A Method for Flexible-Resolution Vision Transformers
This is a Method paper that introduces NaViT (Native Resolution ViT), a Vision Transformer trained using sequence packing to handle images of arbitrary resolution and aspect ratio. The core idea, called “Patch n’ Pack,” borrows example packing from NLP and applies it to vision: patches from multiple images of different sizes are concatenated into a single sequence, enabling native-resolution processing without resizing or padding.
Why Fixed-Resolution Pipelines Are Suboptimal
Standard computer vision pipelines resize all images to a fixed square resolution before processing. This practice originates from convolutional neural network constraints, where fixed spatial dimensions were architecturally required. Even with Vision Transformers, which operate on sequences of patches and could in principle handle variable lengths, the convention of fixed-resolution input persists.
This approach has clear drawbacks. Most images are not square: analysis of ImageNet, LVIS, and WebLI shows that over 20% of images deviate significantly from a 1:1 aspect ratio. Resizing distorts content and discards information, while padding wastes computation. Prior work like FlexiViT addressed variable patch sizes and Pix2Struct introduced aspect-ratio-preserving patching, but neither fully solved the problem of training efficiently on images at their original resolution.
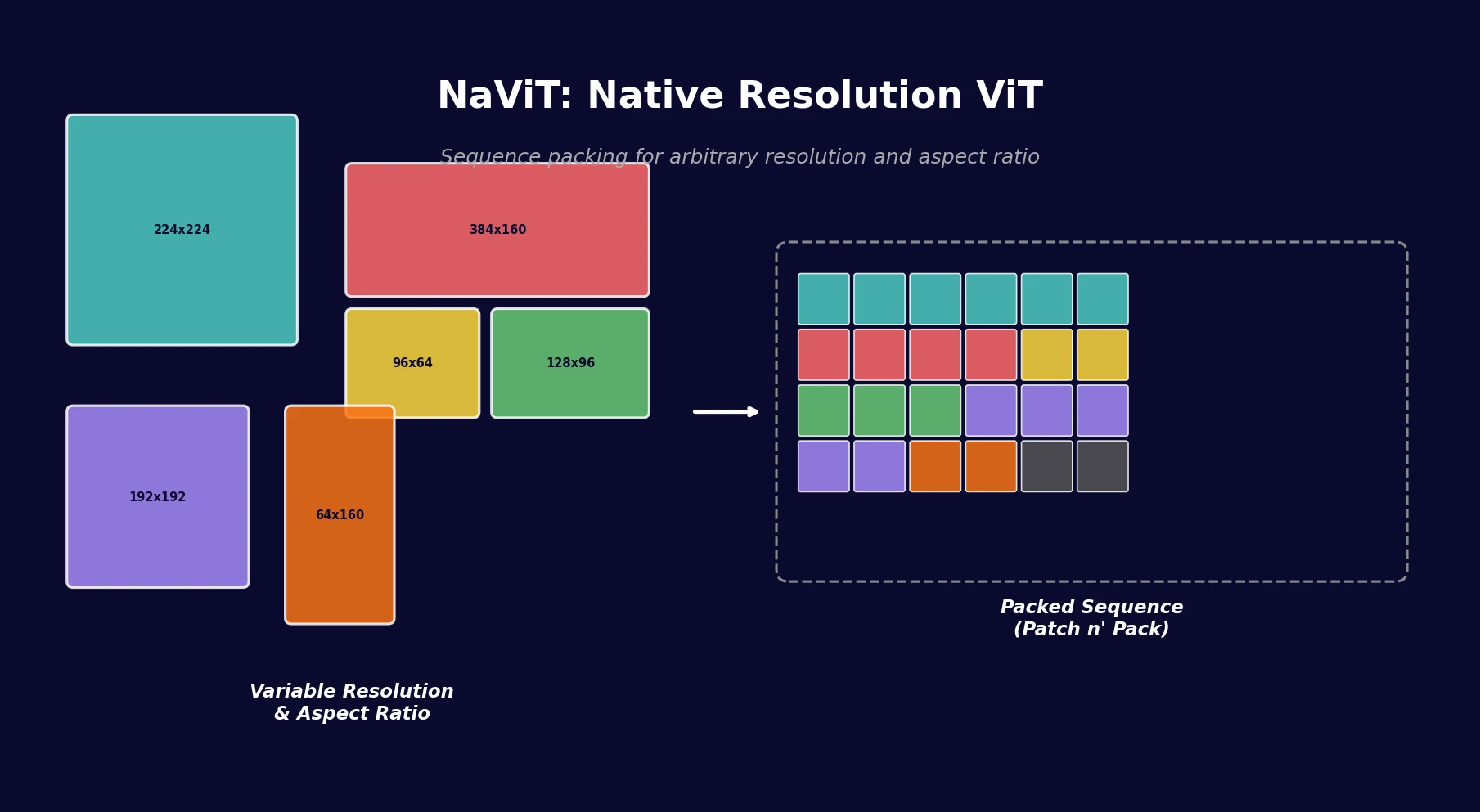
Patch n’ Pack: Sequence Packing for Vision
The key insight is that ViT already processes images as sequences of patch tokens, and NLP has long used example packing to handle variable-length sequences efficiently. NaViT applies this directly: patches from multiple images (each at its native resolution and aspect ratio) are packed into a single fixed-length sequence.
Architectural Modifications
Three changes enable Patch n’ Pack:
Masked self-attention and masked pooling: Attention masks prevent patches from different images from attending to each other. Masked pooling extracts a single representation per image from the packed sequence.
Factorized positional embeddings: Standard 1D positional embeddings cannot handle arbitrary resolutions. NaViT decomposes position into separate $x$ and $y$ embeddings $\phi_{x}$ and $\phi_{y}$, which are summed together. Two schemes are considered:
- Absolute embeddings: $\phi(p): [0, \text{maxLen}] \to \mathbb{R}^{D}$, a function of the absolute patch index
- Fractional embeddings: $\phi(r): [0, 1] \to \mathbb{R}^{D}$, where $r = p / \text{side-length}$ is the relative position along the image
Chunked contrastive loss: For contrastive pretraining, the $\mathcal{O}(n^{2})$ loss computation is handled via chunked computation across device subsets to support the high number of examples per sequence.
Training Innovations
Packing enables two techniques that were previously impractical:
Continuous token dropping: Instead of dropping the same proportion of tokens from every image, the drop rate varies per image. Some images keep all tokens while others have aggressive dropping, reducing the train/inference discrepancy. The drop rate can follow a schedule that decreases over training.
Resolution sampling: Each image’s resolution is sampled from a distribution (e.g., $R \sim \mathcal{U}(64, R_{\text{max}})$) while preserving aspect ratio. This mixes the throughput benefits of small images with the detail of large ones.
Computational Overhead
A natural concern is the $\mathcal{O}(n^{2})$ attention cost for longer packed sequences. In practice, as the transformer hidden dimension scales, attention becomes an increasingly small fraction of total compute (the MLP dominates). Packing overhead is typically less than 2% from padding tokens, using a simple greedy bin-packing algorithm.
Pretraining and Downstream Evaluation
NaViT is evaluated in two pretraining setups:
- Classification pretraining on JFT-4B with sigmoid cross-entropy loss, evaluated via linear probing (10 examples per class)
- Contrastive pretraining on WebLI using image-text contrastive loss, evaluated on zero-shot ImageNet classification and COCO retrieval
Training Efficiency
At fixed compute budget, NaViT consistently outperforms ViT across model scales. The top-performing ViT can be matched by NaViT with 4x less compute. The primary driver is throughput: packing with variable resolution and token dropping enables NaViT-L/16 to process approximately 5x more images during training.
Variable Resolution Results
Models trained with variable resolution ($R \sim \mathcal{U}(64, R_{\text{max}})$) outperform fixed-resolution models even when evaluated at the fixed resolution’s own training resolution. Sampling side lengths from a truncated normal biased toward lower values gives the best cost-performance trade-off.
For fine-tuning on ImageNet-1k, a single NaViT fine-tuned with variable resolutions (64 to 512) matches the performance of models fine-tuned at each specific resolution individually.
Positional Embedding Comparison
Factorized embeddings outperform both standard ViT 1D embeddings (with interpolation) and Pix2Struct’s learned 2D embeddings. The factorized approach generalizes to resolutions outside the training range, while 2D embeddings fail because they require seeing all $(x, y)$ coordinate pairs during training. Additive combination of $\phi_{x}$ and $\phi_{y}$ works best.
Token Dropping Strategies
Variable token dropping with Beta-distributed rates consistently outperforms constant rates. Resolution-dependent dropping (higher rates for higher-resolution images) further improves performance. Scheduling the drop rate to decrease over training provides additional gains.
Downstream Tasks
| Task | Setup | Result |
|---|---|---|
| Semantic segmentation | ADE20k, L/16, linear decoder | NaViT at $R_{384}$ beats ViT at $R_{512}$ while being 2x faster |
| Object detection | OWL-ViT-L/14 backbone | NaViT: 28.3% LVIS AP vs. ViT: 23.3% |
| Video classification | Kinetics-400, tubelet extraction | NaViT-L matches ViViT-L (80.4%) in ~6x fewer epochs |
| Fairness annotation | FairFace, CelebA linear probes | Statistically significant accuracy improvements ($p = 3 \times 10^{-4}$) |
Out-of-Distribution Robustness
NaViT shows strong gains on ImageNet-A (which contains many extreme aspect ratios) when evaluated without center cropping. Performance on ObjectNet is also competitive. The model maintains stable calibration (ECE between 0.045 and 0.047) across a wide range of token counts per image (128 to 1024).
Key Findings and Limitations
NaViT demonstrates that sequence packing, when applied to Vision Transformers, yields substantial improvements in training efficiency, inference flexibility, and downstream performance. The approach processes images at their native resolution without the information loss from resizing or the waste from padding.
Key takeaways:
- 4x compute reduction to match top ViT performance
- A single model works across a continuous range of resolutions at inference time
- Variable-resolution training and token dropping provide complementary efficiency gains
- Factorized positional embeddings generalize to unseen resolutions
- Benefits transfer to detection, segmentation, video, and fairness tasks
Limitations: The paper does not release model weights or code. All experiments use Google-internal datasets (JFT-4B, WebLI) and infrastructure (TPUs, JAX/Scenic), making direct reproduction difficult. The attention masking approach for packing assumes that cross-image attention is undesirable, which may not hold for all tasks.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Classification pretraining | JFT-4B | ~4B labeled images | Google-internal, not publicly available |
| Contrastive pretraining | WebLI | Large-scale web data | Google-internal, not publicly available |
| Classification fine-tuning | ImageNet-1k | 1.28M images | Publicly available |
| Segmentation | ADE20k | 20K images | Publicly available |
| Detection | LVIS | 164K images | Publicly available |
| Video | Kinetics-400 | ~240K videos | Publicly available (partial) |
| Fairness | FairFace, CelebA | 108K / 200K images | Publicly available |
Algorithms
- Greedy bin-packing for sequence construction (less than 2% padding tokens)
- Resolution sampling: side length from truncated normal $\mathcal{N}_{t}(-0.5, 1)$ mapped to $[64, R_{\text{max}}]$
- Token dropping: Beta-distributed per-image rates, optionally resolution-dependent
- Factorized positional embeddings with additive combination
Models
- NaViT variants: B/16, L/16, L/14
- Based on vanilla ViT with query-key normalization, no biases, attention pooling
- Implemented in JAX/FLAX within the Scenic framework
- No public model checkpoints available
Evaluation
| Metric | NaViT | ViT Baseline | Notes |
|---|---|---|---|
| JFT linear probe (L/16) | Matches top ViT | 4x more compute | Compute-matched comparison |
| ImageNet zero-shot (L/14) | 72.9% | 68.3% | Contrastive pretraining |
| LVIS AP (L/14) | 28.3% | 23.3% | OWL-ViT detection |
| LVIS AP rare (L/14) | 24.3% | 17.2% | OWL-ViT detection |
| ADE20k mIoU (L/16, 384) | Beats ViT@512 | At 2x cost | Segmenter linear decoder |
Hardware
- Training on Cloud TPUs (specific configuration not detailed)
- Inference latency measured on Cloud TPUv3
Paper Information
Citation: Dehghani, M., Mustafa, B., Djolonga, J., Heek, J., Minderer, M., Caron, M., Steiner, A., Puigcerver, J., Geirhos, R., Alabdulmohsin, I., Oliver, A., Padlewski, P., Gritsenko, A., Lučić, M., & Houlsby, N. (2023). Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution. Advances in Neural Information Processing Systems 36 (NeurIPS 2023).
@misc{dehghani2023patch,
title={Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution},
author={Dehghani, Mostafa and Mustafa, Basil and Djolonga, Josip and Heek, Jonathan and Minderer, Matthias and Caron, Mathilde and Steiner, Andreas and Puigcerver, Joan and Geirhos, Robert and Alabdulmohsin, Ibrahim and Oliver, Avital and Padlewski, Piotr and Gritsenko, Alexey and Lučić, Mario and Houlsby, Neil},
year={2023},
eprint={2307.06304},
archiveprefix={arXiv},
primaryclass={cs.CV}
}