A New Architecture Bridging RNNs and Transformers
This is a Method paper that introduces RWKV (Receptance Weighted Key Value), a novel sequence model architecture that combines the parallelizable training of Transformers with the efficient $O(Td)$ inference of RNNs. RWKV can be formulated equivalently as either a Transformer (for parallel training) or an RNN (for sequential inference), achieving the lowest computational and memory complexity among comparable architectures while matching Transformer-level performance. The authors scale RWKV to 14 billion parameters, making it the largest dense RNN ever trained at the time of publication.
The Quadratic Cost of Self-Attention
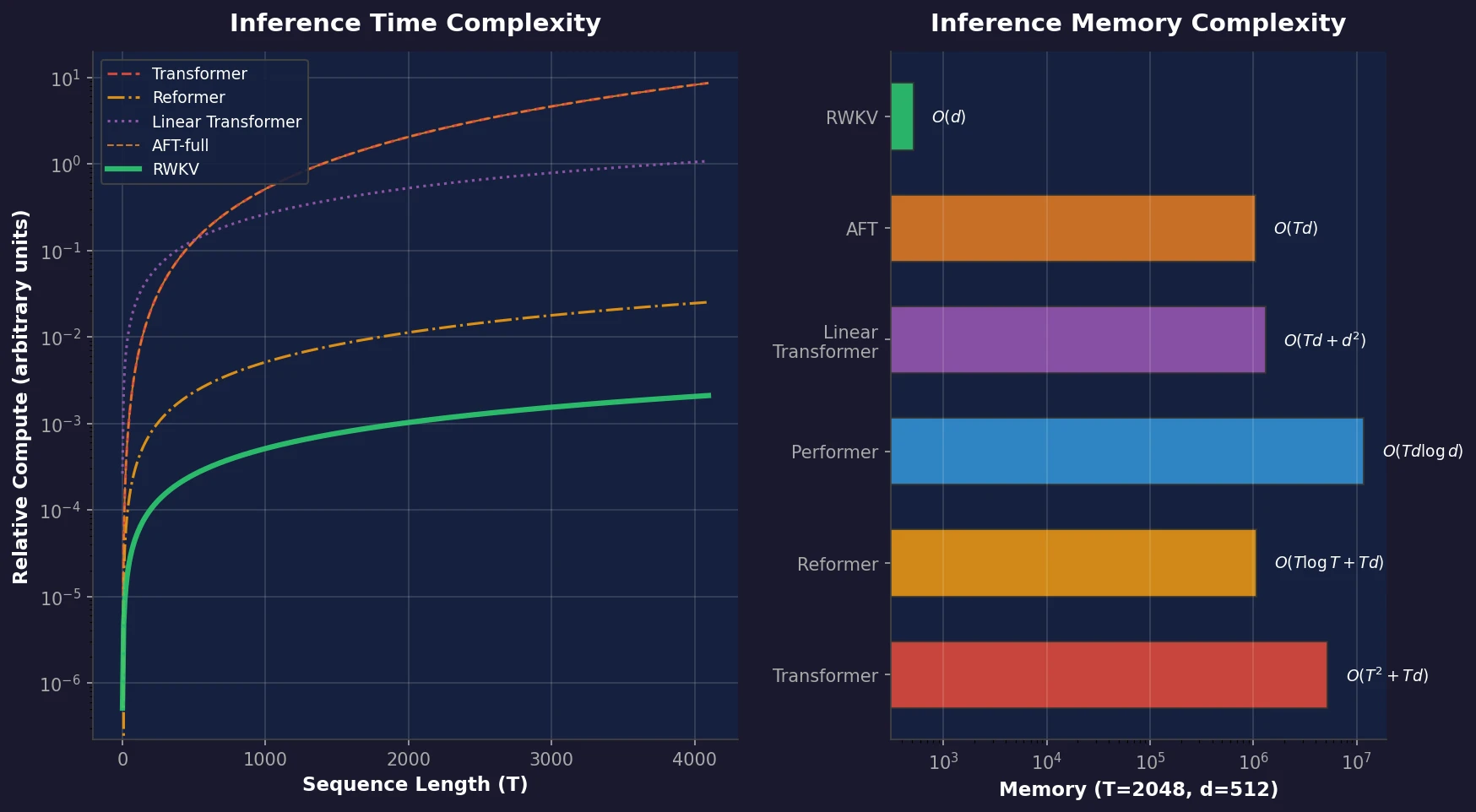
Transformers have become the dominant architecture for NLP, powering models like GPT-3, LLaMA, and Chinchilla. Their self-attention mechanism captures both local and long-range dependencies while supporting parallelized training. However, self-attention scales quadratically with sequence length in both time ($O(T^2d)$) and space ($O(T^2 + Td)$), making it computationally and memory intensive for long sequences and resource-constrained deployment.
RNNs, by contrast, offer linear scaling in memory and computation, but suffer from the vanishing gradient problem and cannot parallelize across the time dimension during training. This limits their scalability and makes them unable to match Transformer performance in practice.
Prior work on efficient Transformers (Reformer, Performer, Linformer, AFT, MEGA) has attempted to reduce this quadratic cost, often at the expense of model expressivity. RWKV aims to combine the best of both worlds: Transformer-grade training efficiency with RNN-grade inference cost, without any approximation to the attention mechanism.
Linear Attention via Channel-Wise Decay
RWKV is built on four core vectors that interact multiplicatively at each timestep:
- R (Receptance): receives past information, acting as a gating signal
- W (Weight): a trainable positional weight decay vector
- K (Key): analogous to keys in standard attention
- V (Value): analogous to values in standard attention
The architecture consists of stacked residual blocks, each containing a time-mixing sub-block and a channel-mixing sub-block.
Token Shift
All linear projection vectors are produced by interpolating between the current input $x_t$ and the previous input $x_{t-1}$, creating a token shift mechanism:
$$ r_t = W_r \cdot (\mu_r \odot x_t + (1 - \mu_r) \odot x_{t-1}) $$
$$ k_t = W_k \cdot (\mu_k \odot x_t + (1 - \mu_k) \odot x_{t-1}) $$
$$ v_t = W_v \cdot (\mu_v \odot x_t + (1 - \mu_v) \odot x_{t-1}) $$
where $\mu_r$, $\mu_k$, $\mu_v$ are learnable interpolation parameters. This is implemented efficiently as a simple offset in the temporal dimension.
The WKV Operator
The core attention-like computation replaces standard dot-product attention with a channel-wise weighted sum using exponential decay:
$$ wkv_t = \frac{\sum_{i=1}^{t-1} e^{-(t-1-i)w + k_i} \odot v_i + e^{u + k_t} \odot v_t}{\sum_{i=1}^{t-1} e^{-(t-1-i)w + k_i} + e^{u + k_t}} $$
Here $w$ is the channel-wise time decay vector and $u$ is a separate bonus vector that attends specifically to the current token. Unlike AFT where $W$ is a pairwise matrix, RWKV treats $W$ as a channel-wise vector modified by relative position, enabling the recurrent formulation.
Output Gating
The receptance vector gates the WKV output through a sigmoid:
$$ o_t = W_o \cdot (\sigma(r_t) \odot wkv_t) $$
The channel-mixing block uses a similar gating mechanism with squared ReLU activation:
$$ o’_t = \sigma(r’_t) \odot (W’_v \cdot \max(k’_t, 0)^2) $$
Dual-Mode Operation
During training, RWKV operates in time-parallel mode. The matrix multiplications ($W_\lambda$ for $\lambda \in {r, k, v, o}$) dominate at $O(BTd^2)$ and parallelize identically to standard Transformers. The element-wise WKV computation is $O(BTd)$ and parallelizes along batch and channel dimensions.
During inference, RWKV switches to time-sequential mode. Each timestep updates a fixed-size state vector, giving constant $O(d)$ memory and $O(Td)$ total time for generating $T$ tokens, compared to $O(T^2d)$ for standard Transformers.
Optimizations
Three additional design choices improve training:
- Custom CUDA kernels for the sequential WKV computation, fusing it into a single kernel on training accelerators
- Small init embedding: initializing the embedding matrix with small values plus an additional LayerNorm, accelerating convergence
- Custom initialization: most weights initialized to zero with no biases, following identity-mapping principles from residual network design
Scaling to 14B Parameters and Benchmark Evaluation
Model Scaling
The authors train six RWKV models from 169M to 14B parameters, all for one epoch (330B tokens) on the Pile:
| Model | Layers | Dimension | Parameters | FLOP/Token |
|---|---|---|---|---|
| 169M | 12 | 768 | $1.69 \times 10^8$ | $2.61 \times 10^8$ |
| 430M | 24 | 1024 | $4.30 \times 10^8$ | $7.57 \times 10^8$ |
| 1.5B | 24 | 2048 | $1.52 \times 10^9$ | $2.82 \times 10^9$ |
| 3B | 32 | 2560 | $2.99 \times 10^9$ | $5.71 \times 10^9$ |
| 7B | 32 | 4096 | $7.39 \times 10^9$ | $1.44 \times 10^{10}$ |
| 14B | 40 | 5120 | $1.42 \times 10^{10}$ | $2.78 \times 10^{10}$ |
The parameter count follows: $\text{params} = 2VD + 13D^2L + D(11L + 4)$, where $V = 50277$ is vocabulary size, $D$ is model dimension, and $L$ is layers. FLOPs match the standard transformer formula: $\text{FLOP} = 6 \cdot [\text{tokens}] \cdot [\text{params}]$.
Scaling Laws
Training 45 RWKV models across varied (dataset, parameters) pairs, the authors find that RWKV follows the same log-log linear scaling law established for Transformers. The linear fit to Pareto-optimal points achieves $r^2 = 0.994$, and extrapolation an additional order of magnitude still yields $r^2 = 0.875$. This contrasts with prior claims that LSTMs do not follow transformer-like scaling.
NLP Benchmarks
RWKV is compared against similarly-sized models trained on comparable token budgets: Pythia, OPT, and BLOOM (all FLOP-matched). Results span twelve benchmarks: ARC (Easy/Challenge), BoolQ, COPA, HeadQA, HellaSwag, LAMBADA, OpenBookQA, PIQA, ReCoRD, SciQ, and Winogrande.
RWKV performs competitively with Transformers across all model sizes. On average across benchmarks, RWKV tracks closely with Pythia and outperforms OPT and BLOOM at comparable scales.
Long Context and Extended Finetuning
RWKV can extend its context length after pretraining through progressive finetuning: doubling from 1024 to 2048 (10B tokens), then to 4096 (100B tokens), and finally to 8192 (100B tokens). Each doubling reduces test loss on the Pile, indicating effective use of longer context.
On the Long Range Arena (LRA) benchmark, which tests sequences from 1,000 to 16,000 tokens, RWKV performs second only to S4 across the five datasets.
Inference Efficiency
Benchmarking text generation on CPU (x86) and GPU (NVIDIA A100 80GB) at float32 precision shows that RWKV exhibits linear scaling in generation time, while Transformers scale quadratically. This advantage grows with sequence length: for long outputs, RWKV completes generation substantially faster at equivalent model sizes.
Competitive Performance with Key Caveats
RWKV demonstrates that RNN-class models can match Transformer performance at scale, while maintaining $O(Td)$ time and $O(d)$ memory during inference. The key findings are:
- Scaling laws hold: RWKV follows the same compute-optimal scaling as Transformers ($r^2 = 0.994$), contradicting earlier claims about RNN scaling behavior
- Competitive NLP performance: Across twelve benchmarks, RWKV matches similarly-sized Transformers trained on comparable data
- Linear inference cost: Generation time scales linearly rather than quadratically, with constant memory regardless of sequence length
- Context extension: Progressive finetuning effectively extends the context window post-training
Limitations
The authors identify two primary limitations:
Information compression: Linear attention funnels all past information through a single fixed-size state vector. For tasks requiring recall of specific details over very long contexts, this is mechanistically more constrained than full self-attention, which maintains direct access to all previous tokens.
Prompt sensitivity: RWKV is more sensitive to prompt engineering than standard Transformers. The linear attention mechanism limits how much prompt information carries forward, making the order of information in the prompt particularly important. Reordering prompts improved F1 from 44.2% to 74.8% on one task.
Future Directions
The authors suggest several avenues: applying parallel scan to reduce WKV cost to $O(B \log(T) d)$, extending RWKV to encoder-decoder and multimodal architectures, leveraging hidden states for interpretability and safety, and increasing internal state size to improve long-range recall.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Pretraining | The Pile | 330B tokens | One full epoch for all model sizes |
| Context extension | The Pile | 210B additional tokens | Progressive doubling: 1024 to 8192 |
| NLP evaluation | ARC, BoolQ, COPA, HeadQA, HellaSwag, LAMBADA, OpenBookQA, PIQA, ReCoRD, SciQ, Winogrande | Various | Zero-shot evaluation |
| Long-range evaluation | Long Range Arena (LRA) | 1K-16K tokens | Five sub-tasks |
Algorithms
- Optimizer: Adam ($\beta = (0.9, 0.99)$), no weight decay
- Precision: bfloat16
- Training context length: 1024 tokens
- Learning rate: constant warmup, then exponential decay
- Auxiliary loss from PaLM (softmax normalizer regularization)
- Batch size: 128 or 256 sequences (dynamically switched)
- Training organized into mini-epochs of 40,320 samples each (8,043 mini-epochs per Pile epoch)
Models
| Model | Init LR | Warmup Mini-Epochs | End LR |
|---|---|---|---|
| 169M | 6e-4 | 361 | 1e-5 |
| 430M | 4e-4 | 411 | 1e-5 |
| 1.5B | 3e-4 | 443 | 1e-5 |
| 3B | 1.5e-4 | 451 | 1e-5 |
| 7B | 1.5e-4 | 465 | 1e-5 |
| 14B | 1e-4 | 544 | 7e-6 |
All pretrained models (169M to 14B) are publicly released. Code is available under the Apache-2.0 license at BlinkDL/RWKV-LM.
Evaluation
- All NLP benchmarks evaluated in zero-shot setting
- FLOP-matched comparison against Pythia, OPT, BLOOM
- Inference benchmarked on CPU (x86) and GPU (NVIDIA A100 80GB) at float32
Hardware
- Inference experiments: NVIDIA A100 80GB GPU
- Training hardware details not fully specified; FLOP budgets reported per model
Paper Information
Citation: Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., … & Zhu, R.-J. (2023). RWKV: Reinventing RNNs for the Transformer Era. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 14048-14064.
Publication: Findings of EMNLP 2023
Additional Resources:
@inproceedings{peng2023rwkv,
title={RWKV: Reinventing RNNs for the Transformer Era},
author={Peng, Bo and Alcaide, Eric and Anthony, Quentin and Albalak, Alon and Arcadinho, Samuel and Biderman, Stella and Cao, Huanqi and Cheng, Xin and Chung, Michael and Derczynski, Leon and Du, Xingjian and Grella, Matteo and GV, Kranthi Kiran and He, Xuzheng and Hou, Haowen and Kazienko, Przemys{\l}aw and Koco{\'n}, Jan and Kong, Jiaming and Koptyra, Bart{\l}omiej and Lau, Hayden and Lin, Jiaju and Mantri, Krishna Sri Ipsit and Mom, Ferdinand and Saito, Atsushi and Song, Guangyu and Tang, Xiangru and Wang, Bolun and Wind, Johan S. and Wo{\'z}niak, Stanis{\l}aw and Zhang, Ruichong and Zhang, Zhenyuan and Zhao, Qihang and Zhou, Peng and Zhou, Qinghua and Zhu, Jian and Zhu, Rui-Jie},
booktitle={Findings of the Association for Computational Linguistics: EMNLP 2023},
year={2023},
doi={10.18653/v1/2023.findings-emnlp.936}
}