A Unified Encoder-Decoder for Spoken Language Processing
SpeechT5 is a Method paper that introduces a shared encoder-decoder pre-training framework for spoken language processing. Inspired by T5’s text-to-text paradigm, SpeechT5 reformulates all spoken language tasks as “speech/text to speech/text” problems. The framework uses modal-specific pre-nets and post-nets to interface between raw speech or text and a shared Transformer encoder-decoder, enabling a single pre-trained model to handle six downstream tasks: automatic speech recognition (ASR), text-to-speech synthesis (TTS), speech translation (ST), voice conversion (VC), speech enhancement (SE), and speaker identification (SID).
Bridging the Gap Between Speech and Text Pre-Training
Prior speech pre-training work (wav2vec 2.0, HuBERT) suffered from two key limitations. First, these models learned speech representations from unlabeled audio alone, ignoring the complementary information in text data that is critical for cross-modal tasks like ASR and TTS. Second, they relied on encoder-only architectures with task-specific prediction heads, leaving the decoder un-pretrained for sequence-to-sequence generation tasks.
SpeechT5 addresses both gaps by (1) jointly pre-training on unlabeled speech and text data, and (2) using a full encoder-decoder architecture that benefits generation tasks directly. The approach builds on the observation that speech and text, despite their surface differences, share underlying semantic structure that a unified representation can capture.
Cross-Modal Vector Quantization for Alignment
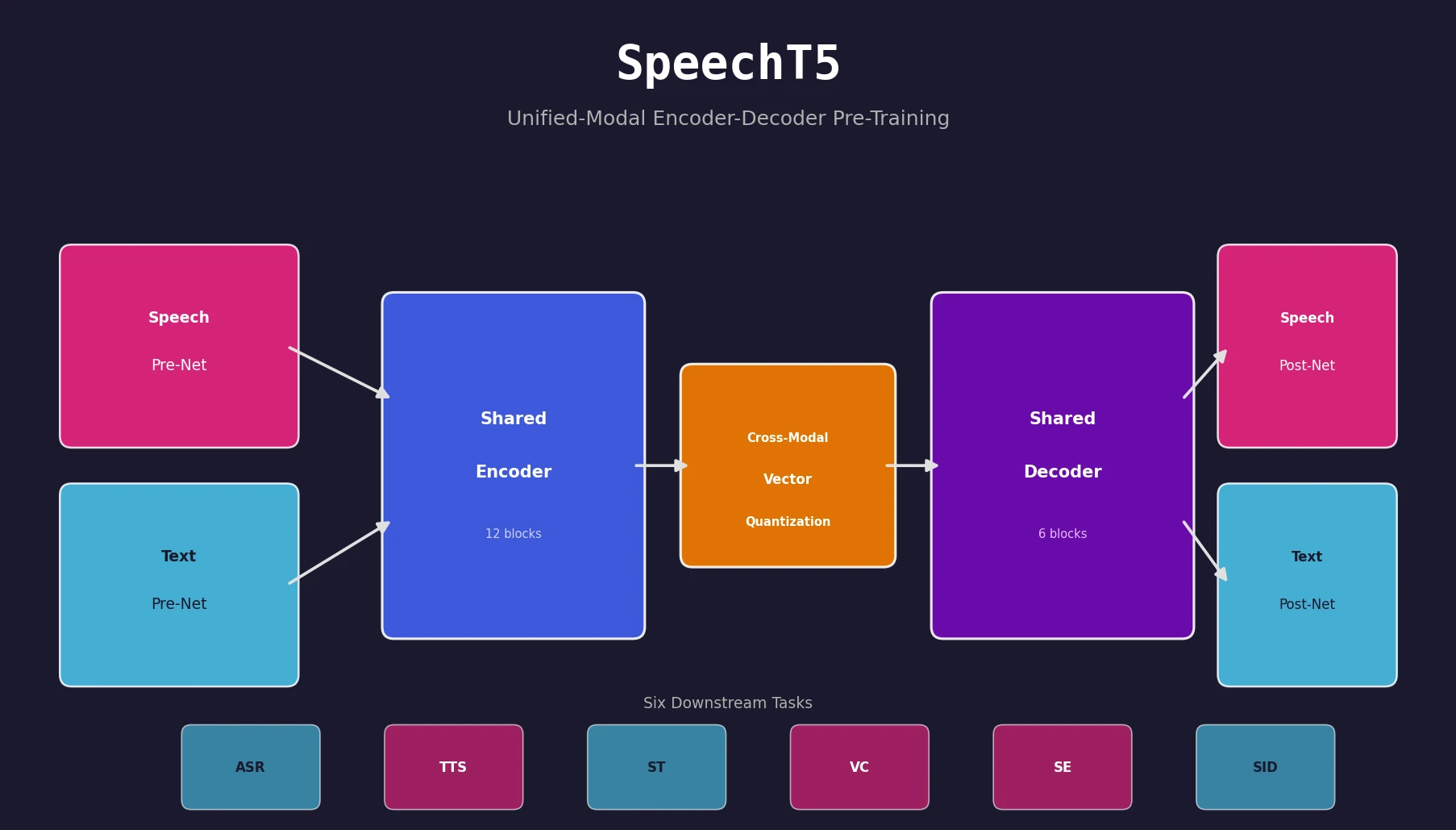
The core innovation in SpeechT5 is a cross-modal vector quantization (VQ) mechanism that aligns speech and text representations into a shared semantic space. The architecture consists of three components:
Shared encoder-decoder backbone. A Transformer with 12 encoder blocks and 6 decoder blocks (768-dim, 12 heads), using relative position embeddings.
Modal-specific pre/post-nets. Six specialized networks handle the conversion between raw modalities and the shared representation space:
- Speech-encoder pre-net: a convolutional feature extractor (from wav2vec 2.0) downsampling raw waveforms
- Speech-decoder pre-net: three FC layers with ReLU, processing 80-dimensional log Mel-filterbank features
- Speech-decoder post-net: a linear layer predicting Mel features plus five 1D conv layers (256 channels) for residual refinement, with an x-vector speaker embedding concatenated for multi-speaker support
- Text pre/post-nets: shared embedding layers mapping between character-level token indices and hidden states (768-dim)
Cross-modal vector quantization. A shared codebook $\mathbf{C}^{K}$ with $K$ learnable embeddings bridges the two modalities. Encoder outputs $\mathbf{u}_i$ are quantized via nearest-neighbor lookup:
$$ \mathbf{c}_i = \arg\min_{j \in [K]} | \mathbf{u}_i - \mathbf{c}_j |_2 $$
A proportion (10%) of contextual representations are randomly replaced with these quantized latent units before being fed to the decoder’s cross-attention. This mixing forces the quantizer to capture cross-modal features. A diversity loss encourages full codebook utilization:
$$ \mathcal{L}_d = \frac{1}{K} \sum_{k=1}^{K} p_k \log p_k $$
Pre-Training Objectives
SpeechT5 combines three pre-training objectives:
Speech pre-training uses two tasks. A bidirectional masked prediction loss $\mathcal{L}_{mlm}^{s}$ follows HuBERT’s approach, masking 8% of timesteps in 10-step spans and predicting frame-level targets from an acoustic unit discovery model:
$$ \mathcal{L}_{mlm}^{s} = \sum_{n \in \mathcal{M}} \log p(\mathbf{z}_n \mid \hat{\mathbf{H}}, n) $$
A reconstruction loss $\mathcal{L}_{1}^{s}$ minimizes the $L_1$ distance between predicted and original Mel-filterbank features, plus a binary cross-entropy stop-token loss $\mathcal{L}_{bce}^{s}$.
Text pre-training uses BART-style denoising, masking 30% of text spans (Poisson $\lambda = 3.5$) and training with maximum likelihood estimation:
$$ \mathcal{L}_{mle}^{t} = \sum_{n=1}^{N^t} \log p(\mathbf{y}_n^t \mid \mathbf{y}_{< n}^t, \hat{\mathbf{X}}^t) $$
The full pre-training loss combines all components:
$$ \mathcal{L} = \mathcal{L}_{mlm}^{s} + \mathcal{L}_{1}^{s} + \mathcal{L}_{bce}^{s} + \mathcal{L}_{mle}^{t} + \gamma \mathcal{L}_d $$
where $\gamma = 0.1$.
Evaluation Across Six Spoken Language Tasks
SpeechT5 was evaluated on six downstream tasks, each using a different combination of the shared encoder-decoder and task-appropriate pre/post-nets:
Automatic Speech Recognition (ASR)
Fine-tuned on LibriSpeech 100h with joint CTC/attention decoding. The decoding objective maximizes a combination of decoder, CTC, and language model log-probabilities:
$$ \alpha \log P_{Dec} + (1 - \alpha) \log P_{CTC} + \beta \log P_{LM} $$
where $\alpha = 0.5$ and $\beta = 1.0$ for the 100h setting (beam size 30). Results on the test sets:
| Model | LM | test-clean | test-other |
|---|---|---|---|
| wav2vec 2.0 BASE | - | 6.1 | 13.3 |
| HuBERT BASE | - | 5.8 | 13.3 |
| SpeechT5 | - | 4.4 | 10.4 |
| wav2vec 2.0 BASE | Transf. | 2.6 | 6.3 |
| SpeechT5 | Transf. | 2.4 | 5.8 |
Text-to-Speech Synthesis (TTS)
Fine-tuned on LibriTTS 460h clean sets with HiFi-GAN vocoder:
| Model | Naturalness | MOS | CMOS |
|---|---|---|---|
| Ground Truth | - | 3.87 ± 0.04 | - |
| Baseline | 2.76 | 3.56 ± 0.05 | 0 |
| SpeechT5 | 2.91 | 3.65 ± 0.04 | +0.290 |
Speech Translation (ST)
Evaluated on MUST-C English-to-German and English-to-French:
| Model | EN-DE | EN-FR |
|---|---|---|
| Fairseq ST | 22.70 | 32.90 |
| Adapter Tuning | 24.63 | 34.98 |
| Baseline (HuBERT init) | 23.43 | 33.76 |
| SpeechT5 | 25.18 | 35.30 |
Voice Conversion (VC)
Evaluated on CMU Arctic:
| Model | WER (bdl→slt) | MCD (bdl→slt) |
|---|---|---|
| VTN w/ TTS | 7.6% | 6.33 |
| Many-to-many VTN | - | 6.13 |
| SpeechT5 | 7.8% | 5.93 |
Speech Enhancement (SE)
On WHAM! dataset, SpeechT5 reduced WER from 76.1% (noisy) to 8.9%, a relative 9% improvement over the baseline’s 10.9%.
Speaker Identification (SID)
On VoxCeleb1, SpeechT5 achieved 96.49% accuracy, outperforming HuBERT LARGE at 90.33% (from SUPERB) and SpeechNet multi-task at 87.90%.
Ablation Study and Key Findings
The ablation study reveals the contribution of each pre-training component:
| Model | ASR (clean) | ASR (other) | VC (MCD) | SID (ACC) |
|---|---|---|---|---|
| SpeechT5 | 4.4 | 10.7 | 5.93 | 96.49% |
| w/o Speech PT | - | - | 6.49 | 38.61% |
| w/o Text PT | 5.4 | 12.8 | 6.03 | 95.60% |
| w/o Joint PT | 4.6 | 11.3 | 6.18 | 95.54% |
| w/o $\mathcal{L}_{mlm}^{s}$ | 7.6 | 22.4 | 6.29 | 90.91% |
Key findings:
- Speech pre-training is critical: without it, ASR fails to converge entirely, and SID accuracy drops to 38.61%.
- Text pre-training complements speech: removing it degrades ASR by ~20% relative, confirming that textual knowledge transfers to speech tasks.
- Joint pre-training enables cross-modal transfer: the vector quantization approach is essential for modality-bridging tasks like ASR.
- The masked prediction loss $\mathcal{L}_{mlm}^{s}$ is the most important single component, responsible for learning strong acoustic features.
The authors note limitations in the current scope (English-only, BASE model size) and propose scaling to larger models and multilingual settings as future work.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Speech pre-training | LibriSpeech | 960 hours | Full training set |
| Text pre-training | LibriSpeech LM text | 400M sentences | Normalized language model text |
| ASR fine-tuning | LibriSpeech | 100h / 960h subsets | |
| TTS fine-tuning | LibriTTS | 460h clean sets | |
| ST fine-tuning | MUST-C | EN-DE, EN-FR | |
| VC fine-tuning | CMU Arctic | 4 speakers | bdl, clb, slt, rms |
| SE fine-tuning | WHAM! | 16 kHz max | enhance-single task |
| SID fine-tuning | VoxCeleb1 | 100k+ utterances | 1,251 speakers |
Algorithms
- Optimizer: Adam with warmup (8% of steps) to peak LR $2 \times 10^{-4}$, then linear decay
- Speech masking: 8% of timesteps, 10-step spans
- Text masking: 30% of spans, Poisson $\lambda = 3.5$
- Vector quantization: 2 codebooks × 100 entries = $10^4$ theoretical maximum codes
- CTC/attention joint decoding for ASR (beam size 30)
- HiFi-GAN vocoder for TTS and SE waveform generation
- Parallel WaveGAN vocoder for VC
Fine-Tuning Hyperparameters
| Task | GPUs | Steps | Peak LR | Batch (per GPU) | Schedule |
|---|---|---|---|---|---|
| ASR (100h) | 8×V100 | 80k | 6e-5 | 256k audio samples | Warmup 10%, hold 40%, linear decay |
| ASR (960h) | 8×V100 | 320k | 1.3e-4 | 256k audio samples | Warmup 10%, hold 40%, linear decay |
| TTS | 8×V100 | 120k | 4e-4 | 45k tokens | Warmup 10k steps, inv. sqrt decay |
| ST | 8×V100 | 80k | - | - | Warmup 10k steps |
| VC | 8×V100 | 60k | 1e-4 | 20k tokens | 6k warmup, inv. sqrt decay |
| SE | 8×V100 | 100k | 1e-4 | 16k tokens | 10k warmup, inv. sqrt decay |
| SID | 8×V100 | 60k | 5e-4 | 64 segments (3s each) | Triangular cyclical (1e-8 to 5e-4) |
Models
- Encoder: 12 Transformer blocks (768-dim, 3072 FFN, 12 heads)
- Decoder: 6 Transformer blocks (same dimensions)
- Speech-encoder pre-net: 7 conv blocks (512 channels, strides [5,2,2,2,2,2,2], kernels [10,3,3,3,3,2,2])
- Code and pre-trained models available at github.com/microsoft/SpeechT5 (MIT license)
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| microsoft/SpeechT5 | Code | MIT | Official Fairseq-based implementation |
| Pre-trained models (via repo) | Model | MIT | SpeechT5 BASE encoder-decoder checkpoints |
| LibriSpeech | Dataset | CC-BY-4.0 | 960h speech pre-training and ASR fine-tuning |
| LibriTTS | Dataset | CC-BY-4.0 | 460h TTS fine-tuning |
| MUST-C | Dataset | CC-BY-NC-ND-4.0 | Speech translation fine-tuning |
| CMU Arctic | Dataset | Free | Voice conversion fine-tuning |
| WHAM! | Dataset | CC-BY-NC-4.0 | Speech enhancement fine-tuning |
| VoxCeleb1 | Dataset | CC-BY-SA-4.0 | Speaker identification fine-tuning |
Hardware
- Pre-training: 32 NVIDIA V100 GPUs
- Batch: ~90s speech per GPU + 12k text tokens per GPU, gradient accumulation 2
- Pre-training steps: 500k
Paper Information
Citation: Ao, J., Wang, R., Zhou, L., Wang, C., Ren, S., Wu, Y., Liu, S., Ko, T., Li, Q., Zhang, Y., Wei, Z., Qian, Y., Li, J., & Wei, F. (2022). SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 5723-5738.
@inproceedings{ao2022speecht,
title={SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing},
author={Ao, Junyi and Wang, Rui and Zhou, Long and Wang, Chengyi and Ren, Shuo and Wu, Yu and Liu, Shujie and Ko, Tom and Li, Qing and Zhang, Yu and Wei, Zhihua and Qian, Yao and Li, Jinyu and Wei, Furu},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={5723--5738},
year={2022},
doi={10.18653/v1/2022.acl-long.393}
}