Note from 2026: I originally wrote these notes in 2018 while studying for my undergraduate AI final. They cover classic symbolic AI (often called Good Old-Fashioned AI, or GOFAI). Looking back from the current era of Large Language Models (LLMs) and Vision-Language Models (VLMs), it is fascinating to see how these foundational concepts have evolved. The classic “knowledge base” and “Ask/Tell” operations conceptually mirror modern Retrieval-Augmented Generation (RAG) systems, and the classic problem of logical “grounding” is exactly what we tackle today with multimodal visual grounding in models like GutenOCR. I have preserved and merged these notes here as a time capsule of my learning journey.
The Evolution of Knowledge-Based Systems
Early AI research focused heavily on knowledge bases and agents that could interact with them, leading to expert systems. These systems relied on central knowledge bases to make decisions through “if-then” reasoning patterns. While some consider expert systems the first major AI breakthrough, others debate whether they truly belong in the AI category.
Knowledge-based agents remain relevant in modern AI. If you’ve worked in natural language processing, you’ve likely encountered knowledge bases like WordNet. Wikipedia represents another massive knowledge base, encoding semantic relationships between countless entities.
This abundance of knowledge bases raises important questions: How do we build agents that effectively interface with these repositories? How can they update knowledge bases and make decisions based on stored information?
This article explores these questions through a practical introduction to knowledge-based agents, knowledge representation, and logic.
Anatomy of a Knowledge-Based Agent
An agent is any entity that acts within an environment. In AI, we build rational agents. Entities that act sensibly within their environment. In well-understood environments, rational agents choose actions that yield desired outcomes. In uncertain environments, they act to maximize expected positive outcomes.
Consider agents that maintain internal knowledge, reason over that knowledge, and update their understanding through observations and actions. This is the foundation of knowledge-based agents.
Knowledge Bases: The Foundation
The core component of any knowledge-based agent is its knowledge base (KB): the repository of what the agent knows about the world.
Every KB consists of sentences. These are statements written in a knowledge representation language. These specialized languages express assertions about the world in formats that enable systematic reasoning.
Knowledge representation languages are designed for systematic representation of world knowledge. This is why we use these specialized languages for agent knowledge bases.
Types of Knowledge in a KB
Axioms are foundational sentences assumed to be true without derivation from other KB content. If you’re familiar with mathematics, this concept will feel natural.
Inferred sentences are derived from existing KB content through logical reasoning. These are systematically derived using reasoning rules that may be built into the knowledge representation language itself.
Core Agent Operations
Knowledge-based agents interact with their KBs through two fundamental operations: Ask and Tell.
Ask: Querying Knowledge
Ask is how agents extract information from their KB. When an agent asks a “question” or queries its KB, it must format the request in the KB’s expected format (typically in the knowledge representation language).
The KB responds with sentences that are either:
- Directly stored in the KB, or
- Inferred from existing KB information
This guarantees that responses never contradict the KB’s knowledge.
Tell: Adding Knowledge
Tell updates the KB with new information. Agents use this when they:
- Observe environmental changes
- Update the KB with planned or completed actions
- Add newly learned facts
Like Ask operations, new information must be properly formatted. The KB stores the new sentence and may trigger reasoning and inference processes to derive additional conclusions.
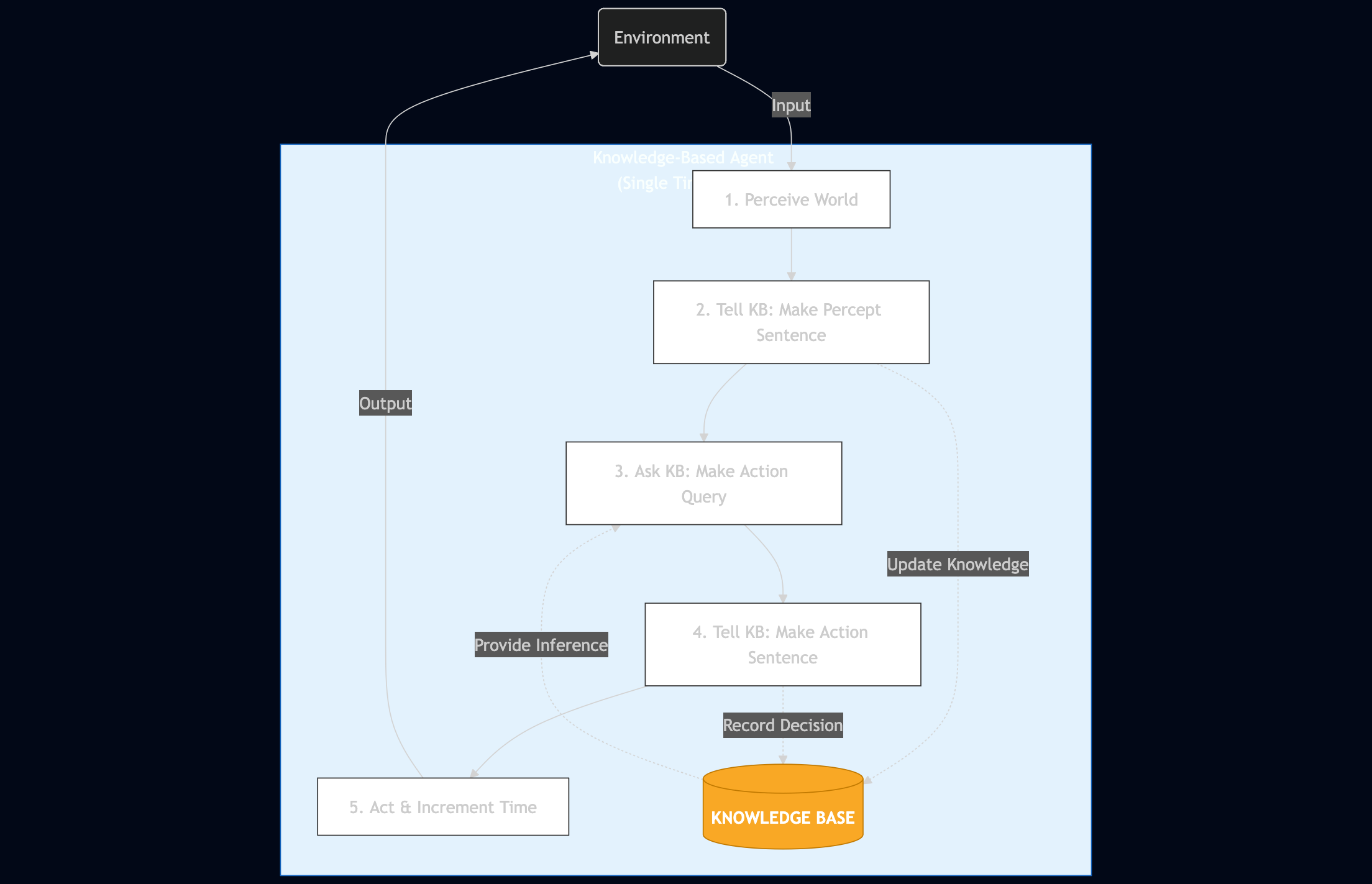
A Generic Knowledge-Based Agent Architecture
Here’s a high-level view of how a knowledge-based agent operates:
def kb_agent(percept):
Tell(KB, make_percept_sentence(percept, t))
action = Ask(KB, make_action_query(t))
Tell(KB, make_action_sentence(action, t))
t = t + 1
return action
This function illustrates the agent’s reasoning cycle:
- Perceive: Convert environmental observations into KB-compatible sentences via
make_percept_sentence() - Reason: Query the KB for the appropriate action using
make_action_query() - Act: Record the chosen action in the KB through
make_action_sentence() - Update: Increment the time step and return the action
The helper functions handle the crucial task of translating between the external world and the knowledge representation language. This architecture focuses purely on the reasoning process, the “brains” of the operation, while abstracting away perception and action execution details.
Design Perspectives for Knowledge-Based Agents
Knowledge-based agents can be analyzed and designed from three distinct levels, each addressing different aspects of the system.
Knowledge Level: The Strategic View
The knowledge level represents the highest level of analysis, focusing on:
- Goals: What objectives does the agent pursue?
- Knowledge scope: How much does the agent know about its world initially?
This level helps us understand the agent’s capabilities and limitations from a strategic perspective, independent of implementation details.
Logical Level: The Representation View
The logical level examines how knowledge is represented and reasoned about:
- Knowledge representation language: Which language best suits our domain?
- Logical framework: Are we using propositional logic, first-order logic, or something else?
Each choice carries trade-offs. Some languages excel at expressing certain types of knowledge but struggle with others. The logical framework determines what kinds of reasoning the agent can perform.
Implementation Level: The Technical View
The implementation level addresses the concrete technical decisions:
- Data structures: How is knowledge stored? (structs, databases, objects, vectors?)
- Algorithms: Which inference procedures are used?
- Performance: How do design choices affect speed and memory usage?
These decisions significantly impact the agent’s practical performance and scalability.
Learning and Knowledge Acquisition
Declarative vs. Procedural Approaches
Knowledge-based agents can be constructed through two primary approaches:
Declarative approach: Initialize the agent with an empty KB, then systematically Tell it all the knowledge it needs. This explicit knowledge encoding offers transparency and modularity.
Procedural approach: Write programs that encode knowledge directly into the agent’s behavior. This approach can be more efficient but less transparent.
Real-world systems typically benefit from combining both approaches, leveraging the strengths of each method.
Incorporating Learning
Learning enhances knowledge-based agents in several ways:
Perceptual learning: Agents can learn to combine observations in novel ways, creating new sentences that improve goal achievement. These learned patterns become part of the KB for future reasoning.
Inference optimization: Learning algorithms can identify efficient reasoning paths within existing KBs, speeding up the inference process.
Knowledge base expansion: Research continues into generating new connections in existing KBs like WordNet. As semantic webs proliferate online, efficient methods for KB expansion become increasingly valuable.
The integration of learning with knowledge-based reasoning represents an active area of AI research, with promising applications in knowledge graph completion, automated reasoning, and intelligent system adaptation.
The Components of Logic
Every logical system has three components that create a framework for representing and reasoning about knowledge.
Syntax: The Rules of Formation
Syntax defines how sentences are constructed, the rules that determine if a sentence is well-formed.
Consider English: “name Hunter mine is” violates syntax rules, while “my name is Hunter” follows them. In mathematics, “1+=2 3” breaks syntax, but “1+2=3” follows it.
Knowledge bases need proper syntax because they’re built from collections of sentences.
Semantics: The Meaning Behind Sentences
While syntax governs structure, semantics determines meaning, whether a sentence is true or false in a given context.
The sentence “my name is Hunter” is true in our context, but “my name is Paul” would be false. In math, “x=5” is true only when x actually equals 5.
We use model to describe a specific world state where variables have particular values. Different models let us evaluate sentence truth. One model might have x=4, another x=5.
When a sentence is true under a model, the model satisfies the sentence. If model₅ has x=5, then model₅ satisfies x=5.
For any sentence A, $M(A)$ represents all models that satisfy A.
Entailment: Logical Relationships
Entailment enables reasoning. When sentence A entails sentence B (written $A \models B$), B must be true whenever A is true.
More precisely, A entails B if B is true in every model where A is true:
- A is the premise
- B is the consequent
- B is a necessary consequence of A
Example: x=1 entails xy=y. If x equals 1, then xy will always equal y, regardless of y’s value.
This helps knowledge bases reason. When we’re uncertain about xy=y but add x=1 to our KB, entailment lets us assert that xy=y is now true.
To check if a KB entails sentence A, we verify that $M(KB) \subseteq M(A)$, every model satisfying our KB also satisfies A.
When we add sentences to our KB, we need systematic ways to discover newly entailed sentences. Inference algorithms do this work.
Inference Algorithms: Deriving New Knowledge
Inference algorithms systematically derive new sentences entailed by our knowledge base. These algorithms need two properties to be useful and trustworthy.
Soundness: Truth Preservation
An inference algorithm is sound if it only derives sentences actually entailed by the KB. If an algorithm adds unjustified sentences, it is fabricating information, undermining the KB’s reliability.
Completeness: Finding Everything
A complete inference algorithm finds all sentences entailed by the KB, missing no valid conclusions. This ensures we don’t overlook important logical consequences.
Achieving both soundness and completeness grows challenging as environments become more complex. Small, bounded models make this manageable. Unbounded environments require sophisticated algorithms that guarantee both properties while maintaining reasonable performance.
Grounding: Connecting Logic to Reality
Beyond formal algorithm properties lies a practical concern: grounding. Is our knowledge base actually grounded in reality? Does it accurately represent what’s true?
Grounding depends on how knowledge enters the system:
- Sensors: Agent perceptions are only as accurate as their sensors
- Learning algorithms: Learned sentences are only as reliable as the learning process
With accurate sensors and robust learning, we can trust our KB’s grounding. This remains important when deploying knowledge-based systems in real applications.
Conclusion
Logic provides the foundation for knowledge representation in AI systems. Understanding syntax (forming valid sentences), semantics (sentence meaning), entailment (how conclusions follow from premises), and inference algorithms (deriving new knowledge) enables building robust knowledge-based agents.
The interplay between these components, governed by soundness, completeness, and grounding, determines how effectively our AI systems represent and reason about the world.