Classifying Congressional Bills with Machine Learning
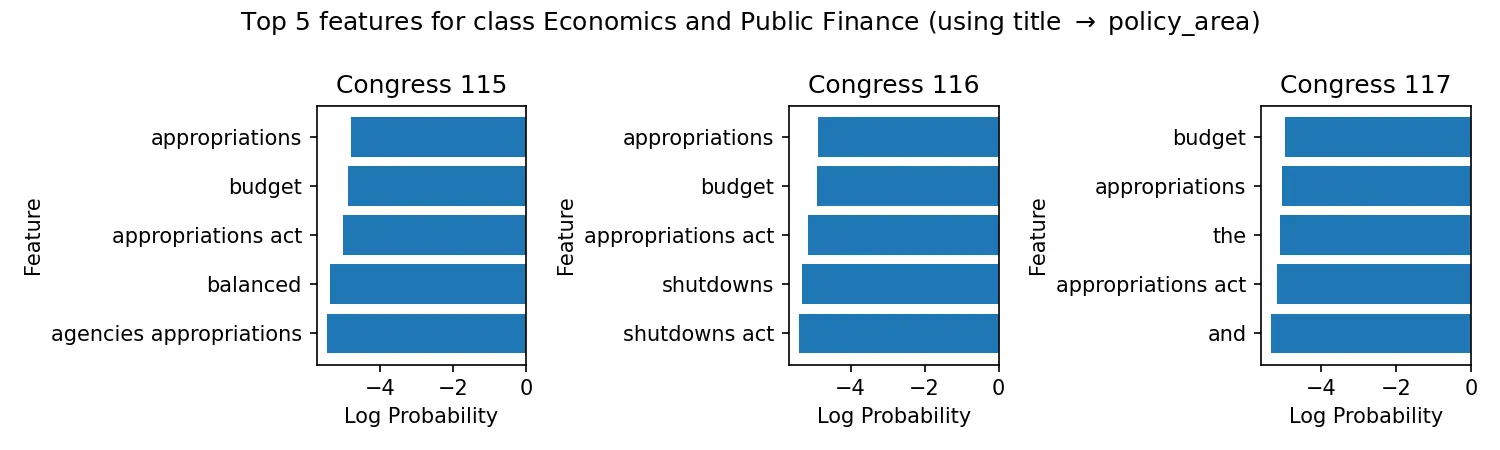
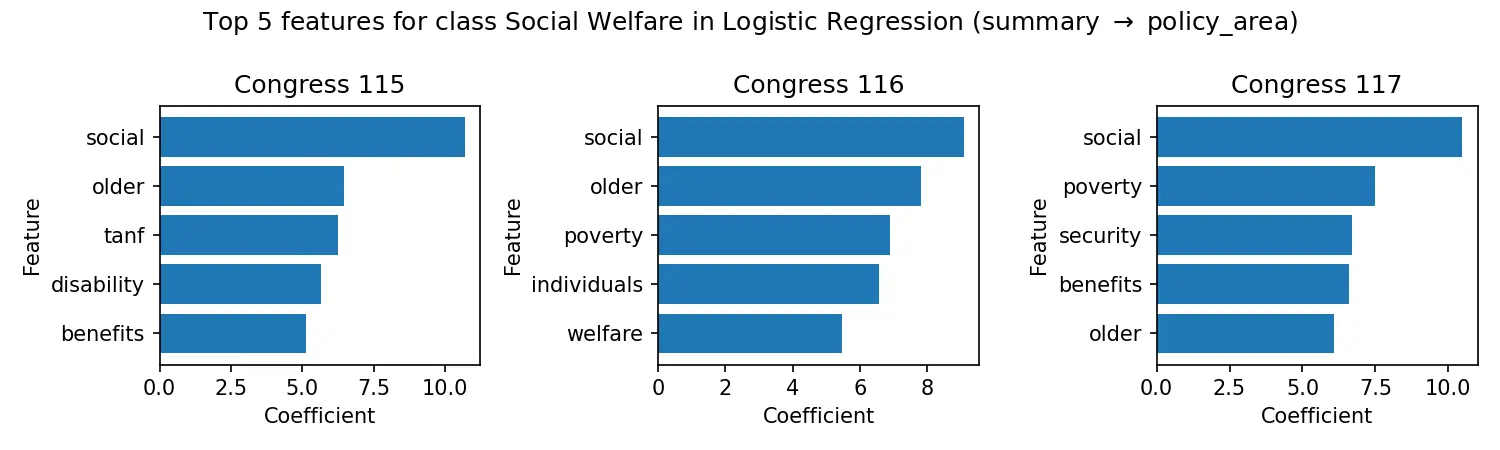
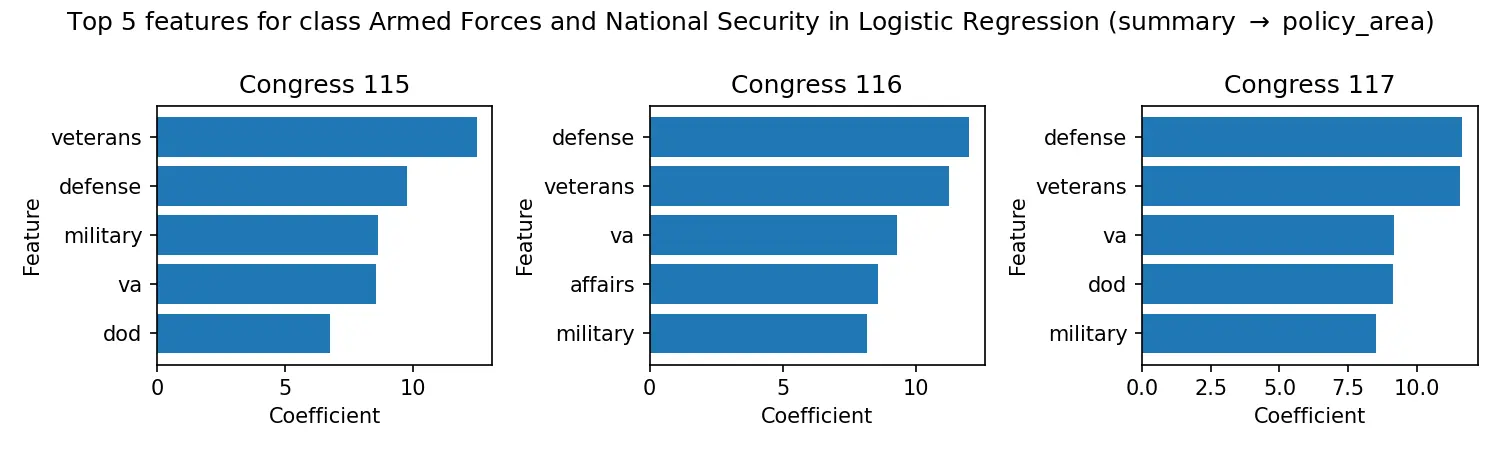
We test three ML models on 48K congressional bills to see how well they can predict policy areas from bill text. Results show logistic regression performs best, with a certified weighted-F1 of ~0.88 within-Congress (0.877) and ~0.87 out-of-Congress (0.871).