Overview
A computational social science project that constructed a dataset of 47,000+ US congressional bills by extracting legislative text and metadata from the 115th-117th Congresses. The project creates a “legislative graph” (linking sponsors, committees, and bill text) and establishes TF-IDF baseline models for policy area classification across 33 (highly imbalanced) policy classes, now hosted on Hugging Face to support reproducible political science research.
Features
Intelligent Data Acquisition
Standard APIs impose strict rate limits. I built a Selenium-based extraction engine to handle Congress.gov’s complex DOM structures.
- Optimization: Targeted aggregate endpoints (e.g.,
/all-info) to pull each bill’s text and metadata in fewer requests. - Resilience: Implemented a local caching layer to store raw HTML, separating the fetch step from the parse step. This made the parse step re-runnable without re-fetching, and minimized server load during iterative development.
- Graph construction: Beyond simple text, the script extracts relational data including co-sponsorship networks, committee assignments, and related bill lineage.
Natural Language Processing
- Corpus construction: Cleaned and normalized legislative text, removing procedural artifacts (e.g., “A BILL TO…”) to isolate semantic policy content.
- Feature engineering: Utilized TF-IDF vectorization with N-gram analysis to capture legislative jargon.
- Modeling: Benchmarked Naive Bayes, Logistic Regression, and gradient-boosted trees (XGBoost), reaching ~0.86 weighted F1 on bill summaries and up to ~0.89 on full text (cross-validated). Weighted F1, not raw accuracy, is the honest metric here: the 33 policy classes are severely imbalanced (Health has 5,911 bills; Social Sciences and History has 15).
Usage
The dataset is available on Hugging Face and can be loaded directly via the datasets library. The scraper can be run locally to fetch new bills.
Results
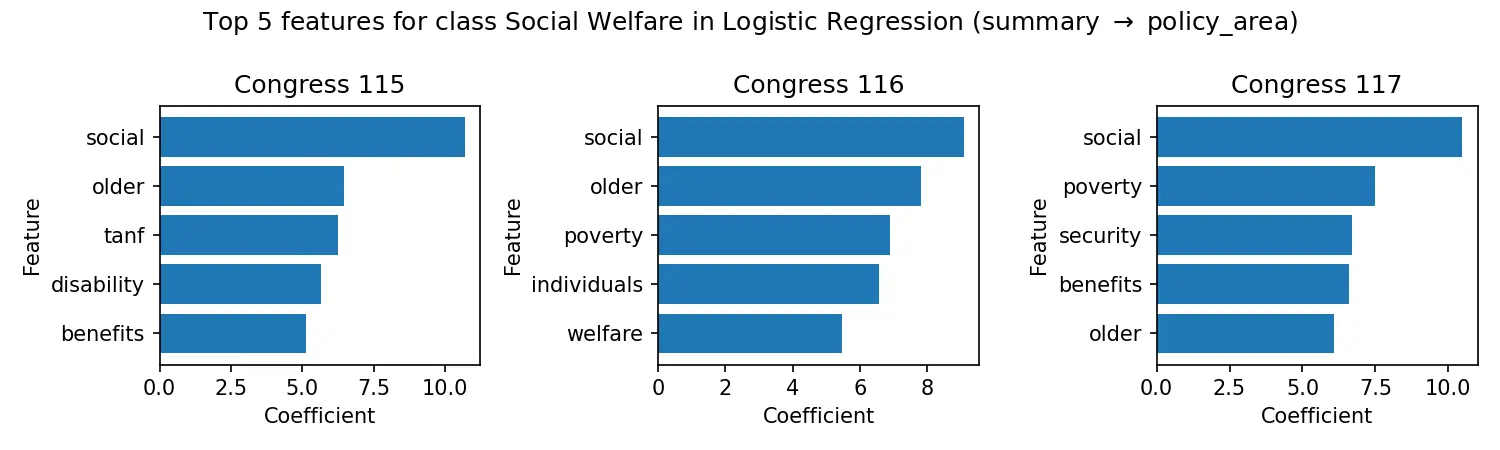
- The “partisan vocabulary”: Feature importance analysis revealed distinct linguistic markers separating Democratic and Republican legislation, identifiable even without metadata.
- Temporal drift: Policy priorities and terminology showed measurable shifts across congressional sessions (115th vs 117th).
- Classification success: Simple linear models (Logistic Regression and Naive Bayes) proved effective at distinguishing policy domains, outperforming gradient-boosted trees on these sparse TF-IDF features and suggesting legislative language is highly structured.
Impact & Deliverables
- Hugging Face dataset: Released a machine-readable, ML-ready dataset of modern bills (115th-117th Congresses) on Hugging Face for reproducible research.
- Open source tooling: Published the scraper and parsing logic to allow others to extend the dataset to future congresses.
- Academic benchmark: Establishing a clear baseline for “Government NLP” tasks, aiding in the automated transparency and monitoring of new legislation.