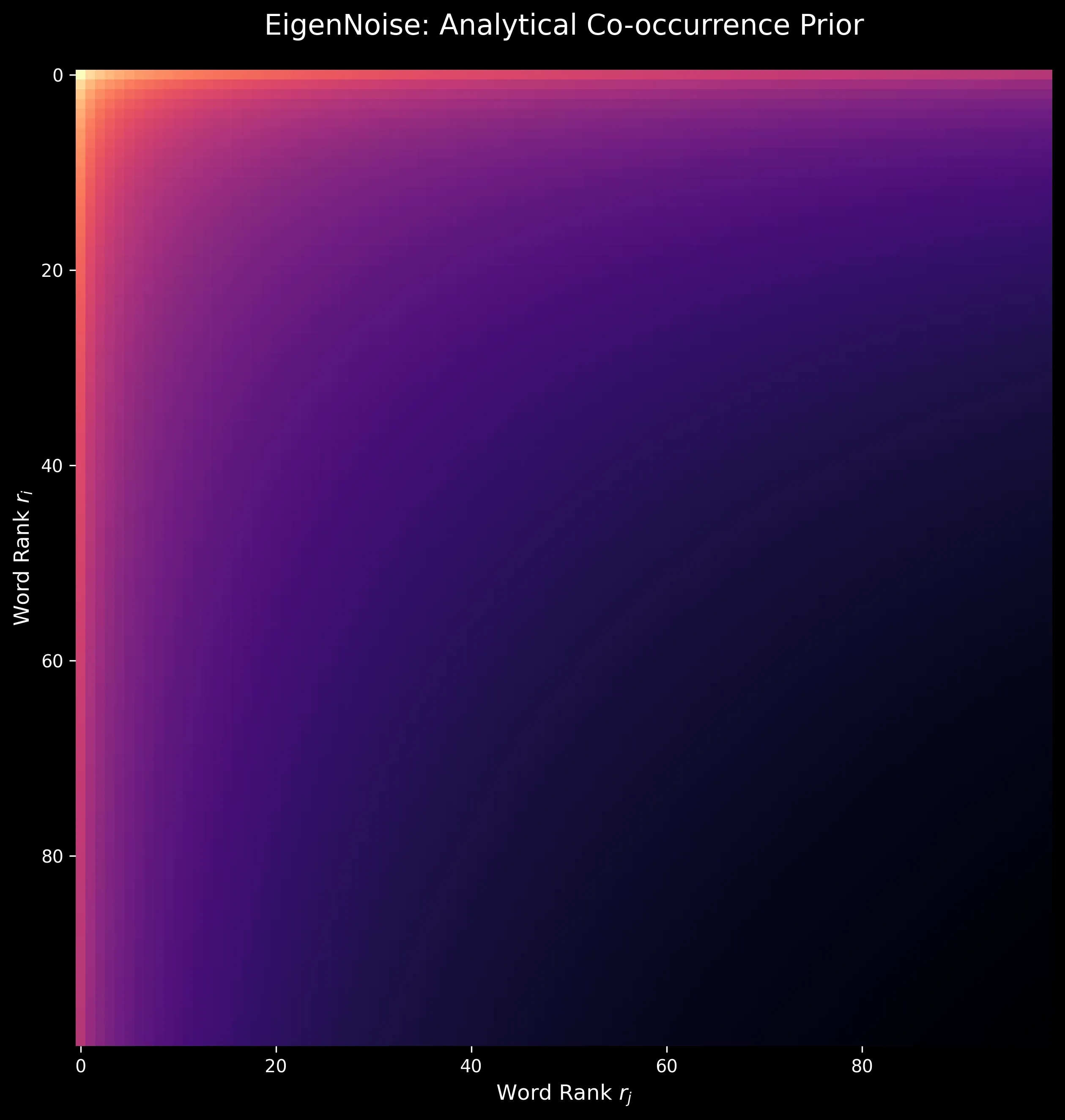
We develop EigenNoise, a zero-data initialization method for word vectors that synthesizes representations from Zipf’s Law alone, demonstrating competitive performance to GloVe after fine-tuning without requiring any pre-training corpus.
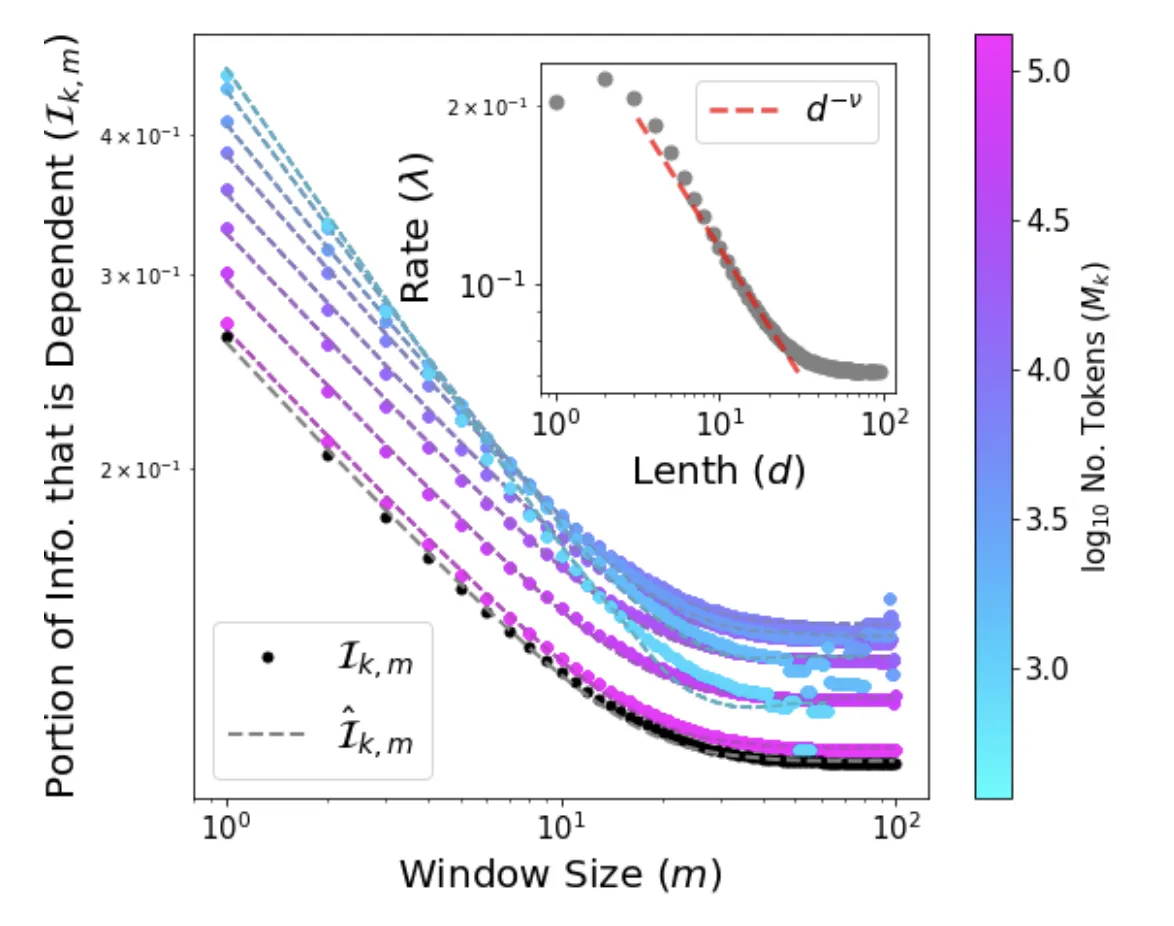
We provide the first analytical solution to Word2Vec’s softmax skip-gram objective, introducing the Independent Frequencies Model and deriving a low-cost, training-free method for measuring semantic bias directly from corpus statistics.
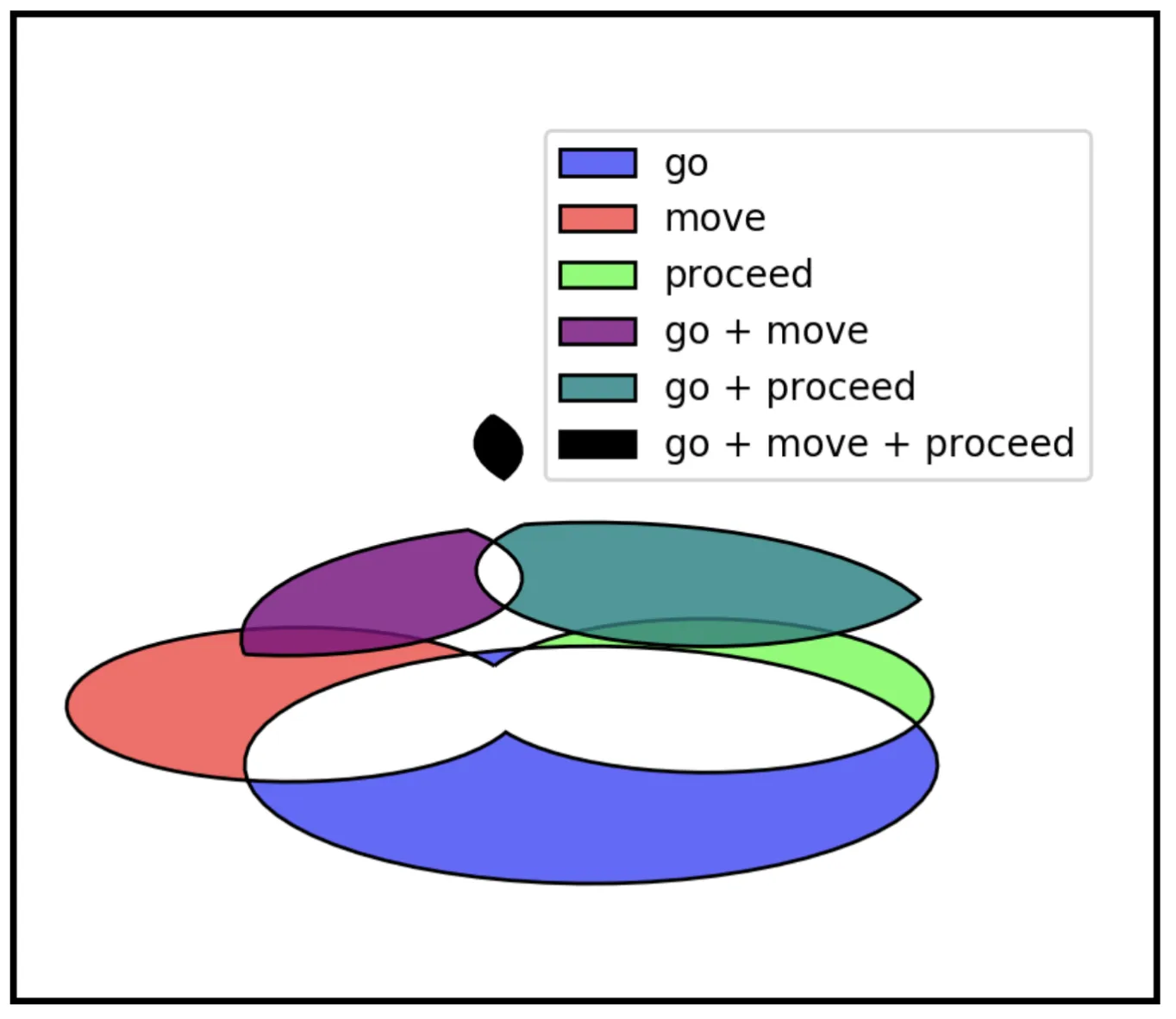
We present an unsupervised algorithm for inducing semantic networks from Wiktionary’s crowd-sourced data, creating a WordNet-like resource an order of magnitude larger than Princeton WordNet with over 344,000 linked example sentences.

Bachelor’s thesis introducing PyConversations, an open-source library that normalizes over 308 million posts from Twitter, Reddit, Facebook, and 4chan into a unified data model for cross-platform social media research.
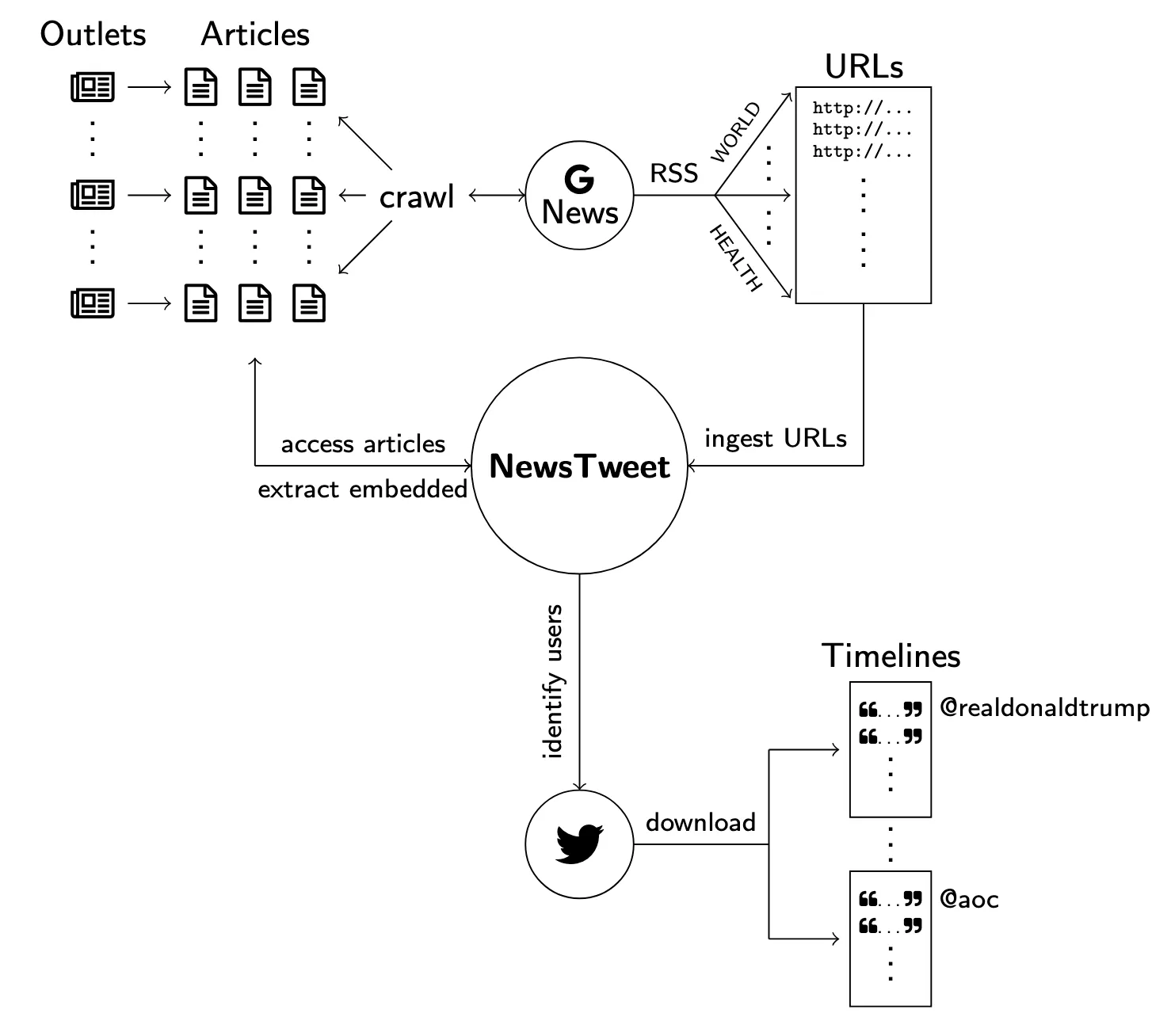
We introduce NewsTweet, a dataset and pipeline for studying embedded tweets in digital journalism, revealing that 13% of Google News articles incorporate tweets and providing insights into how social media becomes newsworthy.
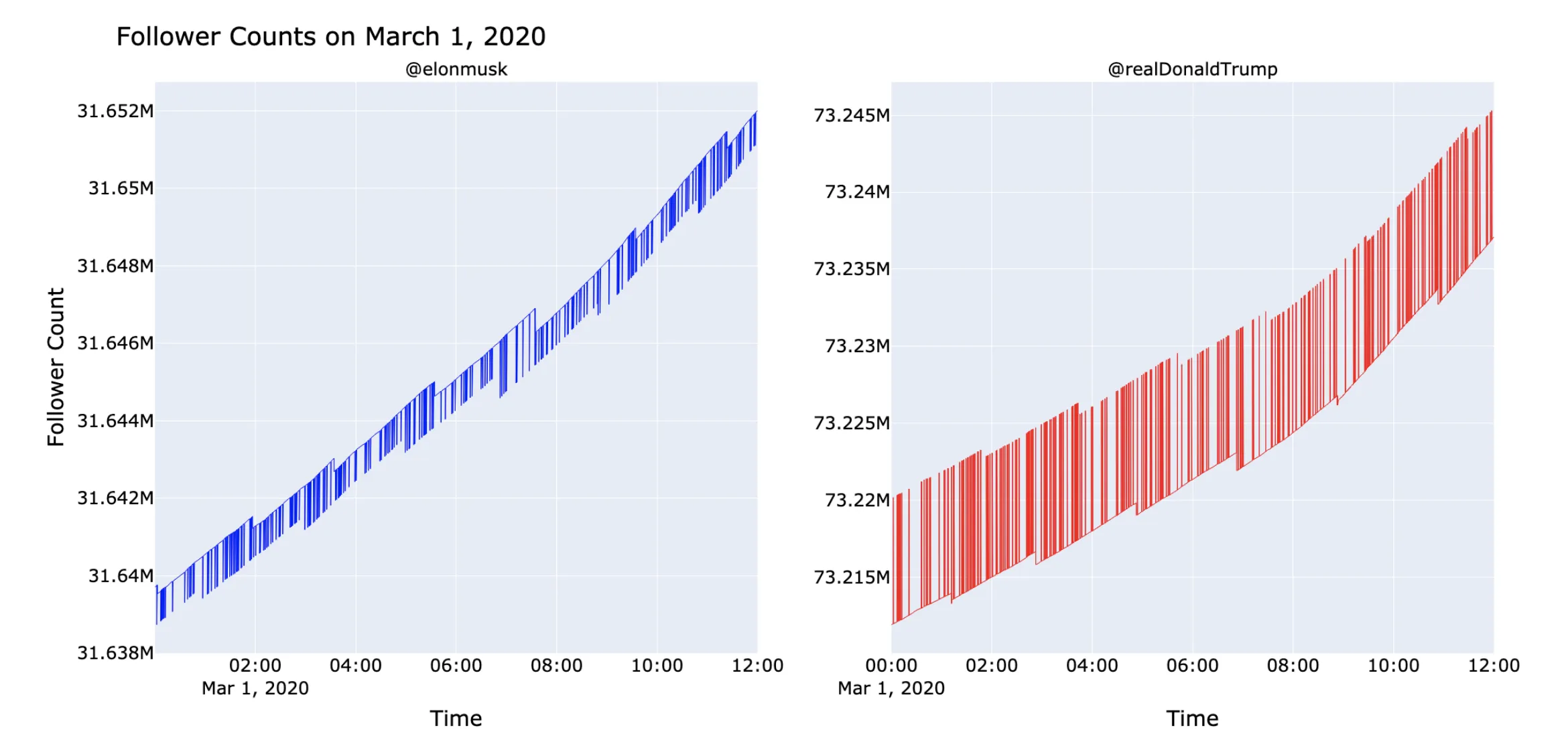
We developed high-frequency monitoring tools to detect coordinated manipulation on Twitter, documenting anomalous follower patterns including sub-second spikes, sawtooth waves, circulating accounts, and weaponized ancient dormant accounts targeting political figures.

We demonstrate that universal adversarial triggers can control both the topic and stance of GPT-2’s generated text, revealing security vulnerabilities in deployed language models and proposing constructive applications for bias auditing.