An empirical study of data domain combinations
This is a discovery paper that empirically investigates how different combinations and proportions of data domains affect language model pretraining. Using the SlimPajama dataset (a globally deduplicated, 627B token refinement of RedPajama), the study trains seven 1.3B model configurations with varying domain mixtures to identify which combinations and deduplication strategies produce the best downstream performance.
Why data combination strategy matters
Multi-source pretraining datasets combine data from web crawls, code repositories, books, academic papers, and other sources. Two underexplored questions drive this work: (1) Does deduplication within each source (local) versus across all sources (global) meaningfully affect model quality? (2) When sources are thoroughly deduplicated, how does the combination and proportion of domains affect downstream performance? Most open-source LLM training datasets (RedPajama, The Pile) perform only local deduplication, leaving cross-source redundancy unaddressed.
Global deduplication and the SlimPajama dataset
SlimPajama applies global MinHashLSH deduplication (Jaccard similarity threshold 0.8, 13-gram signatures) across all seven data sources simultaneously. This reduces RedPajama’s 1.2T tokens to 627B tokens, a roughly 48% reduction. The heaviest deduplication hits CommonCrawl and GitHub, which had the most cross-source overlap.
The key processing steps:
- Low-length document filtering: Remove documents below a minimum length threshold.
- Global deduplication: MinHashLSH across all sources simultaneously, requiring 64 CPU cores and 1.4TB peak memory. This removes both within-source and between-source duplicates.
The resulting dataset composition:
| Source | SlimPajama | RedPajama | LLaMA 1 |
|---|---|---|---|
| CommonCrawl | 52.2% (333B) | 72.6% (878B) | 67.0% |
| C4 | 26.7% (170B) | 14.4% (175B) | 15.0% |
| GitHub | 5.2% (33B) | 4.9% (59B) | 4.5% |
| Books | 4.2% (27B) | 2.1% (26B) | 4.5% |
| ArXiv | 4.6% (29B) | 2.3% (28B) | 2.5% |
| Wikipedia | 3.8% (24B) | 2.0% (24B) | 4.5% |
| StackExchange | 3.3% (21B) | 1.7% (20B) | 2.0% |
Seven domain combination configurations
All configurations train 1.3B parameter models on 330B tokens with identical architecture and hyperparameters. The configurations systematically vary domain diversity:
- DC-1: CommonCrawl only (single source)
- DC-2: CommonCrawl + C4 (two web sources)
- DC-3: CommonCrawl + C4 with adjusted proportions
- DC-4: Wikipedia + Books + GitHub + ArXiv + StackExchange (no web crawl)
- DC-5: CommonCrawl + C4 + Wikipedia + Books (four sources, no code/academic)
- DC-6: All seven SlimPajama sources (maximum diversity)
- DC-7: RefinedWeb CommonCrawl (external single-source baseline)
The experimental design probes: incremental diversity (DC-1 to DC-2 to DC-5 to DC-6), proportion sensitivity (DC-2 vs DC-3), source importance (DC-3 vs DC-4), and specialization vs generalization (individual vs combined).
Diversity after global deduplication drives performance
Hugging Face leaderboard results
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA |
|---|---|---|---|---|---|
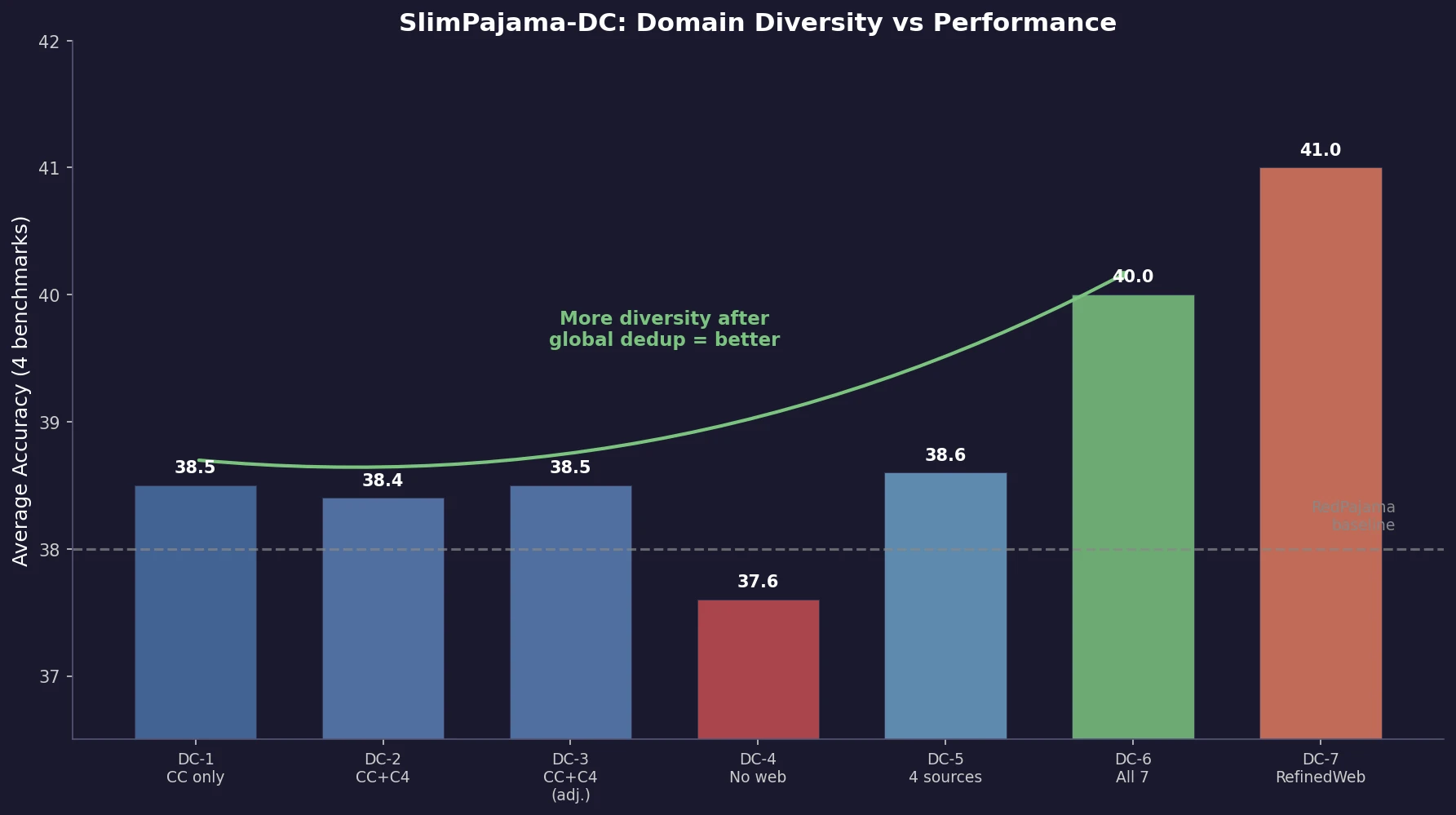
| RedPajama-1.3B | 38.0 | 37.2 | 55.8 | 24.9 | 34.3 |
| DC-1 (CC only) | 38.5 | 36.3 | 56.0 | 27.0 | 34.8 |
| DC-4 (no web) | 37.6 | 33.4 | 53.3 | 26.0 | 37.6 |
| DC-6 (all sources) | 40.0 | 33.7 | 61.0 | 26.9 | 38.4 |
| DC-7 (RefinedWeb) | 41.0 | 35.1 | 64.7 | 26.2 | 37.9 |
Key patterns:
More domain diversity improves average performance. The progression DC-1 (38.5) to DC-2 (38.4) to DC-5 (38.6) to DC-6 (40.0) shows that adding domains consistently lifts average accuracy once global deduplication has removed cross-source redundancy.
Global deduplication enables clean combination. All SlimPajama configurations except DC-4 outperform RedPajama-1.3B (38.0), which uses local deduplication only. The elimination of cross-source overlap means adding sources contributes genuinely new information.
Removing web crawl data hurts. DC-4 (no CommonCrawl/C4) scores lowest (37.6), demonstrating that web text provides essential breadth even when specialized sources are included.
Individual domains excel at specific tasks. DC-1 (CC only) achieves the highest ARC and MMLU scores. DC-4 leads on Winogrande. DC-5 leads on WSC273. No single combination dominates all tasks, reinforcing that diversity trades specialization for generalization.
Findings transfer to 7B scale. The best 1.3B configuration insights were applied to a 7B model trained with large batch sizes, achieving 63.4 average accuracy across the extended benchmark suite.
Training loss patterns
DC-6 (all sources) achieves the lowest training loss among SlimPajama configurations, consistent with the downstream results. DC-4 (no web crawl) shows the highest training loss, confirming that the large, diverse web crawl data is the most important single component.
Implications and limitations
The central finding is that diversity matters most after deduplication. When cross-source redundancy is removed, each additional source contributes genuinely new signal. Without global deduplication, adding sources may just increase redundancy without proportional benefit.
Limitations:
- Only seven fixed configurations are tested. No systematic search over continuous mixture proportions (contrast with DoReMi or Data Mixing Laws).
- The configurations are not independent: DC-6 includes all sources from DC-1 through DC-5, making it difficult to isolate the contribution of any single addition.
- Only 1.3B and 7B scales tested. Whether the diversity benefit continues scaling is unverified.
- English-only. Cross-lingual diversity effects are not studied.
- The paper is a technical report without formal peer review.
Reproducibility Details
Status: Highly Reproducible. All 1.3B models and datasets are publicly released under MIT license on HuggingFace.
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Training | SlimPajama | 627B tokens | Globally deduplicated from 1.2T RedPajama |
| Training | RefinedWeb | 600B tokens | External CC-only baseline |
| Evaluation | HF Leaderboard (ARC, HellaSwag, MMLU, TruthfulQA) | Standard | 4 benchmarks |
| Evaluation | Extended suite | 12 additional benchmarks | Zero and few-shot |
Models
1.3B parameter Cerebras-GPT architecture with ALiBi positional encoding and SwiGLU activation. All configurations trained on 330B tokens. 7B model trained with large batch-size (LBS) strategy on Cerebras 16x CS-2 cluster (80 PFLOP/s in bf16).
Hardware
Cerebras 16x CS-2 cluster, 80 PFLOP/s in bf16 mixed precision.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| SlimPajama-DC Models | Model | MIT | All 1.3B DC configurations (select via revision) |
| SlimPajama-627B-DC Dataset | Dataset | - | Source-split version of SlimPajama-627B |
Citation
@article{shen2023slimpajamadc,
title={SlimPajama-DC: Understanding Data Combinations for LLM Training},
author={Shen, Zhiqiang and Tao, Tianhua and Ma, Liqun and Neiswanger, Willie and Liu, Zhengzhong and Wang, Hongyi and Tan, Bowen and Hestness, Joel and Vassilieva, Natalia and Soboleva, Daria and Xing, Eric},
journal={arXiv preprint arXiv:2309.10818},
year={2023}
}