An empirical discovery of predictable mixture-loss relationships
This is a discovery paper that identifies a quantitative, functional relationship between pretraining data mixture proportions and language model loss. The key finding is that domain-specific validation loss follows an exponential law over the linear combination of training domain proportions, and this law composes with standard scaling laws to enable cheap prediction of large-model performance under arbitrary mixtures.
The missing quantitative link between data mixtures and performance
Pretraining data for large language models combines text from many domains (web, code, academic, books, etc.), and mixture proportions significantly affect model quality. Existing approaches either set proportions by hand without disclosed criteria (LLaMA, Baichuan) or use algorithmic methods like DoReMi that optimize qualitatively but cannot predict the quantitative effect of a specific mixture before training. Scaling laws exist for model size and data quantity, but no equivalent existed for mixture proportions. This paper fills that gap.
The exponential data mixing law
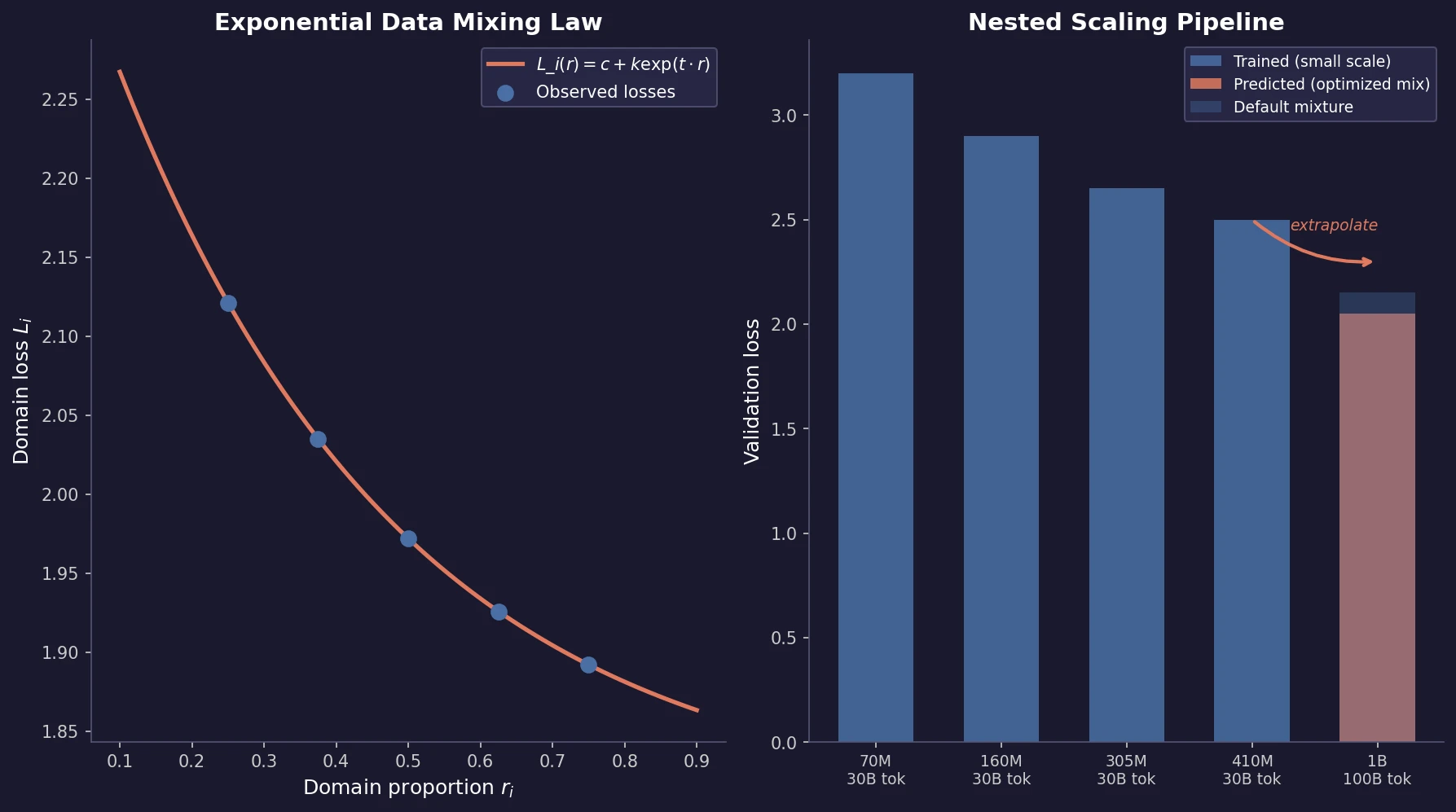
The core finding: for a model of fixed size trained for a fixed number of steps, the validation loss on domain $i$ as a function of the training mixture proportions $r_{1 \dots M}$ follows:
$$ L_{i}(r_{1 \dots M}) = c_{i} + k_{i} \exp\left(\sum_{j=1}^{M} t_{ij} r_{j}\right) $$
where $c_{i}$, $k_{i}$, and $t_{ij}$ are fitted parameters. The constant $c_{i}$ represents the irreducible loss (not affected by mixture changes). The interaction coefficients $t_{ij}$ capture how training domain $j$ affects validation loss on domain $i$: negative $t_{ij}$ means domain $j$ helps domain $i$, positive means it hurts.
This was discovered progressively:
- Two domains: Log-reducible-loss is linear in domain proportion (univariate exponential).
- Three domains: The exponential generalizes to a linear combination over all domain proportions (Eq. above), outperforming alternatives with comparable parameter count.
- General validation: For a validation set composed of $K$ domains with proportions $s_{1 \dots K}$, the overall loss is:
$$ L(r_{1 \dots M}) = \sum_{i=1}^{K} s_{i} \left[ c_{i} + k_{i} \exp\left(\sum_{j=1}^{M} t_{ij} r_{j}\right) \right] $$
When the validation set composition is unknown, implicit domain aggregation treats $s_{i}$ as learnable parameters. Setting the number of implicit domains larger than the true number works well and is robust to overestimation.
Domain interaction patterns
Visualizing the fitted $t_{ij}$ coefficients across 5 coarse Pile domains reveals three relationship types: most domain pairs are unrelated (sparse interaction matrix where each domain’s loss is dominated by its own training proportion), some show facilitation (e.g., dialogue data helps internet text), and some show conflict (e.g., symbolic data hurts prose). This sparsity explains why the law can be fitted with fewer samples than the quadratic parameter count would suggest.
Nested scaling pipeline for cheap prediction
Fitting data mixing laws directly at target scale is too expensive (requires many full training runs at different mixtures). The paper proposes nesting three scaling laws:
Step 1: For each mixture $r_{i}$ and each small model size $N_{j}$, train for $S_{0}$ steps. Fit a power law $L(S) = E_{1} + B/S^{\beta}$ over steps to extrapolate to the target step count $S_{\text{target}}$.
Step 2: With the step-extrapolated losses for each mixture, fit a power law $L(N) = E_{2} + A/N^{\alpha}$ over model sizes to extrapolate to the target model size $N_{\text{target}}$.
Step 3: With the predicted losses at $(N_{\text{target}}, S_{\text{target}})$ for all sampled mixtures, fit the data mixing law and search for the optimal mixture.
This pipeline requires only training small models (70M to 410M) for short runs (30B tokens) to predict performance of a 1B model trained for 100B tokens.
Mixture sampling strategy
To get informative samples efficiently, the paper uses double-diminishing proportions: for each domain, enumerate proportions by halving from the maximum available. This distributes losses evenly across the exponential law’s range. From 40 candidate mixtures trained at the smallest scale (70M), 20 are selected based on which subset minimizes data mixing law fitting error.
Experiments on RedPajama and continual pretraining
Main experiment. Models trained on RedPajama, validated on the Pile (mimicking the common scenario where validation data comes from a different distribution than training). Small models: 70M, 160M, 305M, 410M trained for 30B tokens. Target: 1B model for 100B tokens.
The optimized mixture dramatically redistributes weight compared to RedPajama defaults:
| Domain | Default | Optimized |
|---|---|---|
| CommonCrawl | 0.670 | 0.125 |
| C4 | 0.150 | 0.250 |
| GitHub | 0.045 | 0.141 |
| ArXiv | 0.045 | 0.250 |
| Books | 0.045 | 0.094 |
| StackExchange | 0.025 | 0.125 |
| Wikipedia | 0.020 | 0.016 |
The optimized mixture reaches the default mixture’s final performance in 73% of the training steps and eventually achieves performance equivalent to 48% more training on the default mixture.
Comparison to DoReMi and DoGE. Data mixing laws outperform both: the predicted-optimal mixture achieves lower validation loss than DoReMi and DoGE (both universal and OOD settings) for 1B models trained for 100B tokens on RedPajama.
Continual pretraining. The law extends to continual pretraining (Pythia-70M on Pile + Python code). It accurately predicts the critical mixture proportion that avoids catastrophic forgetting on the original domain while improving the target domain. This suggests data mixing laws could guide dynamic data schedules across multi-stage pretraining.
Implications and limitations
The data mixing law provides a predictive framework rather than just an optimization algorithm. Key implications:
- The interaction coefficients $t_{ij}$ make domain relationships quantitatively observable before full-scale training, identifying facilitation and conflict pairs.
- The nested pipeline’s cost is dominated by the small-model training runs (40 mixtures at 70M scale), which is orders of magnitude cheaper than even a single target-scale run.
- The continual pretraining application opens the door to optimizing dynamic data schedules, where mixture proportions change across training stages.
Limitations: The “domain” concept remains loosely defined (provenance-based). The nested scaling laws introduce compounding errors at each step, and predictions tend to slightly underestimate actual loss. The number of required fitting samples, while subquadratic in practice due to sparsity, still scales with the number of domains. No theoretical justification for the exponential form is provided; it is a purely empirical finding.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Training (pilot) | The Pile (GitHub, Pile-CC, Books3) | 30B tokens | 2-domain and 3-domain experiments |
| Training (main) | RedPajama | 100B tokens | 7 domains |
| Validation | The Pile validation set | Standard split | Out-of-distribution relative to RedPajama |
| Continual pretraining | Pile + Python code | 10B tokens | Pythia-70M base model |
Algorithms
Data mixing law: $L_{i}(r_{1 \dots M}) = c_{i} + k_{i} \exp(\sum_{j} t_{ij} r_{j})$. Fitted via AdaBoost Regressor on sampled mixtures. Step scaling law: $L(S) = E_{1} + B/S^{\beta}$. Model size scaling law: $L(N) = E_{2} + A/N^{\alpha}$. Both fitted via Huber loss minimization with LBFGS. Decomposed Chinchilla-style (separate fits for stability). 40 candidate mixtures sampled via double-diminishing proportions, 20 selected for the final pipeline.
Models
Transformer decoder-only LMs. Pilot: 70M, 160M. Main pipeline: 70M, 160M, 305M, 410M (for fitting), 1B (target). Batch size: 1M tokens. Cosine learning rate decay with 2K step warmup, decaying to 0.1x at 100K steps.
Evaluation
| Metric | Optimized Mixture | Default Mixture | Notes |
|---|---|---|---|
| Steps to match default final loss | 73K (73%) | 100K (100%) | 27% training reduction |
| Equivalent extra training | +48% | Baseline | Estimated via step scaling law |
| Validation loss (1B, 100B) | Lowest | Higher than optimized | Also beats DoReMi and DoGE |
Hardware
8 A100 GPUs. Training times per 30B-token run: 3.5 hours (70M), 8 hours (160M), 16 hours (305M), 21 hours (410M).
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| The Pile | Dataset | MIT | Pilot and validation data |
| RedPajama | Dataset | Apache 2.0 | Main training data |
| Pythia Suite | Model | Apache 2.0 | Model architecture configs; Pythia-70M checkpoint for continual pretraining |
Reproducibility status: Partially Reproducible. Datasets and base model checkpoints are public. No official code release for the data mixing law fitting pipeline, mixture sampling, or the nested scaling law prediction workflow.
Citation
@inproceedings{ye2025datamixinglaws,
title={Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance},
author={Ye, Jiasheng and Liu, Peiju and Sun, Tianxiang and Zhan, Jun and Zhou, Yunhua and Qiu, Xipeng},
booktitle={International Conference on Learning Representations},
year={2025}
}