BARTSmiles: BART Pre-Training for Molecular SMILES
BARTSmiles pre-trains a BART-large model on 1.7 billion SMILES strings from ZINC20 and achieves the best reported results on 11 classification, regression, and generation benchmarks.
BARTSmiles pre-trains a BART-large model on 1.7 billion SMILES strings from ZINC20 and achieves the best reported results on 11 classification, regression, and generation benchmarks.
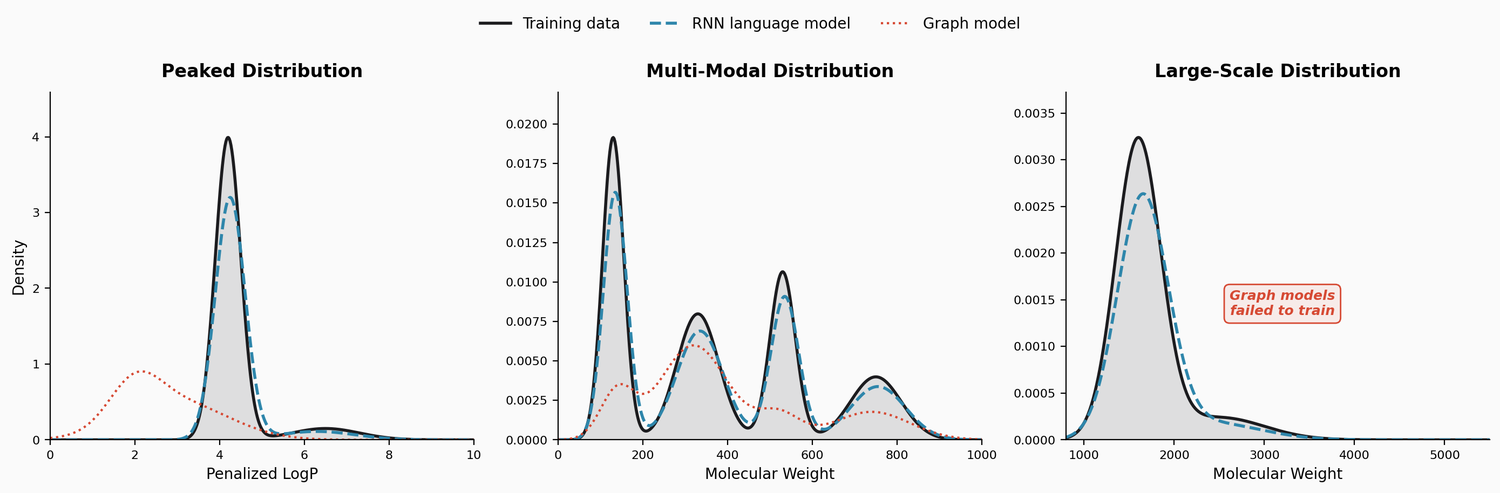
This study benchmarks RNN-based chemical language models against graph generative models on three challenging tasks: high penalized LogP distributions, multi-modal molecular distributions, and large-molecule generation from PubChem. The LSTM language models consistently outperform JTVAE and CGVAE.
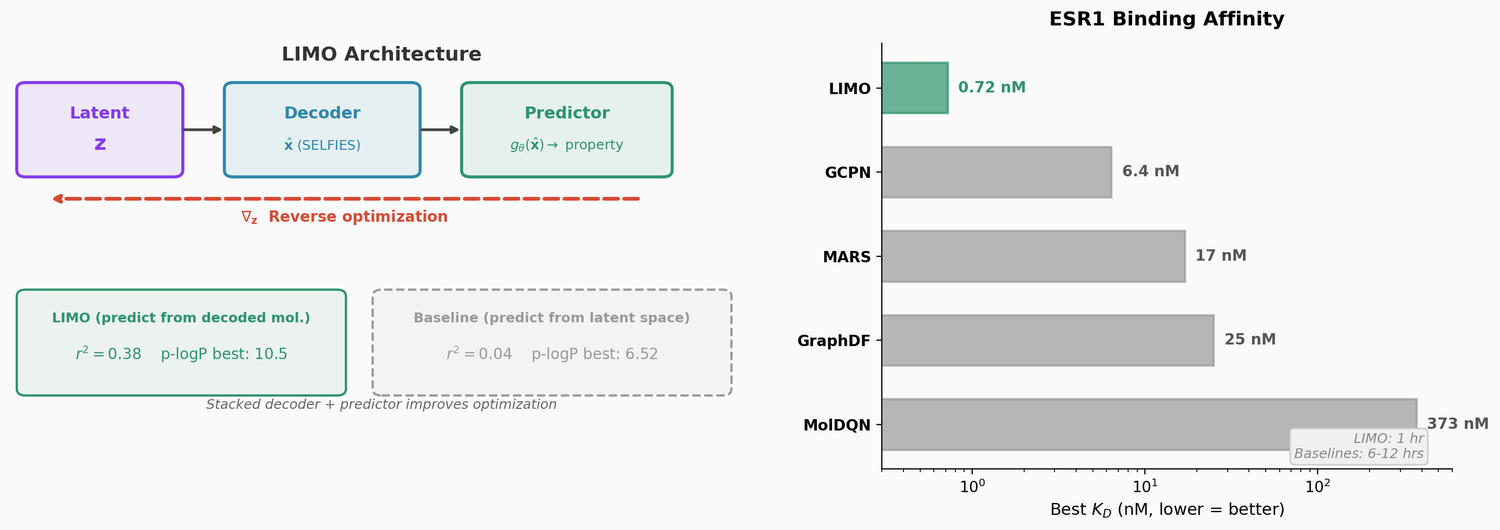
LIMO combines a SELFIES-based VAE with a novel stacked property predictor architecture (decoder output as predictor input) and gradient-based reverse optimization on the latent space. It is 6-8x faster than RL baselines and 12x faster than sampling methods while generating molecules with nanomolar binding affinities, including a predicted KD of 6e-14 M against the human estrogen receptor.
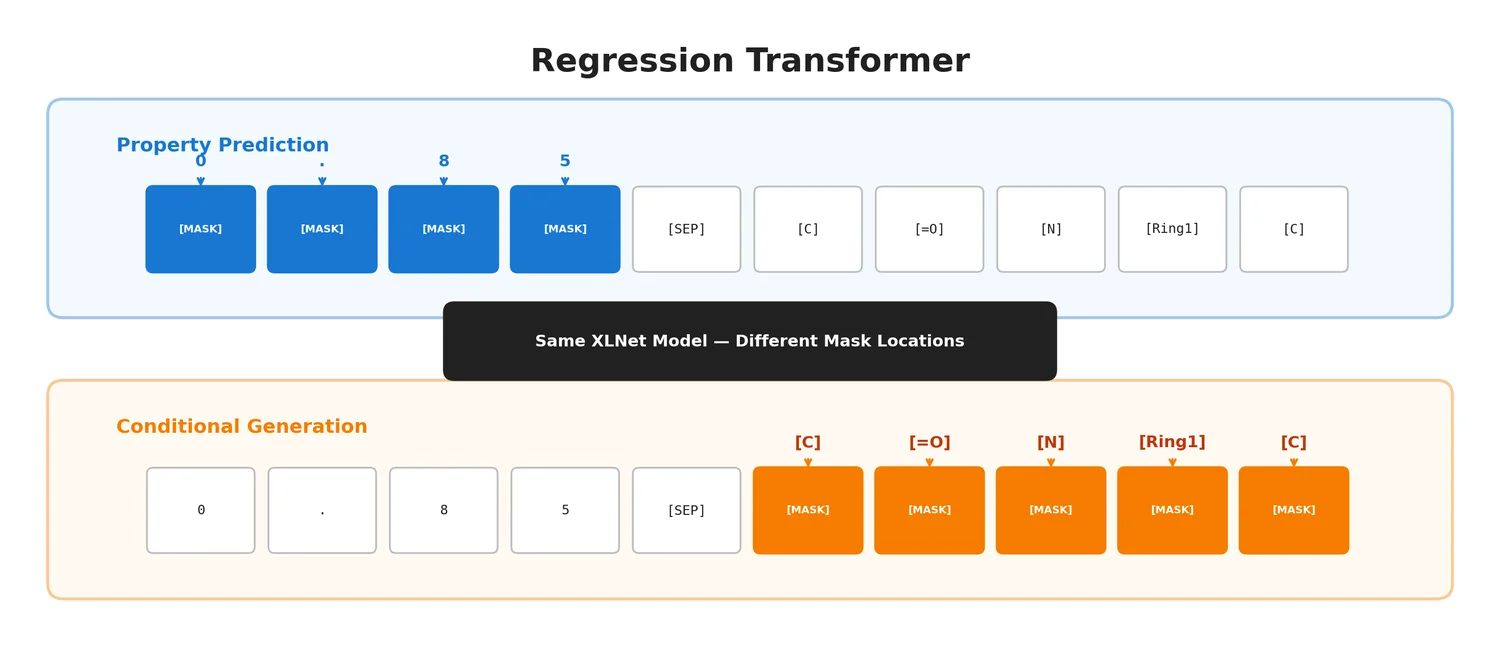
The Regression Transformer (RT) reformulates regression as conditional sequence modelling, enabling a single XLNet-based model to both predict continuous molecular properties and generate novel molecules conditioned on desired property values.
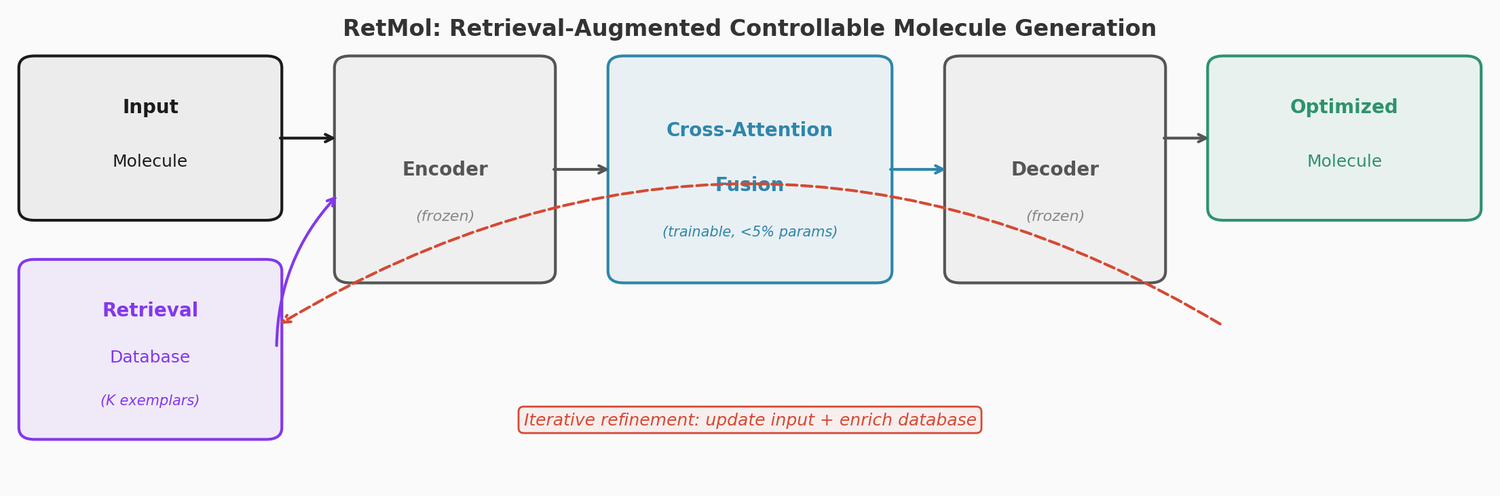
RetMol plugs a lightweight cross-attention retrieval module into a pre-trained Chemformer backbone to guide molecule generation toward multi-property design criteria. It requires no task-specific fine-tuning and works with as few as 23 exemplar molecules. It achieves 94.5% success on QED optimization, 96.9% on GSK3b/JNK3 dual inhibitor design, and 2.84 kcal/mol average binding affinity improvement on SARS-CoV-2 main protease inhibitor optimization.
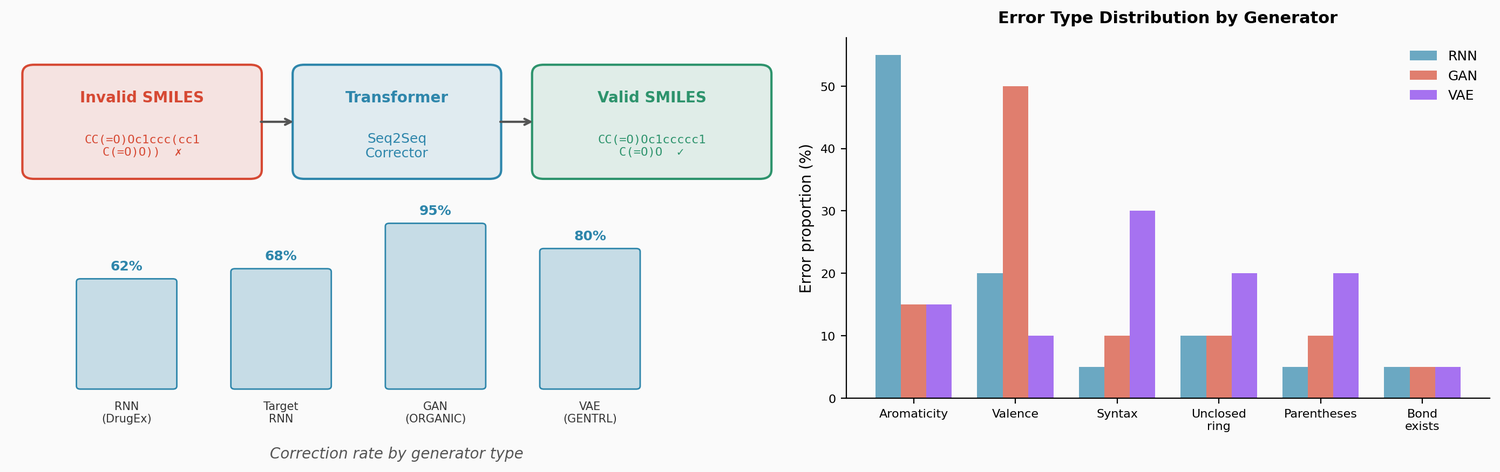
This paper trains a transformer model to correct invalid SMILES produced by de novo molecular generators (RNN, VAE, GAN). The corrector fixes 60-95% of invalid outputs, and the fixed molecules are comparable in novelty and similarity to valid generator outputs. The approach also enables local chemical space exploration by introducing and correcting errors in existing molecules.
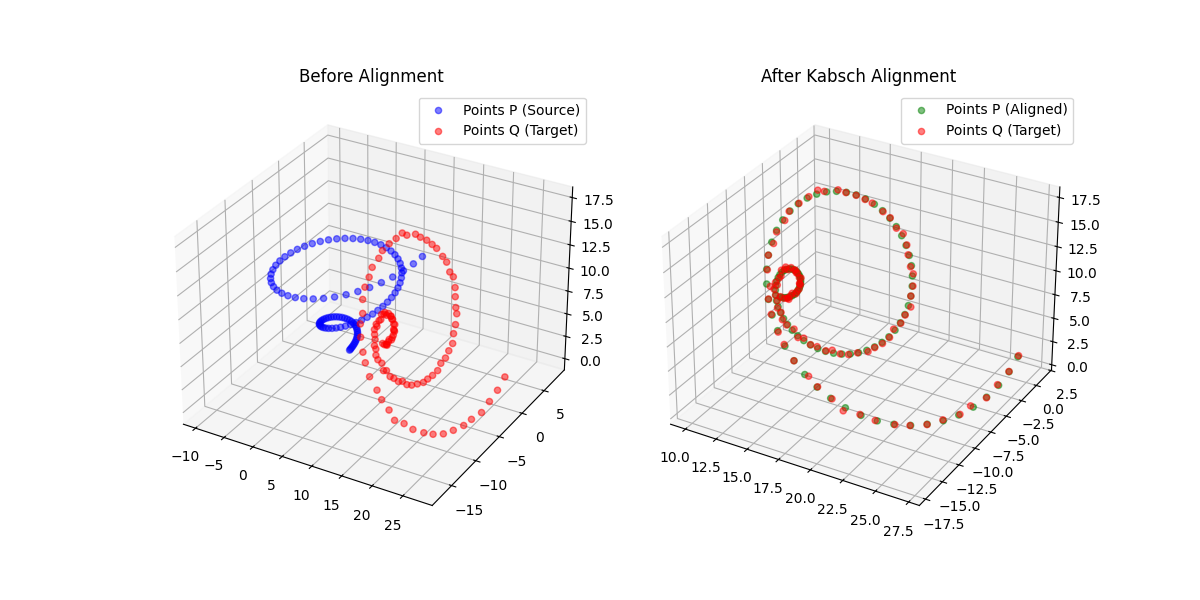
A differentiable point-set alignment library implementing N-dimensional Kabsch, Horn quaternion, and Umeyama scaling algorithms with per-point weights, batch dimensions, and custom autograd across NumPy, PyTorch, JAX, TensorFlow, and MLX.
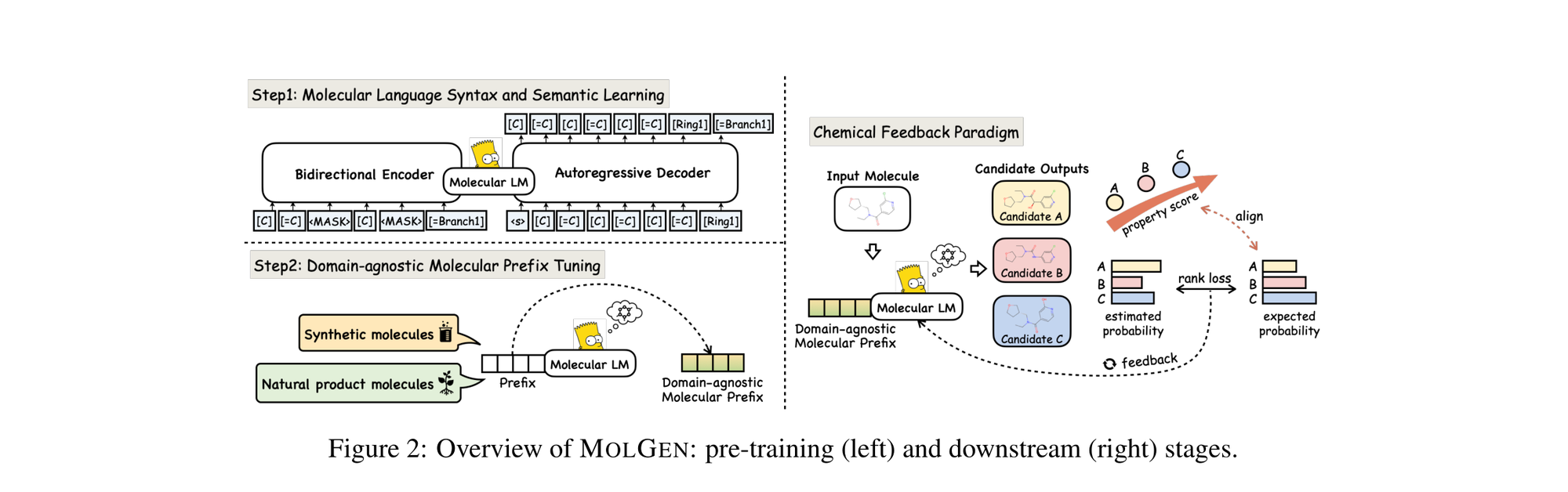
MolGen pre-trains on 100M+ SELFIES molecules, introduces domain-agnostic prefix tuning for cross-domain transfer, and applies a chemical feedback paradigm to reduce molecular hallucinations.
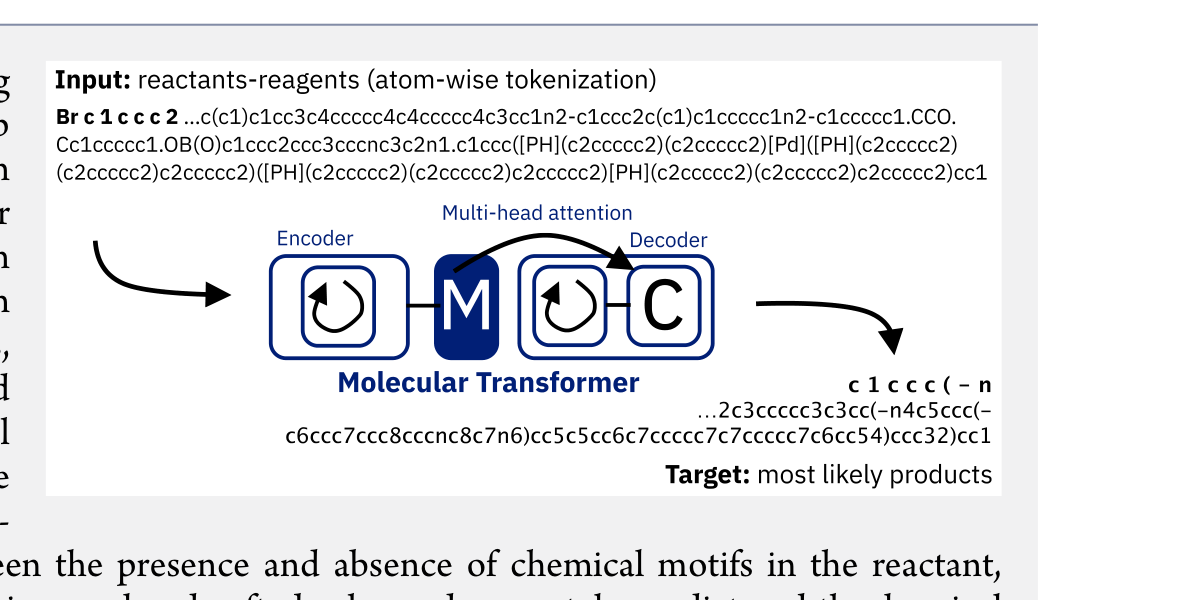
The Molecular Transformer applies the Transformer architecture to forward reaction prediction, treating it as SMILES-to-SMILES machine translation. It achieves 90.4% top-1 accuracy on USPTO_MIT, outperforms quantum-chemistry baselines on regioselectivity, and provides calibrated uncertainty scores (0.89 AUC-ROC) for ranking synthesis pathways.
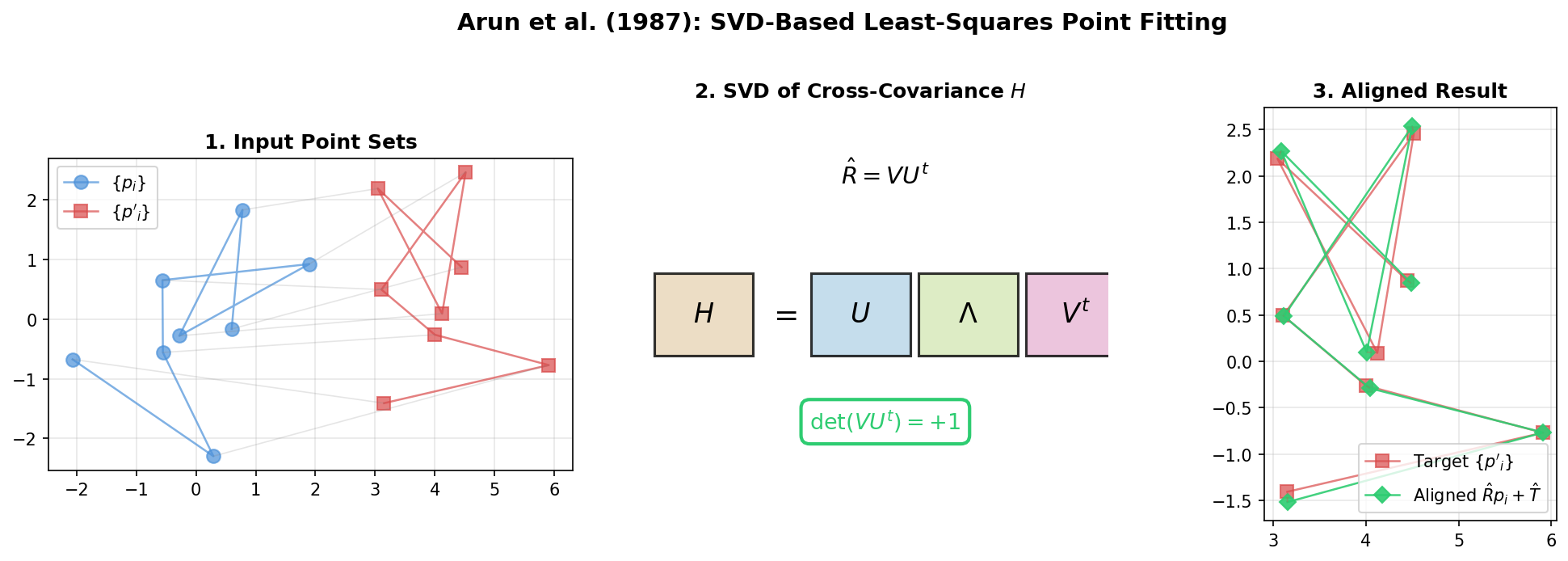
Presents a concise SVD-based algorithm for finding the optimal rotation and translation between two 3D point sets, with analysis of the degenerate reflection case that Umeyama later corrected.
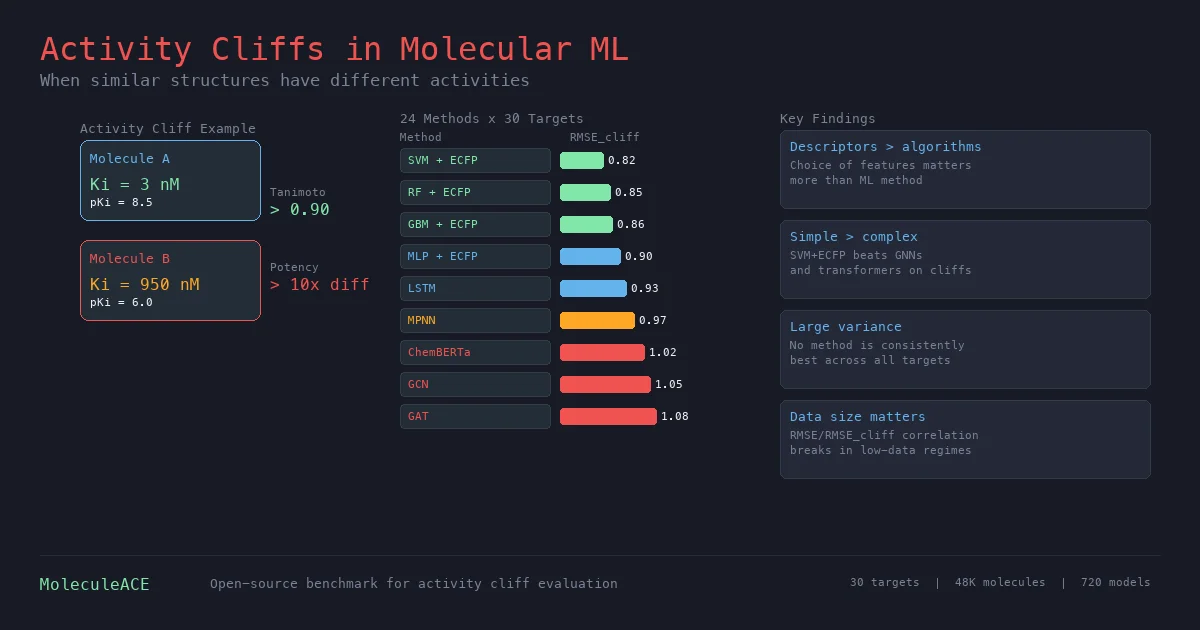
This paper benchmarks 24 machine and deep learning methods on activity cliff compounds (structurally similar molecules with large potency differences) across 30 macromolecular targets. Traditional ML with molecular fingerprints consistently outperforms graph neural networks and SMILES-based transformers on these challenging cases, especially in low-data regimes.
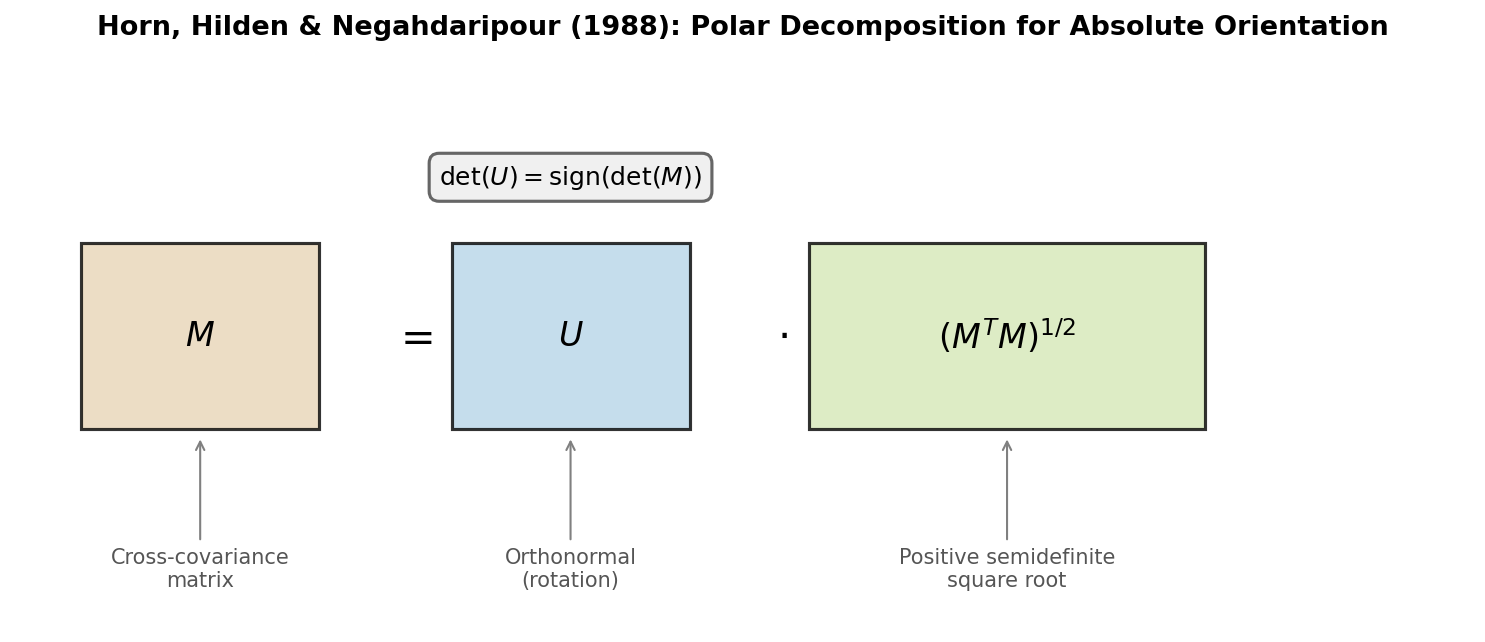
The matrix-based companion to Horn’s 1987 quaternion method, deriving the optimal rotation as the orthonormal factor in the polar decomposition of the cross-covariance matrix via eigendecomposition of a 3x3 symmetric matrix.