Can Recurrent Neural Networks Warp Time? (ICLR 2018)
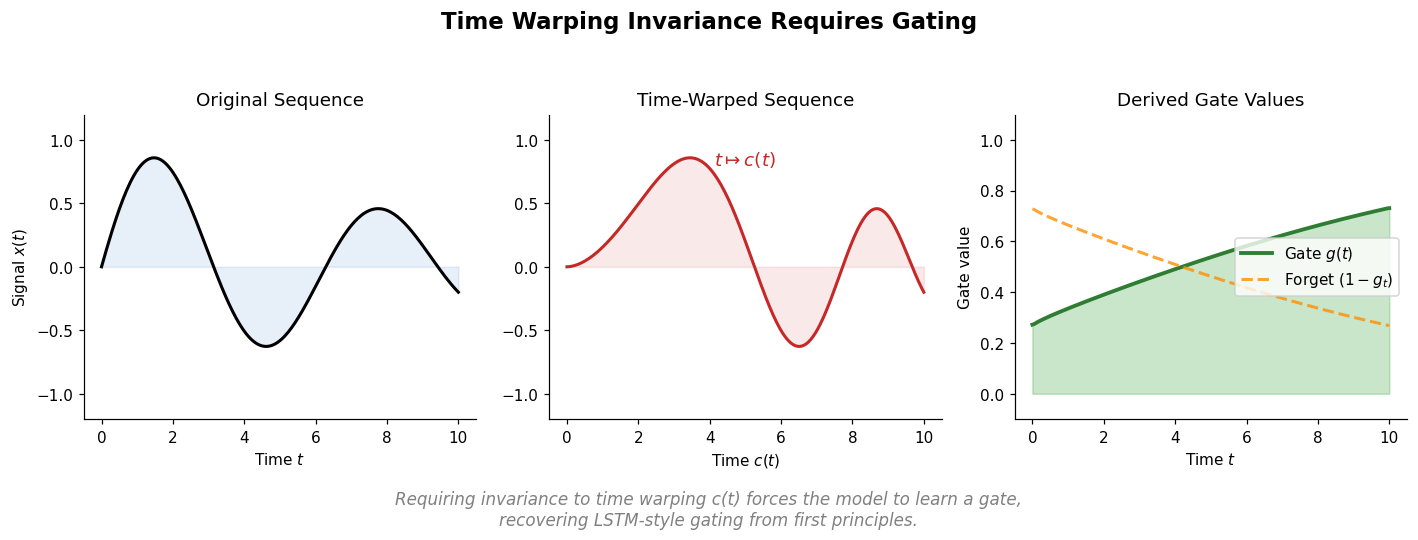
Tallec and Ollivier show that requiring invariance to time transformations in recurrent models leads to gating mechanisms, recovering key LSTM components from first principles. They propose the chrono initialization for gate biases that improves learning of long-term dependencies.