Overview
A computational social science project that constructed a dataset of 47,000+ US congressional bills by extracting legislative text and metadata from the 115th-117th Congresses. The project creates a novel “legislative graph” (linking sponsors, committees, and bill text) and establishes a machine learning benchmark for policy area classification (87% accuracy), now hosted on Hugging Face to support reproducible political science research.
Features
Intelligent Data Acquisition
Standard APIs impose strict rate limits. I engineered a custom Selenium-based extraction engine to handle Congress.gov’s complex DOM structures.
- Optimization: Targeted aggregate endpoints (e.g.,
/all-info) to reduce HTTP request volume by ~90% per bill. - Resilience: Implemented a local caching layer to store raw HTML, separating the fetch step from the parse step. This ensured 100% reproducibility and minimized server load during iterative development.
- Graph construction: Beyond simple text, the script extracts relational data including co-sponsorship networks, committee assignments, and related bill lineage.
Natural Language Processing
- Corpus construction: Cleaned and normalized legislative text, removing procedural artifacts (e.g., “A BILL TO…”) to isolate semantic policy content.
- Feature engineering: Utilized TF-IDF vectorization with N-gram analysis to capture legislative jargon.
- Modeling: Benchmarked Naive Bayes, Logistic Regression, and SVMs, achieving 87.3% accuracy on policy area prediction (cross-validated).
Usage
The dataset is available on Hugging Face and can be loaded directly via the datasets library. The scraper can be run locally to fetch new bills.
Results
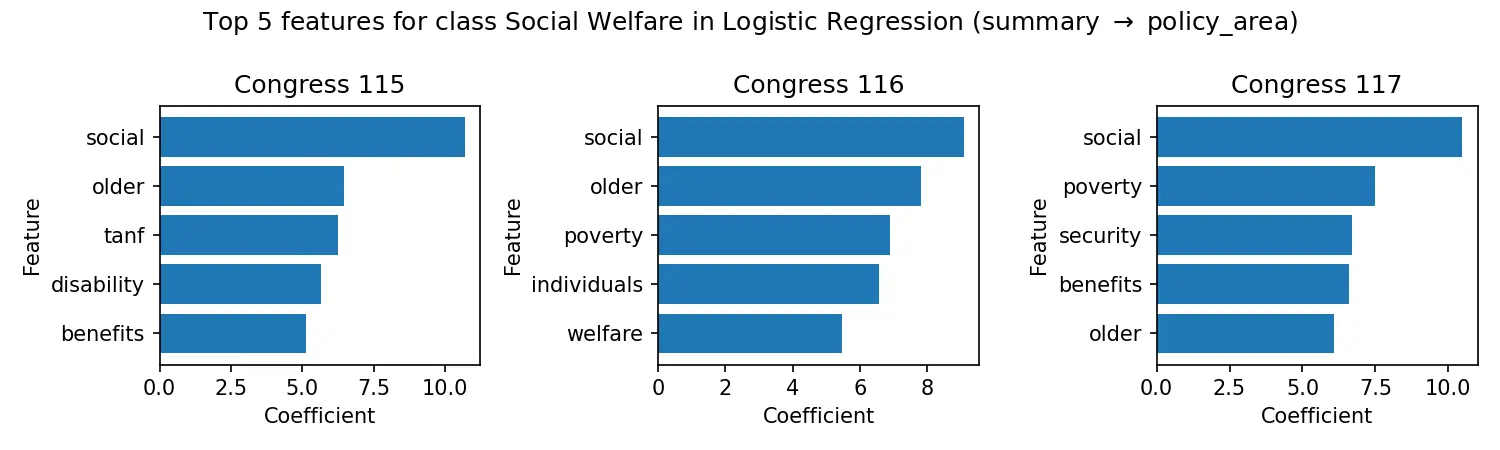
- The “partisan vocabulary”: Feature importance analysis revealed distinct linguistic markers separating Democratic and Republican legislation, identifiable even without metadata.
- Temporal drift: Policy priorities and terminology showed measurable shifts across congressional sessions (115th vs 117th).
- Classification success: Simple linear models (SVM/LogReg) proved remarkably effective at distinguishing policy domains, suggesting legislative language is highly structured.
Impact & Deliverables
- Hugging Face dataset: Released the first machine-readable, ML-ready dataset of modern bills, democratizing access for researchers.
- Open source tooling: Published the scraper and parsing logic to allow others to extend the dataset to future congresses.
- Academic benchmark: Establishing a clear baseline for “Government NLP” tasks, aiding in the automated transparency and monitoring of new legislation.