Research notes on language model architectures and pretraining methods, covering transformer variants, data mixing strategies, and scaling laws.
| Year | Paper | Key Idea |
|---|---|---|
| 2020 | T5: Exploring Transfer Learning Limits | Unified text-to-text framework with systematic ablation of NLP transfer |
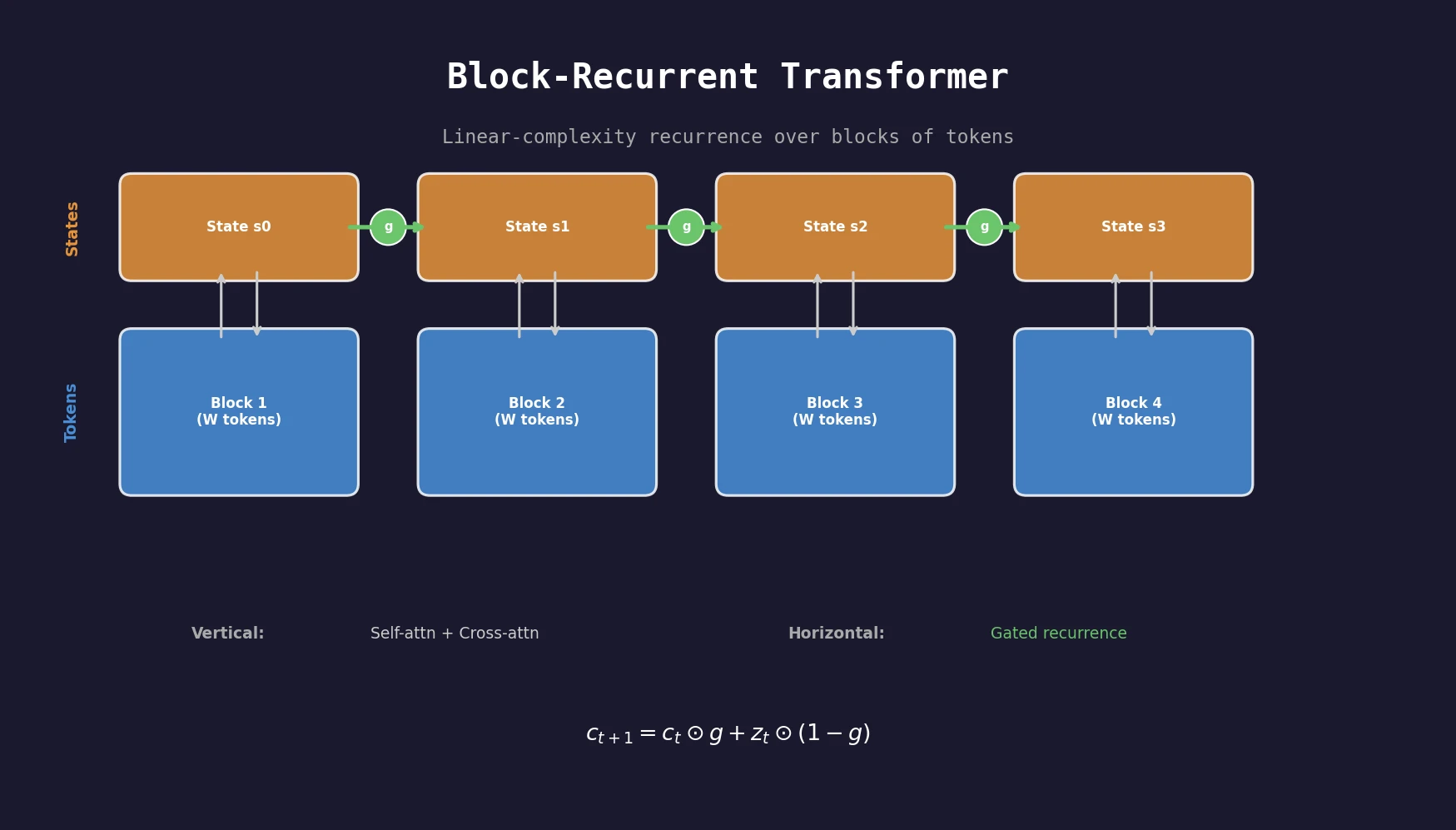
| 2022 | Block-Recurrent Transformers | Recurrence over token blocks for linear-complexity long-sequence modeling |
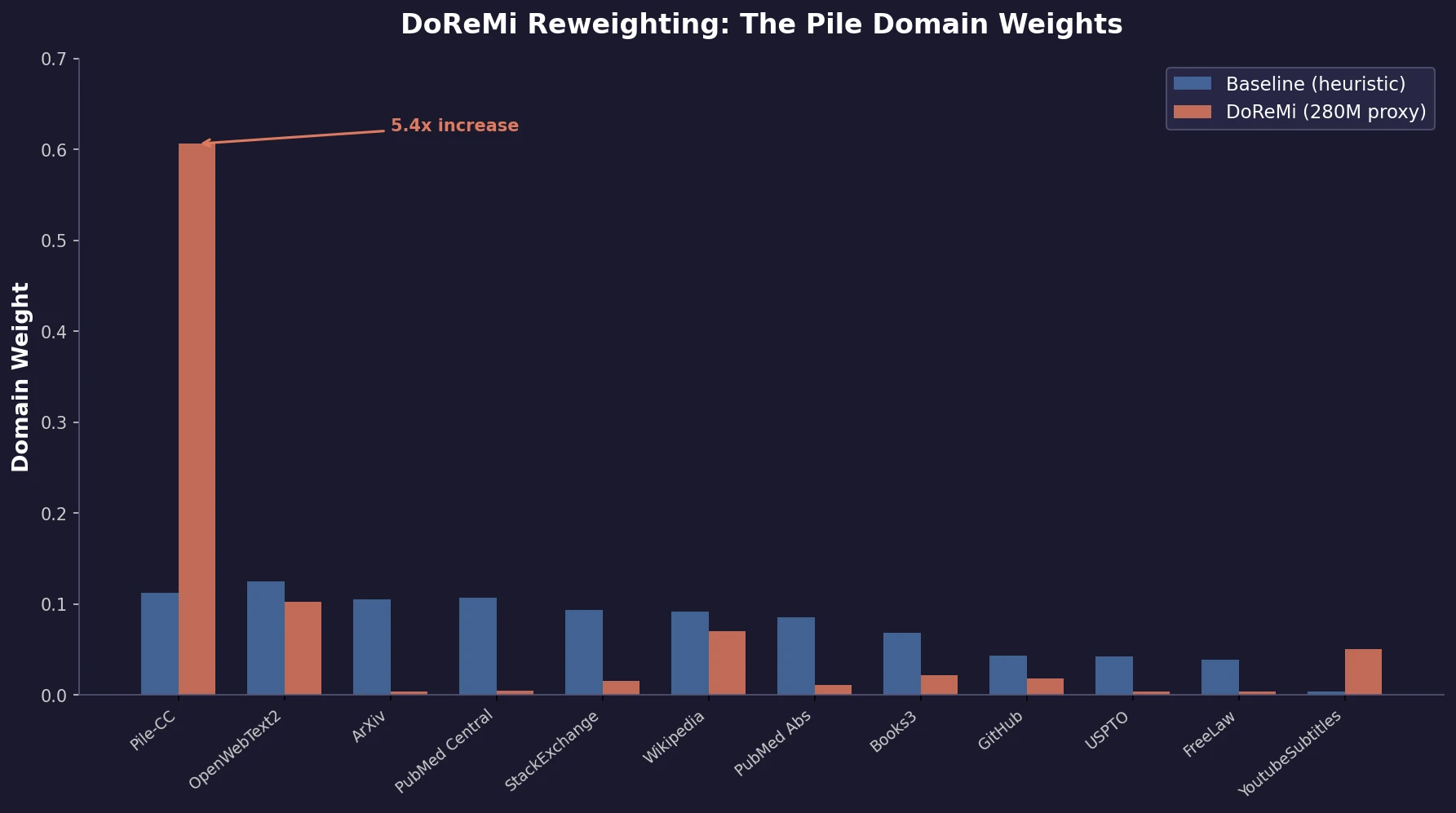
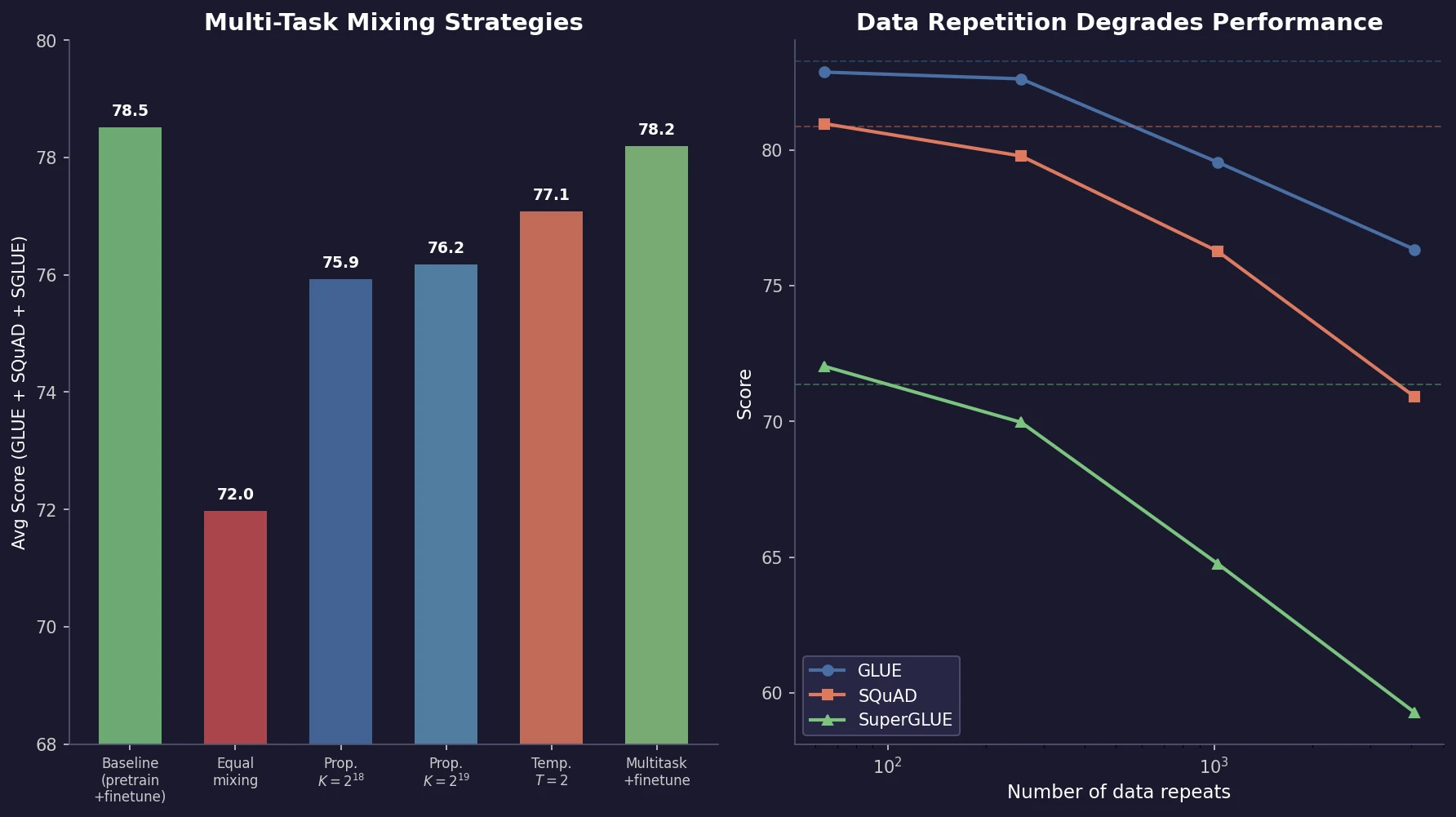
| 2023 | DoReMi | Proxy-model DRO to learn optimal domain weights for LM pretraining |
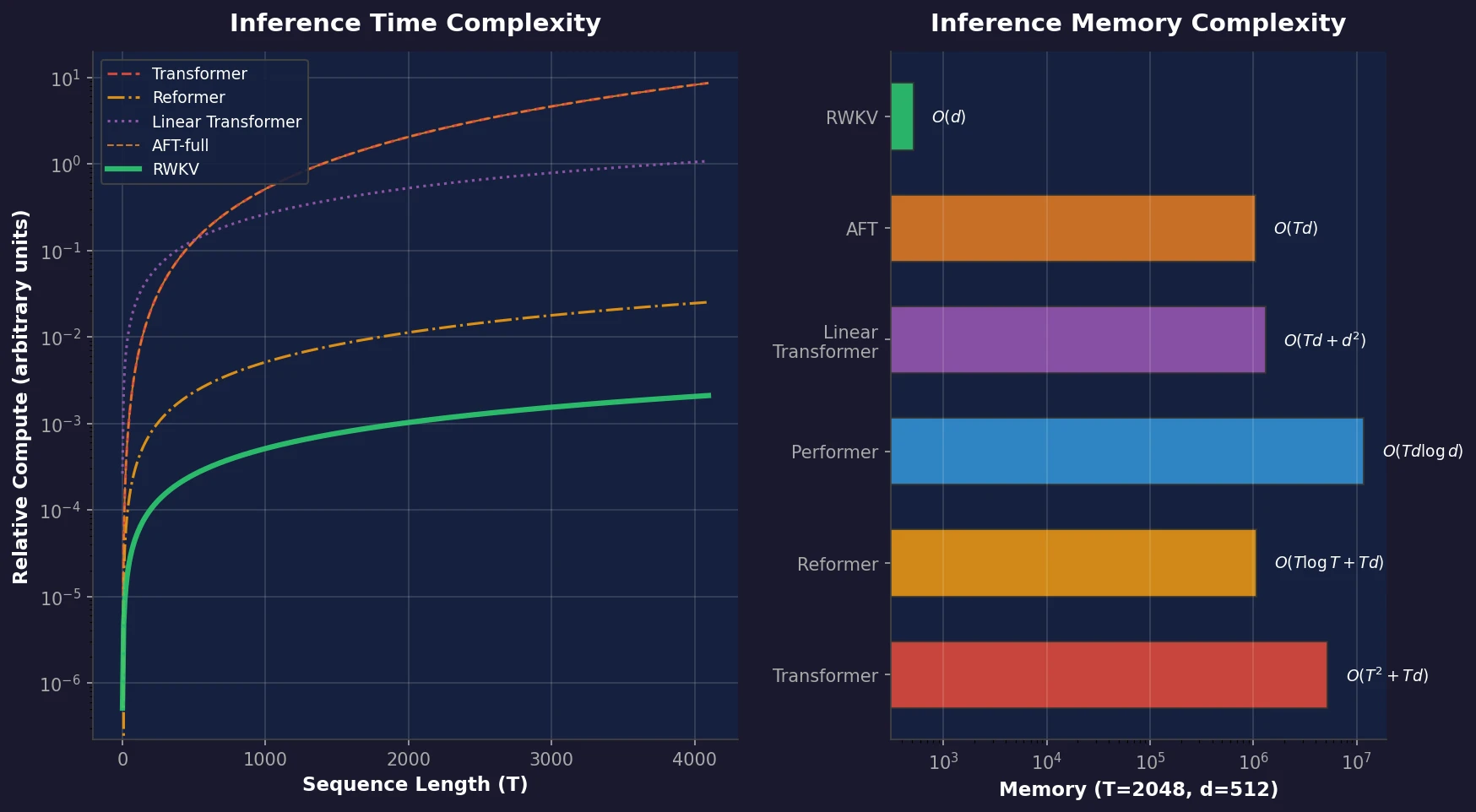
| 2023 | RWKV | Transformer-level quality with linear-time, constant-memory RNN inference |
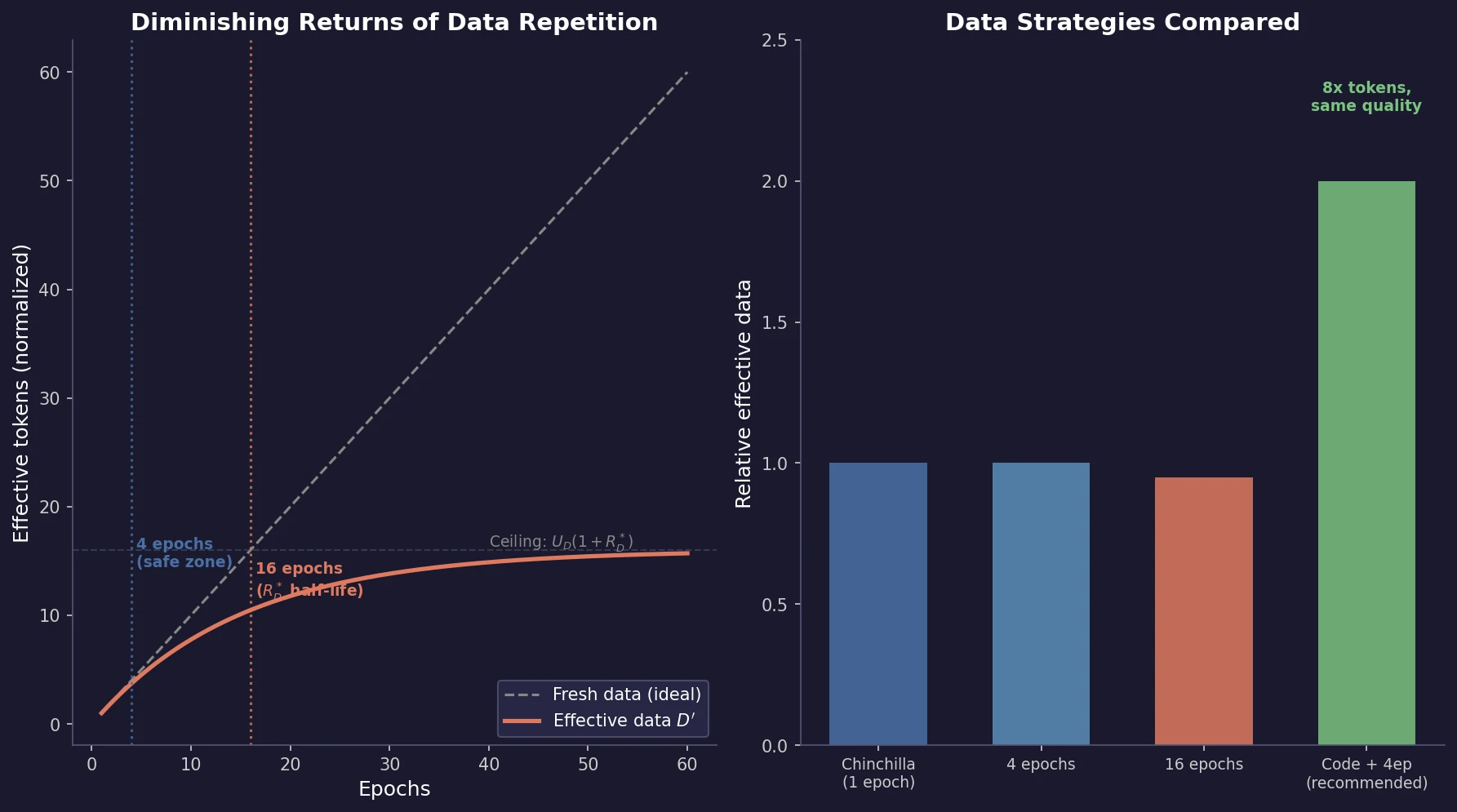
| 2023 | Scaling Data-Constrained Language Models | Scaling laws for repeated data: up to 4 epochs cause negligible loss |
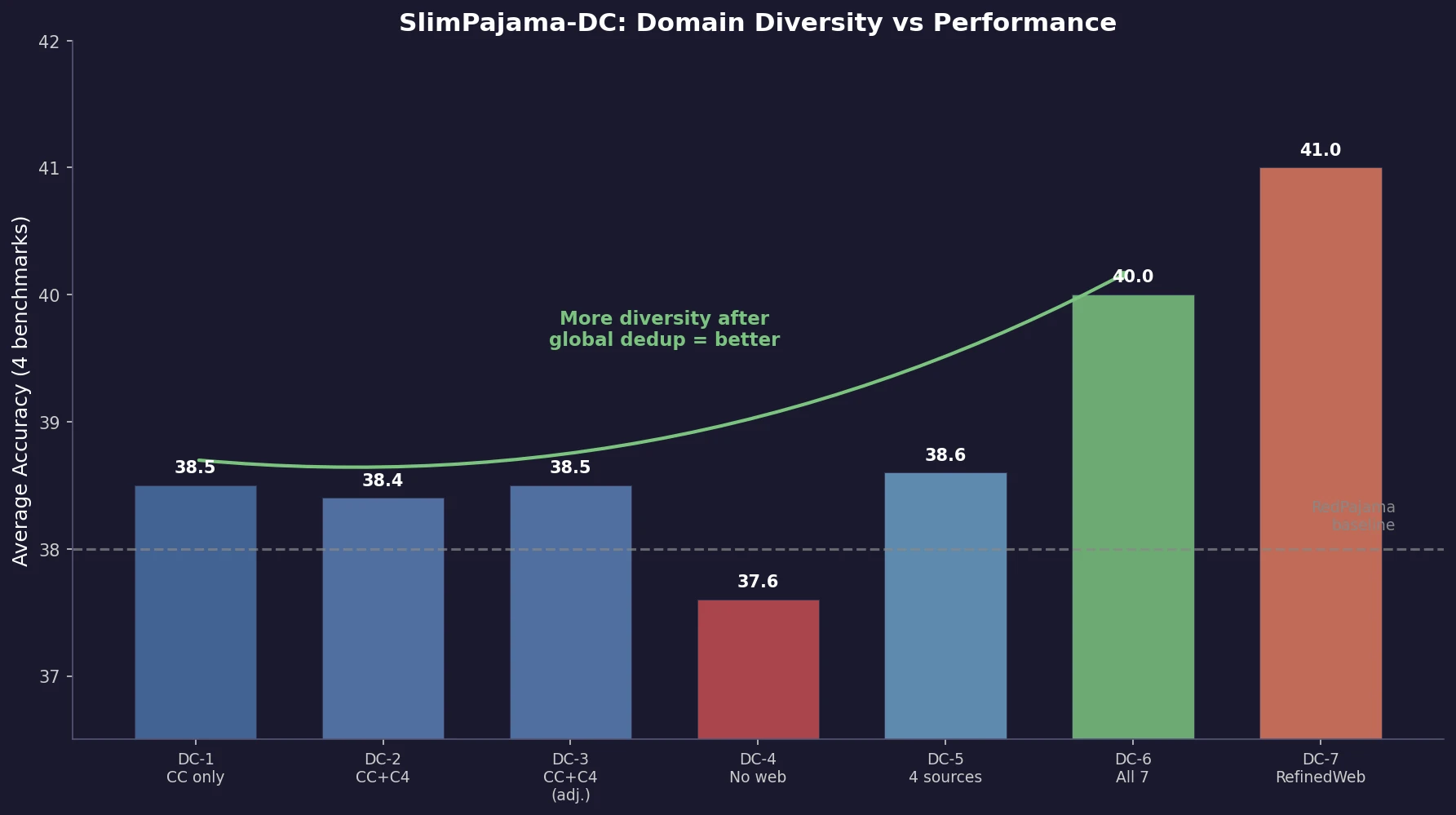
| 2023 | SlimPajama-DC | Global deduplication and domain diversity improve LLM training |
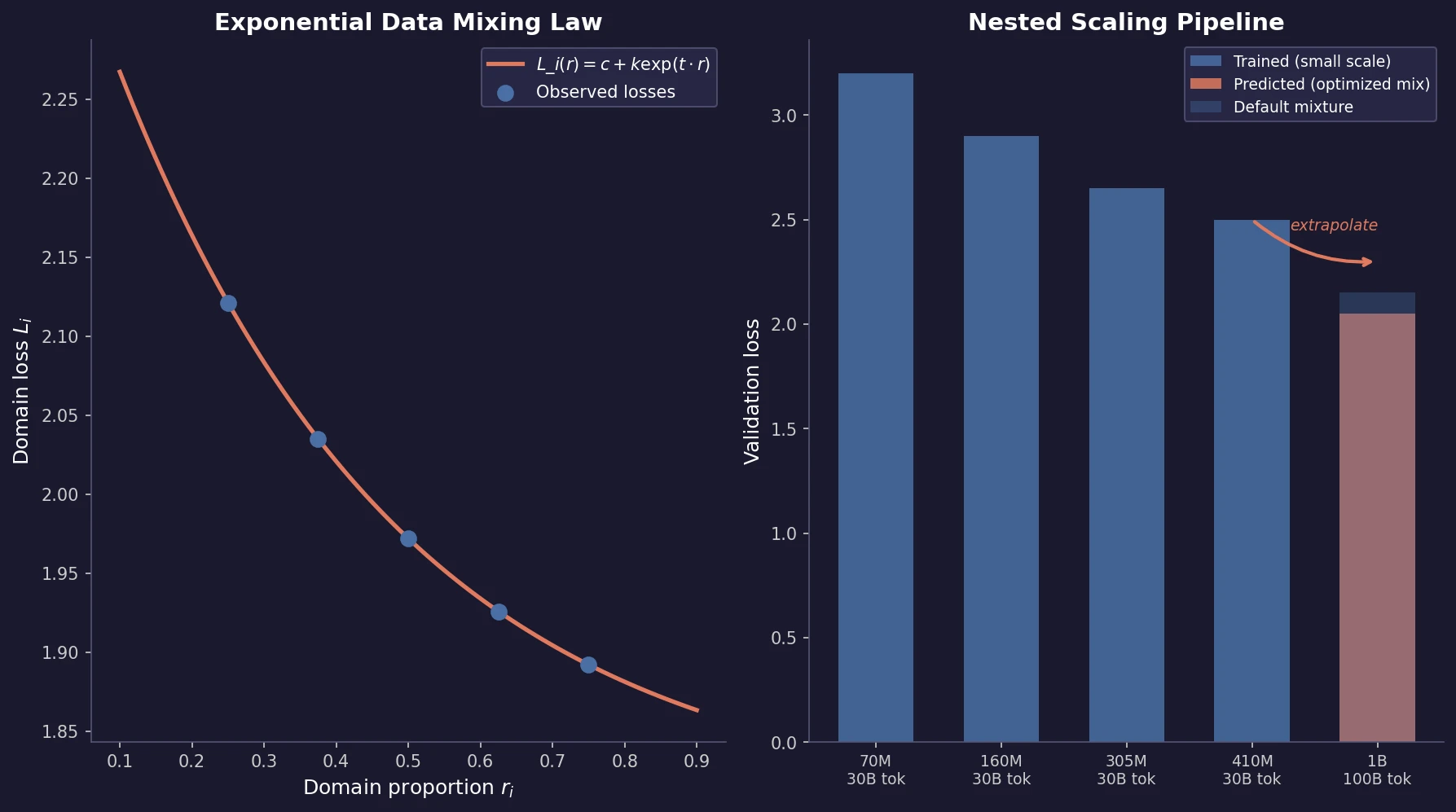
| 2025 | Data Mixing Laws for LM Pretraining | Exponential law for loss over domain mixtures enables cheap optimization |