What kind of paper is this?
This is a systematization paper that conducts a large-scale empirical comparison of how ten different model architectures scale. Rather than proposing a new architecture, it characterizes the relationship between inductive bias and scaling behavior across both upstream (pretraining) and downstream (transfer) performance.
Why architecture-aware scaling matters
Prior scaling laws work (Kaplan et al., 2020) focused almost exclusively on vanilla Transformers, finding that loss scales as a power law with model size, dataset size, and compute. A common assumption in the field is that improvements observed at one scale transfer to other scales, and new architectures are often evaluated at a single compute point (e.g., base size). This paper challenges that assumption by asking whether different inductive biases scale differently.
Ten architectures, one controlled setup
All models are implemented in Mesh TensorFlow under a shared encoder-decoder (T5-style) framework, pretrained on C4 for $2^{19}$ steps with Adafactor optimizer and inverse square root learning rate schedule, and finetuned for 100K steps on GLUE + SuperGLUE + SQuAD. Models range from 15M to 40B parameters, trained on 16 TPU-v3 chips. The ten architectures span four categories:
Transformer variants: vanilla Transformer, Evolved Transformer (AutoML-derived), Universal Transformer (parameter sharing + recurrence), Switch Transformer (sparse MoE)
Efficient variants: Performer (linear attention), Funnel Transformer (sequence downsampling), ALBERT (cross-layer parameter sharing + embedding factorization)
General improvements: Mixture of Softmaxes (MoS), Gated Linear Units (GLU)
Non-Transformers: Lightweight Convolutions, Dynamic Convolutions, MLP-Mixer
Key findings on scaling behavior
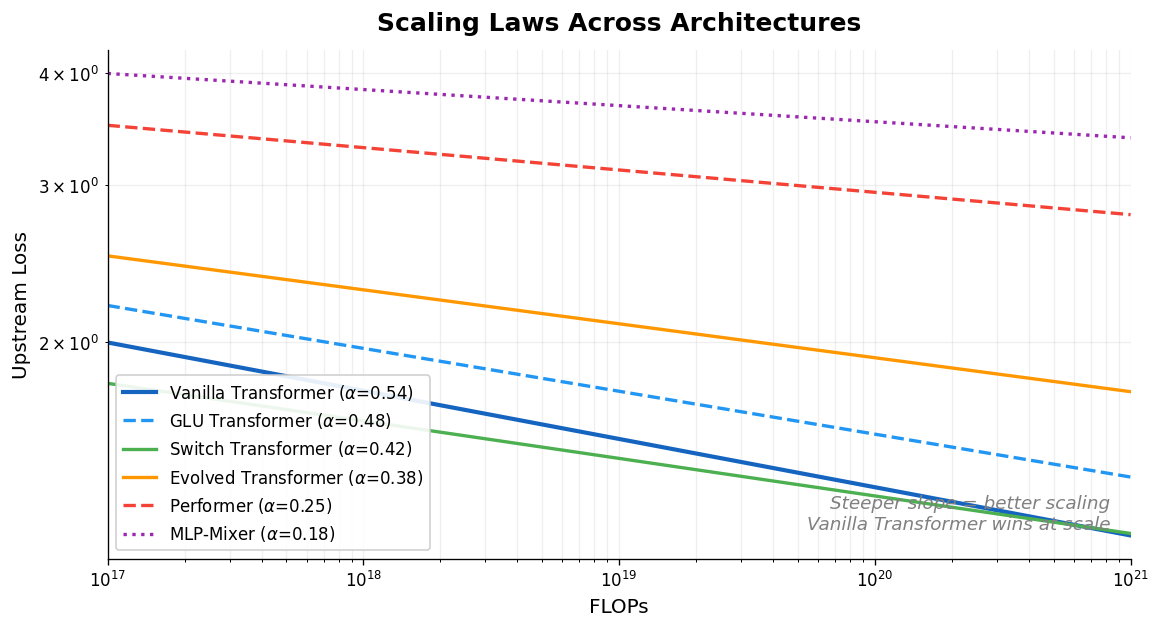
Architecture changes the scaling slope
The paper fits linear scaling laws in log-log space (i.e., power law fits of the form $L \propto C^{-\alpha}$) for each model across multiple axes (FLOPs vs. upstream, FLOPs vs. downstream, etc.). The vanilla Transformer has the highest scaling coefficient on most reported axes ($\alpha_{F,U} = 0.54$, $\alpha_{F,D} = 0.28$). Models that make minimal changes to the Transformer (GLU, MoS) retain similar scaling behavior. Models with more radical inductive biases show worse scaling:
- Performer (linear attention): $\alpha_{F,U} = 0.25$, upstream perplexity decreases only 2.7% from base to large vs. 8.4% for vanilla Transformer
- ALBERT: scales negatively on downstream ($\alpha_{F,D} = -0.12$), getting worse as compute increases. ALBERT was designed for parameter efficiency (cross-layer weight sharing, embedding factorization), not compute efficiency, so this result is expected: additional FLOPs reuse the same parameters without adding capacity
- MLP-Mixer: near-zero downstream scaling ($\alpha_{F,D} = -0.03$)
The best architecture changes with scale
Models that perform well at small compute budgets are not necessarily the best at larger budgets. For example, the Evolved Transformer outperforms vanilla Transformers at tiny-to-small scale on downstream tasks but falls behind when scaled up. MoS-Transformer outperforms vanilla Transformers at some compute regions but not others.
Upstream and downstream scaling diverge
Good upstream perplexity scaling does not guarantee good downstream transfer scaling. Funnel Transformers and Lightweight Convolutions hold up reasonably well on upstream perplexity but suffer substantially on downstream tasks. Switch Transformers show the best upstream-to-downstream transfer ratio ($\alpha_{U,D} = 0.58$).
Depth and width affect architectures differently
Depth scaling has a more substantial impact on downstream performance than width scaling across most architectures. Evolved Transformers are a partial exception, scaling slightly better under width scaling compared to other architectures on downstream tasks.
Practical implications
The authors offer concrete guidance: practitioners should be cautious about staking expensive large-scale runs on architectures that drastically modify the attention mechanism. Performers and MLP-Mixers are characterized as “high risk” options. This helps explain why most large language models at the time (PaLM, Gopher, UL2) use relatively vanilla Transformer architectures.
The paper also notes that not every use case requires billion-parameter models. Inductive biases tailored to small or low-compute regimes remain valuable when scaling is not the priority.
Reproducibility
No code or trained model weights were publicly released with this paper. The experiments rely on Google’s internal Mesh TensorFlow infrastructure with 16 TPU-v3 chips, and pretraining uses the publicly available C4 corpus. Finetuning benchmarks (GLUE, SuperGLUE, SQuAD) are all publicly available. However, reproducing the full study would require substantial compute resources and re-implementation of all ten architectures within a shared framework.
| Artifact | Type | License | Notes |
|---|---|---|---|
| arXiv paper | Paper | Open access | Full paper with appendices |
| C4 corpus | Dataset | ODC-BY | Pretraining data |
Missing components: No released code, model checkpoints, or training scripts. Internal Mesh TensorFlow codebase is not publicly available.
Paper Information
Citation: Tay, Y., Dehghani, M., Abnar, S., Chung, H. W., Fedus, W., Rao, J., Narang, S., Tran, V. Q., Yogatama, D., & Metzler, D. (2022). Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling? EMNLP 2022.
Publication: EMNLP 2022
Additional Resources:
Citation
@inproceedings{tay2022scaling,
title={Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?},
author={Tay, Yi and Dehghani, Mostafa and Abnar, Samira and Chung, Hyung Won and Fedus, William and Rao, Jinfeng and Narang, Sharan and Tran, Vinh Q. and Yogatama, Dani and Metzler, Donald},
booktitle={Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing},
year={2022}
}