A systematic study of NLP transfer learning
This is a systematization paper that provides a comprehensive empirical survey of transfer learning techniques for NLP. Rather than proposing a single new method, T5 introduces a unified text-to-text framework and uses it as a testbed to systematically compare pre-training objectives, architectures, unlabeled data sources, transfer approaches, and multi-task mixing strategies. The scale of the ablation study (covering dozens of configurations) and the release of C4, pre-trained models, and code make it both a reference guide and a resource.
Unifying NLP tasks as text-to-text
The core design decision is to cast every NLP task as a text-to-text problem: both the input and output are text strings, with a task-specific prefix. Classification, regression, summarization, translation, and question answering all use the same model, loss function (cross-entropy on output tokens), and decoding procedure. This simplicity enables fair comparison across tasks and training strategies.
The model architecture is a standard encoder-decoder Transformer. The paper finds that this form outperforms decoder-only (language model) and encoder-only (BERT-style) variants in the text-to-text setting, while having similar computational cost to decoder-only models despite twice the parameters (the encoder processes the input only once, then the decoder attends to it).
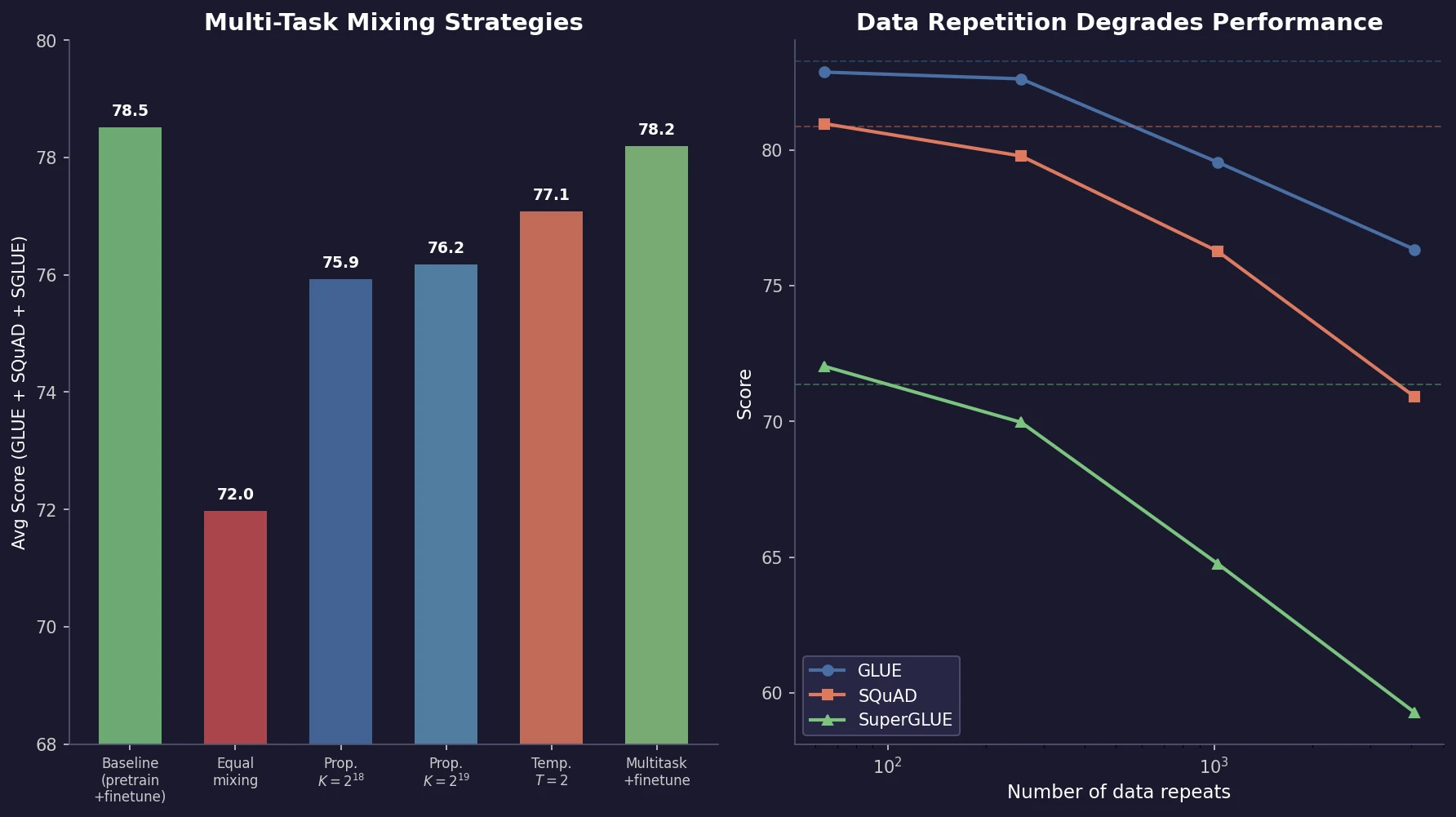
Multi-task mixing: strategies and findings
The most thesis-relevant contribution is the systematic ablation of multi-task mixing strategies (Section 3.5.2). When training on multiple tasks simultaneously (which in the text-to-text framework simply means mixing data from different sources), the central question is how to set the proportion of data from each task.
Three mixing strategies
Examples-proportional mixing. Sample in proportion to each dataset’s size, with an artificial cap $K$ on the maximum dataset size. Without the cap, the unsupervised pre-training data (orders of magnitude larger) would dominate all batches. The mixing rate for task $m$ is:
$$ r_{m} = \frac{\min(e_{m}, K)}{\sum_{n} \min(e_{n}, K)} $$
where $e_{m}$ is the number of examples in task $m$’s dataset.
Temperature-scaled mixing. Raise each mixing rate $r_{m}$ to the power $1/T$ and renormalize. At $T=1$ this equals examples-proportional mixing; as $T$ increases, proportions approach equal mixing. Uses a large cap $K = 2^{21}$.
Equal mixing. Sample uniformly from all tasks. Included as a negative reference: the model overfits on low-resource tasks and underfits on high-resource tasks.
Results
| Mixing strategy | GLUE | CNN/DM | SQuAD | SuperGLUE | EnDe | EnFr | EnRo |
|---|---|---|---|---|---|---|---|
| Baseline (pre-train/fine-tune) | 83.28 | 19.24 | 80.88 | 71.36 | 26.98 | 39.82 | 27.65 |
| Equal | 76.13 | 19.02 | 76.51 | 63.37 | 23.89 | 34.31 | 26.78 |
| Examples-proportional, $K=2^{18}$ | 81.67 | 19.07 | 78.17 | 67.94 | 24.57 | 35.19 | 27.39 |
| Examples-proportional, $K=2^{19}$ | 81.42 | 19.24 | 79.78 | 67.30 | 25.21 | 36.30 | 27.76 |
| Temperature-scaled, $T=2$ | 81.90 | 19.28 | 79.42 | 69.92 | 25.42 | 36.72 | 27.20 |
Key findings on mixing:
Multi-task training underperforms pre-train-then-fine-tune on most tasks. No mixing strategy matches the baseline of unsupervised pre-training followed by task-specific fine-tuning.
Equal mixing is worst. It dramatically degrades performance, confirming that proportions matter.
There exists a task-specific sweet spot for the cap $K$. Most tasks have an optimal $K$ value; larger or smaller values hurt. The exception is very high-resource tasks (WMT English-French) that always benefit from higher mixing proportions.
Temperature scaling at $T=2$ provides the best single compromise. It achieves reasonable performance across all tasks without requiring per-task tuning of $K$.
Multi-task pre-training followed by fine-tuning closes the gap. When multi-task training is used as pre-training (not as the final training stage), followed by task-specific fine-tuning, performance becomes comparable to unsupervised pre-training alone. This suggests that multi-task exposure during pre-training provides useful early signal without the negative effects of forcing a single model to perform all tasks simultaneously.
“Leave-one-out” training works. Pre-training on a multi-task mixture that excludes a target task, then fine-tuning on it, produces only slightly worse results. This indicates that multi-task pre-training builds general capabilities that transfer to unseen tasks without dramatic task interference.
Data repetition degrades performance
The paper also systematically tests the effect of pre-training data set size by truncating C4 and training over repeated data:
| Unique tokens | Repeats | GLUE | SQuAD | SuperGLUE |
|---|---|---|---|---|
| Full dataset | 0 | 83.28 | 80.88 | 71.36 |
| $2^{29}$ | 64 | 82.87 | 80.97 | 72.03 |
| $2^{27}$ | 256 | 82.62 | 79.78 | 69.97 |
| $2^{25}$ | 1,024 | 79.55 | 76.27 | 64.76 |
| $2^{23}$ | 4,096 | 76.34 | 70.92 | 59.29 |
Performance degrades as data shrinks, with 64 repeats showing limited effects but 1,024+ repeats causing significant degradation. Training loss curves confirm memorization at high repetition counts. The paper recommends using large, diverse pre-training datasets whenever possible.
Scaling and final configuration
The paper compares scaling strategies: more data, larger models, and ensembles. Training a larger model for fewer steps generally outperforms training a smaller model on more data. Ensembles of independently pre-trained and fine-tuned models provide orthogonal gains.
The final T5-11B model combines the best choices from all ablations: encoder-decoder architecture, span corruption objective, C4 pre-training data, multi-task pre-training followed by fine-tuning, and scaling to 11B parameters trained on over 1 trillion tokens. It achieves state-of-the-art results on GLUE (90.3 average), SuperGLUE (88.9, near human performance of 89.8), SQuAD, and CNN/Daily Mail. It does not achieve state-of-the-art on WMT translation tasks, where methods using backtranslation and cross-lingual pre-training retain the lead.
Implications and limitations
The T5 paper’s multi-task mixing findings are its most enduring contribution beyond the model itself. The core lessons: proportions matter enormously (equal mixing fails), examples-proportional mixing with a cap is a reasonable default, temperature scaling provides a single-knob alternative, and multi-task pre-training followed by fine-tuning can match pure unsupervised pre-training.
Limitations:
- All ablations use the same encoder-decoder architecture. Findings may not transfer to decoder-only models that dominate current practice.
- The multi-task mixing experiments treat each task as a separate “domain.” Interactions between similar tasks (e.g., multiple classification tasks) are not isolated.
- The paper does not provide a principled method for choosing $K$ or $T$; both require empirical search.
- C4 has known quality issues (templated text, noisy content) that have been addressed in later datasets.
Reproducibility Details
Status: Highly Reproducible. Code, pre-trained models, and the C4 dataset are all publicly released.
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Pre-training | C4 (Colossal Clean Crawled Corpus) | ~750 GB | Heuristically cleaned Common Crawl |
| Downstream | GLUE, SuperGLUE, SQuAD, CNN/DM, WMT (EnDe, EnFr, EnRo) | Standard splits | Text-to-text format |
Models
Encoder-decoder Transformer. Sizes: Base (220M), Small (60M), Large (770M), 3B, 11B. Baseline uses Base size. SentencePiece vocabulary with 32K tokens. Pre-trained for $2^{19}$ steps, fine-tuned for $2^{18}$ steps on individual tasks.
Algorithms
Multi-task mixing: examples-proportional with cap $K \in {2^{16}, \ldots, 2^{21}}$, temperature-scaled with $T \in {2, 4, 8}$, and equal mixing. Unsupervised objective: span corruption (mean span length 3, 15% corruption rate). Training with Adafactor optimizer, inverse square root learning rate schedule.
Hardware
All models trained using Mesh TensorFlow on TPU slices. T5-11B pre-trained for 1M steps with batch size $2^{11}$ sequences of length 512 (~1 trillion tokens total). Exact TPU pod configurations per experiment not detailed.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| T5 Code | Code | Apache 2.0 | Official TensorFlow implementation (JAX successor: T5X) |
| T5 Models | Model | Apache 2.0 | Pre-trained checkpoints (Small through 11B) |
| C4 Dataset | Dataset | - | ~750 GB cleaned Common Crawl, via TensorFlow Datasets |
Citation
@article{raffel2020exploring,
title={Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
author={Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J.},
journal={Journal of Machine Learning Research},
volume={21},
number={140},
pages={1--67},
year={2020}
}