A method for automatic domain reweighting
This is a method paper that introduces Domain Reweighting with Minimax Optimization (DoReMi), an algorithm for automatically tuning the mixture proportions of pretraining data domains. Rather than relying on heuristics or expensive downstream-task-based tuning, DoReMi uses a small proxy model trained with group distributionally robust optimization (Group DRO) to produce domain weights that transfer to much larger models.
Why data mixture proportions matter
Language model pretraining datasets combine text from many domains: web crawls, Wikipedia, books, code, academic papers, and others. The mixture proportions (how much of each domain to include) significantly affect downstream performance, but existing approaches either set them by hand (The Pile uses heuristic weights) or tune them against downstream tasks (GLaM/PaLM), which is expensive and risks overfitting to a specific evaluation set. No principled, task-agnostic method existed for determining mixture proportions.
Minimax optimization over domain excess loss
DoReMi’s core insight is to frame data mixture optimization as a minimax problem: find domain weights that minimize the worst-case excess loss across all domains. The algorithm has three steps.
Step 1: Train a small reference model (280M parameters) on some default domain weights $\alpha_{\text{ref}}$ (e.g., proportional to raw token count).
Step 2: Train a small proxy model $p_{\theta}$ using Group DRO, which solves the minimax objective:
$$ \min_{\theta} \max_{\alpha \in \Delta^{k}} \sum_{i=1}^{k} \alpha_{i} \cdot \left[ \frac{1}{\sum_{x \in D_{i}} |x|} \sum_{x \in D_{i}} \ell_{\theta}(x) - \ell_{\text{ref}}(x) \right] $$
where $\ell_{\theta}(x) = -\log p_{\theta}(x)$ and $\ell_{\text{ref}}(x) = -\log p_{\text{ref}}(x)$. The excess loss $\ell_{\theta}(x) - \ell_{\text{ref}}(x)$ measures how much headroom the proxy has to improve on each example relative to the reference. The inner maximization upweights domains with high excess loss via exponentiated gradient ascent, while the outer minimization trains the proxy on those upweighted domains.
At each training step, the domain weights update as:
$$ \alpha_{t}’ \leftarrow \alpha_{t-1} \exp(\eta \lambda_{t}) $$
where $\lambda_{t}[i]$ is the per-domain excess loss (clipped at zero), followed by renormalization and smoothing with a uniform component: $\alpha_{t} \leftarrow (1-c)\frac{\alpha_{t}’}{\sum_{i} \alpha_{t}’[i]} + cu$, with $c = 10^{-3}$.
The final domain weights are the average over all training steps: $\bar{\alpha} = \frac{1}{T}\sum_{t=1}^{T} \alpha_{t}$.
Step 3: Resample data according to $\bar{\alpha}$ and train the full-scale model using standard procedures.
Iterated DoReMi extends this by running multiple rounds, using the previous round’s optimized weights as the next round’s reference weights. This converges within 3 rounds on the GLaM dataset.
Experiments across The Pile and GLaM datasets
Datasets. The Pile (22 domains, 800GB) and the GLaM dataset (8 domains, also used for PaLM). On The Pile, baseline weights come from the dataset defaults. On GLaM, baseline weights are uniform, with downstream-tuned oracle weights available for comparison.
Setup. Transformer decoder-only LMs trained with next-token prediction. All models use batch size 512 and sequence length 1024. Proxy and reference models are 280M parameters. Main models are 8B parameters (30x larger). Training runs: 200K steps (Pile) or 300K steps (GLaM). The domain weight optimization cost (training two 280M models) is 8% of the compute for the 8B main model.
Evaluation. Per-domain held-out perplexity and one-shot generative accuracy on five tasks: TriviaQA, NaturalQuestions, WebQuestions, SQuADv2, and LAMBADA.
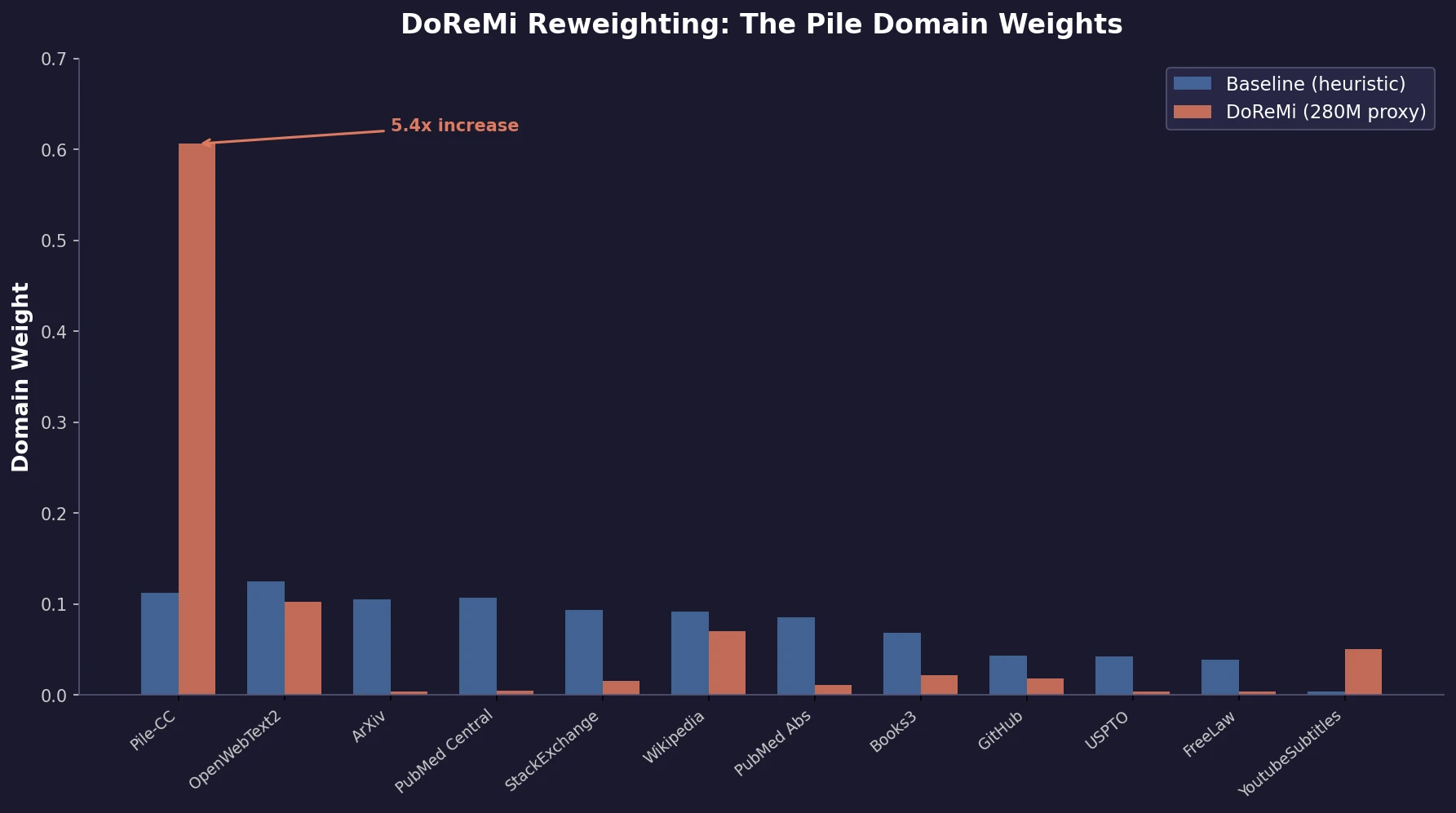
Key domain weight shifts
On The Pile, DoReMi (280M) dramatically upweights diverse web text (Pile-CC: 0.112 to 0.606) while downweighting specialized domains like ArXiv (0.105 to 0.004), PubMed Central (0.107 to 0.005), and StackExchange (0.093 to 0.015). Smaller, underrepresented domains like YouTubeSubtitles and PhilPapers receive proportionally large increases.
Scaling behavior
DoReMi was tested with matched proxy/main model sizes (280M through 1B) and with varying proxy sizes (70M through 1B) feeding into an 8B main model.
| Configuration | Speedup to baseline accuracy | Downstream improvement |
|---|---|---|
| DoReMi (280M to 280M) | 4x | +2% avg accuracy |
| DoReMi (280M to 8B) | 2.6x | +6.5% avg accuracy |
| DoReMi (150M to 8B) | ~2x | Significant |
| DoReMi (1B to 8B) | ~2x | Significant |
Improvements are consistent across all tested model scales (280M to 1B matched), with no sign of diminishing returns at larger sizes.
Perplexity improves everywhere, even on downweighted domains
The most striking finding is that DoReMi improves perplexity on all 22 domains in The Pile, including domains it downweights. The proposed explanation: the lowest-entropy domains need few samples to learn (they’re statistically simple), while the highest-entropy domains have token distributions close to the uniform initialization and also need fewer samples. Reallocating weight to medium-entropy domains generates positive transfer that lifts all domains.
On The Pile, DoReMi reaches the baseline’s downstream accuracy in 75K steps versus 200K for the baseline (2.6x speedup) and achieves a 6.5% absolute improvement in average one-shot accuracy at 200K steps.
On the GLaM dataset, iterated DoReMi (round 2) matches the performance of domain weights that were tuned directly on downstream task performance, despite having no knowledge of downstream tasks. Domain weights converge within 3 iterations.
Ablations
Using only the proxy model’s loss (prefer hardest domains) or only the negative reference loss (prefer easiest domains) both underperform the full excess loss formulation. Both components are necessary: the excess loss identifies domains where the proxy has room to improve relative to what is learnable.
The proxy model itself typically underperforms the main model trained on its weights, and this gap grows at larger proxy scales. A 1B proxy model underperforms the 1B baseline, yet its domain weights still improve 1B main model training by over 2x. This suggests the domain weight signal is robust even when the proxy model itself is not well-trained.
Limitations
The domain weight landscape may have multiple local optima: a 280M proxy puts most weight on Pile-CC, while a 1B proxy favors OpenWebText2 instead. Both configurations improve over baseline, but the optimal weights are not unique.
The granularity of “domains” matters. DoReMi works better with more domains (22 on The Pile versus 8 on GLaM). Domains are defined by data provenance, which is coarse-grained. Fine-grained domain definitions (e.g., via clustering) could improve results but also risk DRO putting all weight on a small set of worst-case examples.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Pretraining | The Pile | 800 GB, 22 domains | Default heuristic weights as baseline |
| Pretraining | GLaM dataset | 8 domains | Uniform weights as baseline; downstream-tuned oracle available |
| Evaluation | TriviaQA, NaturalQuestions, WebQuestions, SQuADv2, LAMBADA | Standard splits | One-shot generative evaluation |
Algorithms
Group DRO with exponentiated gradient ascent for domain weight updates. Step size $\eta = 1$, smoothing $c = 10^{-3}$. Per-token excess loss clipped at zero. Domain weights averaged over all training steps. Iterated DoReMi converges when $|\bar{\alpha} - \alpha_{\text{ref}}|_{\infty} < 10^{-3}$.
Models
Vanilla Transformer decoder-only models with 256K vocabulary. Sizes: 70M (3 layers), 150M (6 layers), 280M (12 layers), 510M (12 layers), 760M (12 layers), 1B (16 layers), 8B (32 layers). All use 64-dim attention heads except 8B (128-dim).
Evaluation
| Metric | DoReMi (280M to 8B) | Baseline (8B) | Notes |
|---|---|---|---|
| Avg one-shot accuracy | +6.5% over baseline | Reference | 5 generative tasks |
| Worst-case log-perplexity | 1.46 | 1.71 | Across 22 Pile domains |
| Avg log-perplexity | 1.40 | 1.64 | Across 22 Pile domains |
| Domains beating baseline | 22/22 | 0/22 | Per-domain perplexity |
Hardware
Proxy and reference models (under 1B) trained on TPUv3. Models at 1B and 8B trained on TPUv4. Domain weight optimization (two 280M runs) costs 8% of 8B training FLOPs.
Citation
@inproceedings{xie2023doremi,
title={DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
author={Xie, Sang Michael and Pham, Hieu and Dong, Xuanyi and Du, Nan and Liu, Hanxiao and Lu, Yifeng and Liang, Percy and Le, Quoc V. and Ma, Tengyu and Yu, Adams Wei},
booktitle={Advances in Neural Information Processing Systems},
volume={36},
year={2023}
}