An empirical study of scaling under data constraints
This is a discovery paper that systematically investigates what happens when language models are trained for multiple epochs on repeated data. It extends the Chinchilla scaling laws to the data-constrained regime by proposing a new scaling formula that accounts for the diminishing value of repeated tokens, validated across 400+ training runs ranging from 10M to 9B parameters and up to 1500 epochs.
Running out of unique training data
The Chinchilla scaling laws assume unlimited unique data: for a given compute budget, there exists an optimal balance of model parameters and training tokens. But extrapolating these laws to larger models implies data requirements that exceed what is available. Villalobos et al. estimated that high-quality English text would be exhausted by 2024 under Chinchilla-optimal scaling. Most prior large language models trained for a single epoch, and some work explicitly warned against data reuse. The Galactica models (trained for 4.25 epochs) showed that multi-epoch training could work, but no systematic study had quantified the tradeoff between repeated data and fresh data, or how to allocate compute optimally when data is finite.
Effective data with exponential decay for repetition
The paper generalizes the Chinchilla scaling law by replacing raw token count $D$ with an effective data term $D’$ that accounts for the diminishing value of repeated tokens:
$$ L(N, D) = \frac{A}{N’^{\alpha}} + \frac{B}{D’^{\beta}} + E $$
where the effective data is:
$$ D’ = U_{D} + U_{D} R_{D}^{} \left(1 - e^{-R_{D}/R_{D}^{}}\right) $$
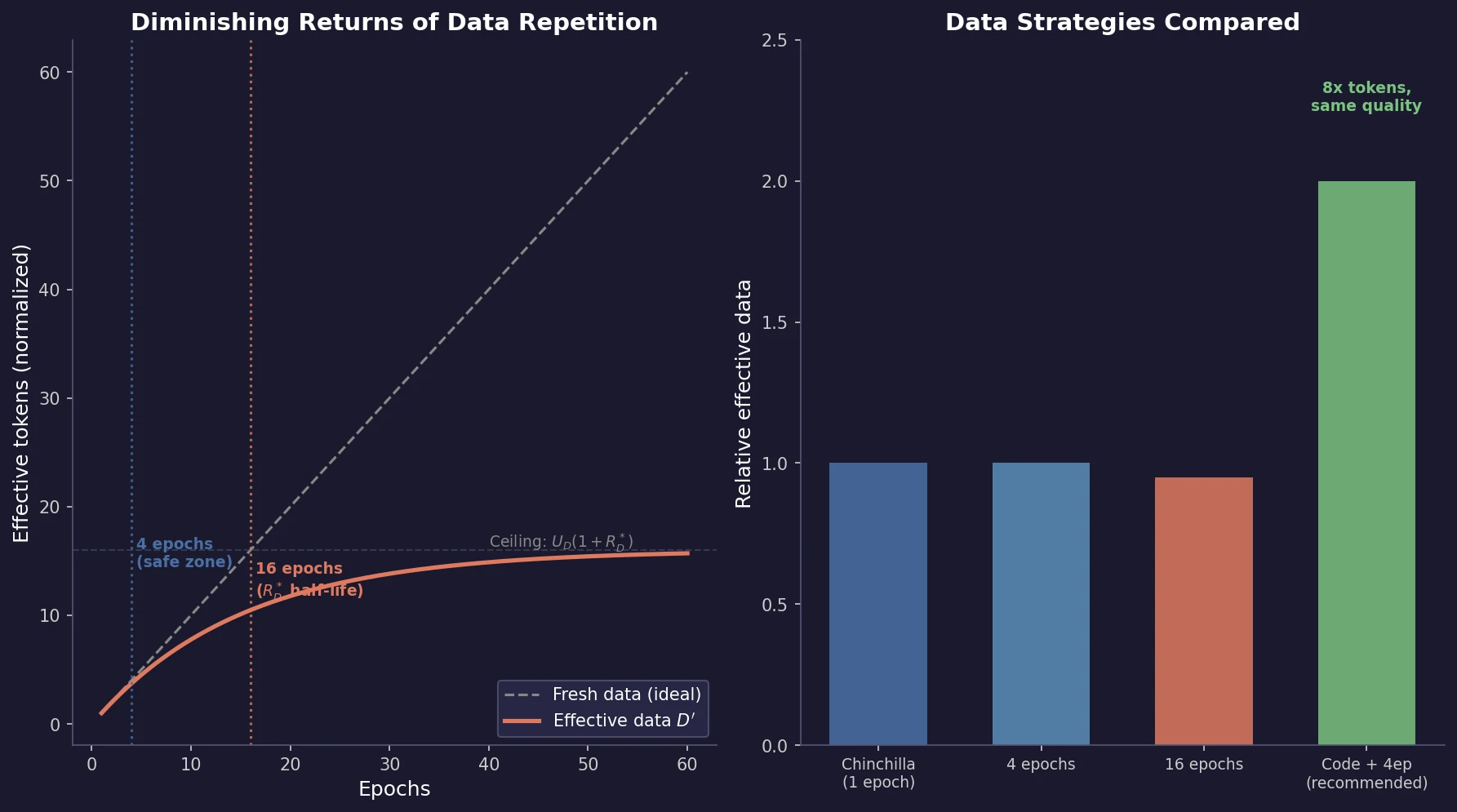
Here $U_{D}$ is the number of unique tokens, $R_{D}$ is the number of repetitions (epochs minus 1), and $R_{D}^{}$ is a learned constant representing the “half-life” of data repetition. When $R_{D} = 0$ (single epoch), $D’ = U_{D} = D$ and the formula reduces to standard Chinchilla. When $R_{D} \ll R_{D}^{}$, repeated data is worth almost the same as fresh data. As $R_{D}$ grows large, the value of repeated tokens decays to zero, and $D’$ saturates at $U_{D}(1 + R_{D}^{})$, meaning no amount of repetition can substitute for more than $R_{D}^{}$ epochs’ worth of fresh data.
A symmetric formula handles excess parameters:
$$ N’ = U_{N} + U_{N} R_{N}^{} \left(1 - e^{-R_{N}/R_{N}^{}}\right) $$
where $U_{N}$ is the compute-optimal parameter count for $U_{D}$ unique tokens and $R_{N}$ measures how much the model exceeds that count. The fitted values are $R_{D}^{} \approx 15.0$ (data repetition half-life at ~16 epochs) and $R_{N}^{} \approx 5.3$ (excess parameters decay faster than repeated data).
Experiments across 400+ models
Scale. Models from 10M to 9B parameters, trained for up to 1500 epochs. Three experimental protocols: fixed unique data (100M, 400M, 1.5B tokens), fixed FLOPs, and parametric fitting across all runs. Training on C4 (English web text) with GPT-2 architecture decoder-only transformers.
Resource allocation: epochs scale faster than parameters
With fixed unique data, results show that more than 50% loss reduction is possible by training beyond one epoch and increasing model size beyond the single-epoch optimum. The data-constrained efficient frontier recommends allocating most additional compute to more epochs rather than more parameters, because excess parameters decay faster ($R_{N}^{} < R_{D}^{}$). This contrasts with Chinchilla, which recommends scaling both equally.
A concrete validation: training the data-constrained compute-optimal model for $9.3 \times 10^{21}$ FLOPs with 25B unique tokens, the recommended allocation (27% fewer parameters, more epochs) achieves better loss and downstream performance than the Chinchilla-optimal allocation.
Resource return: the 4-epoch safe zone and 16-epoch half-life
| Epochs | Loss impact | Downstream impact |
|---|---|---|
| 1 (baseline) | Optimal | Optimal |
| Up to 4 | Negligible (+0.5% loss) | No significant difference |
| ~16 ($R_{D}^{*}$) | Diminishing returns begin sharply | Measurable degradation |
| Beyond 16 | Returns decay to near zero | Significant degradation |
| Extreme (44+) | Training can diverge | Failure |
The 8.7B parameter model trained for 4 epochs ($D_{C} = 44$B unique tokens) finishes with only 0.5% higher validation loss than the single-epoch model ($D_{C} = 178$B unique tokens). Beyond 16 epochs, each repeated token retains only $1 - 1/e \approx 63%$ of the value of a fresh token, meaning roughly 37% of value is lost per repetition cycle at the half-life point.
Complementary strategies: code augmentation and filtering
When data is limited, two strategies can extend the effective dataset:
Code augmentation. Mixing Python code from The Stack with natural language data. Up to 50% code (42B tokens) shows no degradation on natural language benchmarks, effectively providing a 2x increase in useful training data. Some tasks (WebNLG generation, bAbI reasoning) actually improve with code, possibly because code trains long-range state-tracking capabilities.
Filtering relaxation. Perplexity filtering (keeping the 25% lowest-perplexity samples) is effective on noisy datasets, but deduplication filtering does not improve downstream performance (though it may reduce memorization). The recommendation: reserve aggressive filtering for noisy data sources; for clean datasets, more data through reduced filtering is better than less data through strict filtering.
Combined strategy: doubling available data with code and then repeating for 4 epochs yields 8x more training tokens with performance expected to match 8x more unique data.
Key findings and limitations
Key findings:
- Multi-epoch training is beneficial, not harmful, up to moderate repetition counts.
- The data-constrained scaling law accurately predicts loss under repetition using an exponential decay formulation.
- Compute should be allocated to epochs faster than parameters when data is constrained.
- Code augmentation and selective filtering extend effective data without quality degradation.
Limitations:
- All experiments use the GPT-2 transformer architecture; applicability to other architectures or modalities is untested.
- Only the entire dataset is repeated uniformly. Selectively repeating subsets (e.g., high-value data for more epochs) is not modeled.
- Hyperparameter sensitivity (learning rate, dropout) to epoch count is unexplored. Higher learning rates may cause earlier onset of diminishing returns.
- Focused on English text. Cross-lingual augmentation effects are not studied.
Reproducibility Details
Status: Highly Reproducible. Code, models, datasets, and hyperparameters are all publicly released under Apache 2.0.
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Training | C4 (English) | Varies by experiment | Fixed unique data: 100M, 400M, 1.5B tokens |
| Code augmentation | The Stack (Python) | Up to 42B tokens | Mixed with natural language |
| Evaluation | 19 NL tasks | Standard splits | Zero to five-shot, 114 scores per model |
Algorithms
Data-constrained scaling law: $D’ = U_{D} + U_{D} R_{D}^{}(1 - e^{-R_{D}/R_{D}^{}})$ with $R_{D}^{} \approx 15.0$, $R_{N}^{} \approx 5.3$. Fitted using the methodology of Hoffmann et al. (2022) adapted for the repetition terms. 400+ training runs used for fitting.
Models
GPT-2 architecture decoder-only transformers with GPT-2 tokenizer. Sizes: 10M to 8.7B parameters. Cosine learning rate schedule (max 2e-4, decay to 2e-5), Adam optimizer ($\beta_2 = 0.999$), dropout 0.1, weight decay 0.1, gradient clipping at 1.0. bfloat16 precision. Trained using Megatron-DeepSpeed.
Evaluation
| Metric | Data-Constrained Optimal | Chinchilla Optimal | Notes |
|---|---|---|---|
| Validation loss (9.3e21 FLOPs, 25B unique) | Lower | Higher | 27% fewer parameters |
| Downstream (4 epochs vs 1) | No significant difference | Baseline | 8.7B params, 44B unique tokens |
| Code augmentation (50% code) | No NL degradation | Baseline | Some tasks improve |
Hardware
Trained on the LUMI supercomputer (Finland) using AMD Instinct MI250X GPUs with data, tensor, and pipeline parallelism. Up to 256 GPUs (64 nodes) per run, with up to 2,200 nodes (~8,800 GPUs) used in parallel across all concurrent runs. Total compute: approximately 3 million GPU hours. The cluster runs on 100% renewable hydroelectric energy.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| datablations | Code + Models + Data | Apache 2.0 | All 400+ models, datasets, and training code |
| Megatron-DeepSpeed fork | Code | - | Training framework adapted for AMD ROCm |
Citation
@inproceedings{muennighoff2023scaling,
title={Scaling Data-Constrained Language Models},
author={Muennighoff, Niklas and Rush, Alexander M. and Barak, Boaz and Le Scao, Teven and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin},
booktitle={Advances in Neural Information Processing Systems},
volume={36},
year={2023}
}