What kind of paper is this?
This is a theory paper that takes a reductionist approach to attention mechanisms. It classifies all possible fundamental building blocks of attention (“quarks”) within a formal neural network framework, then proves capacity theorems for circuits built from these primitives using linear and polynomial threshold gates.
Why decompose attention into primitives?
Descriptions of attention in deep learning often seem complex and obscure the underlying neural architecture. Despite the widespread use of attention in transformers and beyond, there has been little formal theory about the computational nature and capacity of attention mechanisms. Baldi and Vershynin address this by identifying the smallest building blocks and rigorously analyzing what they can compute.
The Standard Model and its extensions
The paper defines the “Standard Model” (SM) as the class of all neural networks built from McCulloch-Pitt neurons: directed weighted graphs where neuron $i$ computes $O_i = f_i(S_i)$ with activation $S_i = \sum_j w_{ij} O_j$. The SM already has universal approximation properties, so extensions should be evaluated on efficiency (circuit size, depth, learning), not on what functions can be represented.
Three variable types exist in the SM: activations ($S$), outputs ($O$), and synaptic weights ($w$). Cross these with two mechanisms (addition, multiplication) and the constraint that attending signals originate from neuronal outputs, and you get six possible attention primitives.
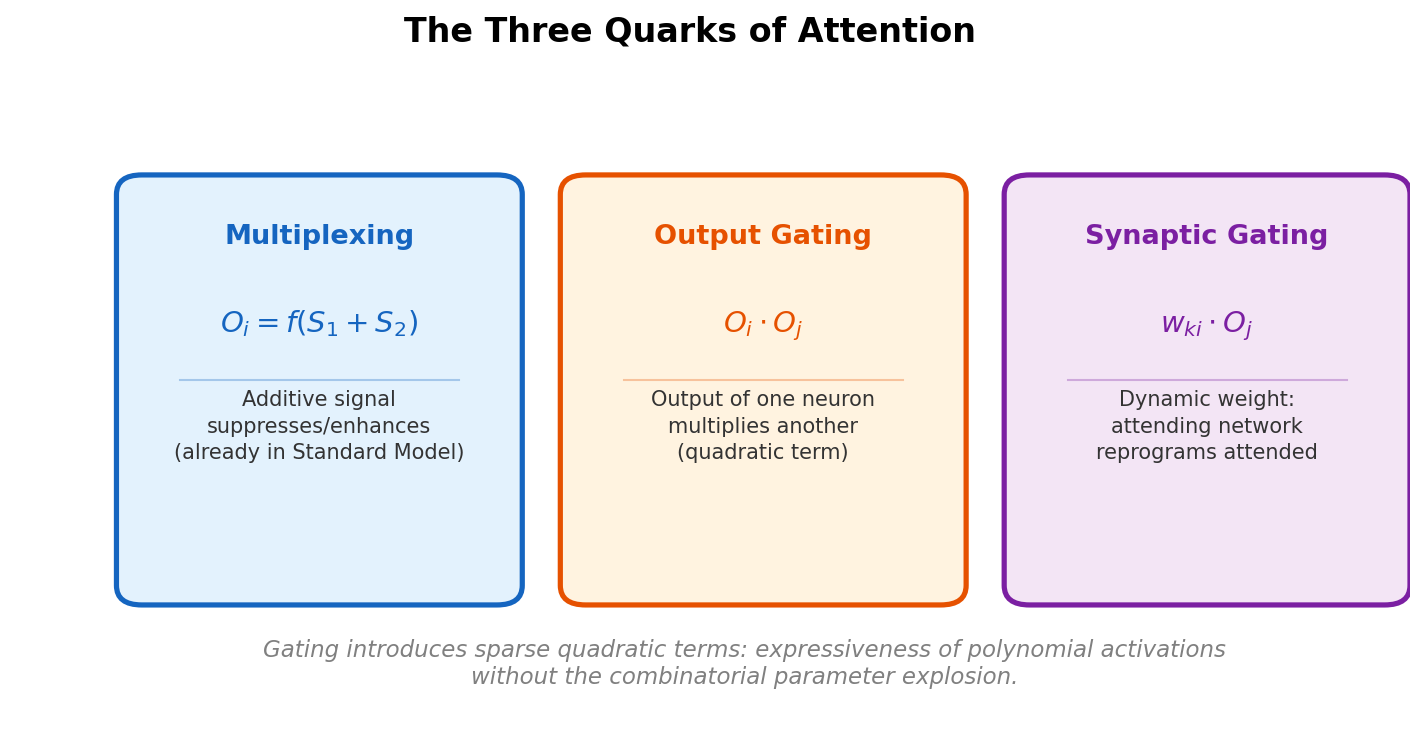
The six quarks, reduced to three
| $S$ (activation) | $O$ (output) | $w$ (synapse) | |
|---|---|---|---|
| Addition | Multiplexing (in SM) | Additive output (in SM) | Additive synaptic |
| Multiplication | Activation gating | Output gating | Synaptic gating |
The paper shows these reduce to three cases worth studying:
Multiplexing (additive activation attention)
The attending signal $S_2$ is added to the normal activation $S_1$, producing $O_i = f_i(S_1 + S_2)$. With sigmoid or threshold activations, a large negative $S_2$ forces the output to zero regardless of $S_1$, suppressing unattended stimuli. This mechanism lives entirely within the SM and plays a central role in proving capacity lower bounds.
Output gating
Neuron $j$ multiplies the output of neuron $i$, producing $O_i O_j$. This quadratic term is new to the SM. The gated signal $O_i O_j$ propagates to all downstream neurons of $i$. When $O_j \approx 0$, the attended neuron is silenced; when $O_j$ is large, it is enhanced.
Synaptic gating
Neuron $j$ multiplies a synaptic weight $w_{ki}$, creating a dynamic weight $w_{ki} O_j$. This produces the same local term $w_{ki} O_i O_j$ at neuron $k$ as output gating, but affects only the single downstream connection rather than all of neuron $i$’s outputs. Synaptic gating is a fast weight mechanism: the attending network dynamically changes the program executed by the attended network.
Transformers are built entirely from gating
The paper shows that transformer encoder modules decompose into:
- Output gating ($mn^2$ operations): computing all $n^2$ pairwise dot products of $Q$ and $K$ vectors, each requiring $m$ element-wise multiplications
- Softmax: a standard SM extension
- Synaptic gating ($n^2$ operations): weighting $V$ vectors by the softmax outputs to form convex combinations
The entire attention mechanism uses $O(mn^2)$ gating operations. The permutation invariance of transformers follows directly from the weight sharing across input positions.
Relationship to polynomial neural networks
Gating is a special case of polynomial activation. A neuron with full quadratic activation over $n$ inputs has the form $S_i = \sum_{jk} w_{ijk} O_j O_k$, requiring $O(n^2)$ three-way synaptic weights for all possible pairs. Gating introduces only one new quadratic term per operation. The same gating concepts can also be applied to more complex units with polynomial activations of degree $d$, where one polynomial threshold unit gates the output or synapse of another.
Functional properties of gating
Several examples illustrate what gating enables:
- Shaping activation functions: When a unit with activation function $f$ is output-gated by a unit with activation function $g$ (both having the same inputs), the result is $f(S)g(S) = fg(S)$. This changes the effective activation function from $f$ to $fg$. For instance, a linear unit gated by a $(0,1)$ threshold function produces the ReLU activation.
- XOR without hidden layers: The XOR function cannot be computed by a single linear threshold gate. However, gating the OR function by the NAND function (both implementable by single linear threshold gates) produces XOR in a shallow network with no hidden layers.
- Universal approximation: Every continuous function on a compact set can be approximated to arbitrary precision by a shallow attention network of linear units gated by linear threshold gates (Theorem 4.3).
Attention as sparse quadratic terms
Both output and synaptic gating introduce quadratic terms of the form $w_{ki} O_i O_j$. A neuron with full quadratic activation over $n$ inputs would require $O(n^2)$ parameters. Gating introduces only one new quadratic term per operation. This is the key insight: attention mechanisms gain some of the expressiveness of quadratic activations while avoiding the combinatorial parameter explosion.
Capacity results
Using cardinal capacity (the base-2 logarithm of the number of distinct Boolean functions a class of circuits can implement), the paper proves bounds for attentional circuits with linear and polynomial threshold gates:
- Single unit with output gating: a gated pair of linear threshold gates on $n$ inputs has capacity $2n^2(1 + o(1))$, compared to $n^2(1 + o(1))$ for a single gate (Theorem 6.1). This represents a doubling of capacity with a doubling of parameters (from $n$ to $2n$), a sign of efficiency.
- Multiplexing technique: additive activation attention enables a “multiplexing” proof strategy where one unit in a layer is selected as a function of the attending units while driving remaining units to saturation. This is the key tool for proving lower bounds.
- Attention layers: extending to layers of $m$ gated units with $n$ inputs, the capacity is $2mn^2(1 + o(1))$ for output gating (Theorem 7.1), confirming that gating approximately doubles the capacity relative to ungated layers.
- Depth reduction: gating operations available as physical primitives in a neural network can reduce the depth required for certain basic circuits.
Limitations and future work
The authors note several open directions:
- The capacity estimates for some configurations (e.g., single-weight synaptic gating in Proposition 6.9) have gaps between the lower and upper bounds that remain to be tightened.
- The analysis uses Boolean neurons (linear and polynomial threshold gates) as approximations. Extending results to other activation functions (sigmoid, ReLU) is left for future work.
- The paper focuses on single layers and pairs of units. Capacity analysis for deeper attention architectures with multiple stacked layers is not addressed.
- The theory treats attention on the time scale of individual inputs. The paper briefly notes that fast synaptic mechanisms operating on different time scales raise interesting architectural questions but does not develop this direction.
Reproducibility
This is a purely theoretical paper with no associated code, datasets, or pretrained models. All results are mathematical theorems and proofs that can be verified from the paper itself. The paper is freely available on arXiv under a CC BY-NC-ND 4.0 license.
Paper Information
Citation: Baldi, P. & Vershynin, R. (2023). The Quarks of Attention. Artificial Intelligence, 319, 103901.
Publication: Artificial Intelligence 2023
Additional Resources:
Citation
@article{baldi2023quarks,
title={The Quarks of Attention},
author={Baldi, Pierre and Vershynin, Roman},
journal={Artificial Intelligence},
volume={319},
pages={103901},
year={2023},
doi={10.1016/j.artint.2023.103901}
}