What kind of paper is this?
This is a systematization paper that is part position paper, part review, and part unification. It argues that combinatorial generalization, the ability to construct new inferences from known building blocks, is a top priority for AI. It frames relational inductive biases as the key design principle connecting standard deep learning architectures, presents the graph network (GN) as a general framework subsuming prior graph neural network variants, and advocates for combining structured approaches with deep learning rather than choosing between them.
The case for relational inductive biases
Human intelligence relies on representing the world as compositions of entities, relations, and rules. We understand complex systems by decomposing them into parts and their interactions. Modern deep learning’s “end-to-end” philosophy minimizes structural assumptions, relying on data and compute to learn representations from scratch. The paper argues this approach struggles with combinatorial generalization: generalizing beyond one’s experiences by composing known elements in new ways.
The authors reject the false dichotomy between “hand-engineering” and “end-to-end” learning. Just as biology uses both nature and nurture, they advocate for architectures that bake in useful structural assumptions (inductive biases) while still learning flexibly from data.
Inductive biases across standard architectures
The paper provides a systematic analysis of how existing architectures encode relational structure:
Fully connected networks (MLPs): The weakest relational inductive bias. All input units can interact with all others, with no reuse of parameters. No assumptions about the structure of the input.
Convolutional networks (CNNs): Encode locality (nearby elements interact) and translation invariance (the same local function is applied everywhere). The entities are individual units or grid elements (e.g., pixels), the relations are defined by the grid neighborhood, and the rule (convolution kernel) is shared across all positions.
Recurrent networks (RNNs): Encode sequential structure and temporal invariance. The entities are time steps, each step relates to the previous one through a shared transition function. This imposes a Markovian bias (the future depends on the present state, not the full history directly).
Sets and self-attention: Permutation invariant architectures impose no ordering on entities. Self-attention (as in Transformers) allows all pairwise interactions but with no structural prior on which interactions matter.
Each architecture can be understood as making specific commitments about what the entities are, what the relations between them are, and what rules govern their interactions.
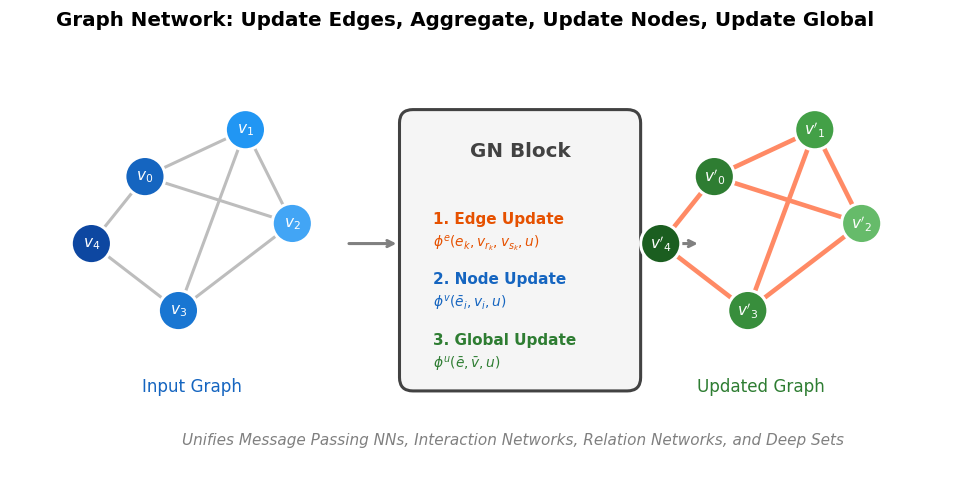
The graph network framework
The paper defines a general “graph network” (GN) block that operates on graphs with attributes on nodes, edges, and the global graph level. A GN block performs three update steps and three aggregation steps:
- Edge update: For each edge, compute updated edge attributes using the current edge attributes, the sender node attributes, the receiver node attributes, and the global attributes
- Node update: For each node, aggregate incoming updated edge attributes, then compute updated node attributes using the aggregated edges, current node attributes, and global attributes
- Global update: Aggregate all updated edge and node attributes, then compute updated global attributes
Each update function is learned (typically a small neural network), and each aggregation function must be permutation invariant (typically sum, mean, or max).
This framework generalizes prior work:
- Message Passing Neural Networks (Gilmer et al., 2017): edge and node updates with a readout function but no explicit global attribute in message passing
- Non-local Neural Networks (Wang et al., 2018): attention-weighted edge interactions
- Interaction Networks (Battaglia et al., 2016): physics-inspired message passing
- Relation Networks (Santoro et al., 2017): a simple neural network module for relational reasoning
- Discovering objects and their relations (Raposo et al., 2017): discovering objects and their relations from entangled scene representations
- Deep Sets (Zaheer et al., 2017): node-only aggregation without edge structure
- CommNet, Structure2Vec, GGNNs, and others
The paper shows how each prior approach corresponds to a specific configuration of which GN components are used and how they are connected.
Design principles for graph networks
The paper identifies several key design choices:
Flexible representations: GN blocks can output graphs with different structure than their input (e.g., predicting edge existence), enabling tasks like link prediction, clustering, or property regression.
Configurable within-block structure: The internal update and aggregation functions can be swapped freely. The framework separates what is computed (the relational structure) from how it is computed (the function approximators).
Composable multi-block architectures: GN blocks can be stacked, sharing or not sharing weights across layers. They can be composed with other architectures (e.g., an encoder-GN-decoder pattern) or arranged in recurrent configurations.
Combinatorial generalization: Because GN blocks share functions across edges and nodes, they can generalize to graphs of different sizes and topologies than those seen during training. A GN trained on small graphs can, in principle, be applied to larger ones.
Connections to broader AI themes
The paper frames graph networks as supporting:
- Relational reasoning: Learning about entities and their interactions
- Combinatorial generalization: Applying learned rules to novel combinations
- Structured prediction: Producing complex, structured outputs including graphs and sequences
- Interpretable representations: Graph structure provides a natural vocabulary for understanding what the model has learned
The authors also discuss connections to classical AI (logic, planning, causal reasoning) and argue that graph networks provide a bridge between the flexibility of deep learning and the compositionality of symbolic approaches.
Limitations and open questions
The paper identifies several limitations of graph networks:
- Graph isomorphism: Learned message-passing cannot be guaranteed to discriminate between certain non-isomorphic graphs. Kondor et al. (2018) suggested that covariance, rather than invariance to permutations, may be preferable.
- Expressivity limits of graphs: Notions like recursion, control flow, and conditional iteration are not straightforward to represent with graphs. Programs and more “computer-like” processing may offer greater representational and computational expressivity for these concepts.
- Where do graphs come from?: Converting raw sensory data (images, text) into graph-structured representations remains an open problem. Fully connected graphs between spatial or linguistic entities are a common workaround but may not reflect the true underlying structure.
- Adaptive graph structure: How to modify graph topology during computation (e.g., splitting a node when an object fractures, or adding/removing edges based on contact) is an active research direction.
Reproducibility
The authors released an open-source software library for building graph networks in TensorFlow/Sonnet, including demos for shortest-path finding, sorting, and physical prediction tasks.
| Artifact | Type | License | Notes |
|---|---|---|---|
| Graph Nets library | Code | Apache 2.0 | Official TensorFlow/Sonnet implementation with demos |
This is a position/systematization paper rather than an empirical one, so reproducibility pertains to the accompanying library rather than experimental results. The library and demos are publicly available, making the framework highly accessible.
Paper Information
Citation: Battaglia, P. W., Hamrick, J. B., Bapst, V., Sanchez-Gonzalez, A., Zambaldi, V., Malinowski, M., … & Pascanu, R. (2018). Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261.
Publication: arXiv 2018
Additional Resources:
Citation
@article{battaglia2018relational,
title={Relational inductive biases, deep learning, and graph networks},
author={Battaglia, Peter W. and Hamrick, Jessica B. and Bapst, Victor and Sanchez-Gonzalez, Alvaro and Zambaldi, Vinicius and Malinowski, Mateusz and Tacchetti, Andrea and Raposo, David and Santoro, Adam and Faulkner, Ryan and others},
journal={arXiv preprint arXiv:1806.01261},
year={2018}
}