What kind of paper is this?
This is a theory paper that provides a principled derivation of gating mechanisms in recurrent neural networks from an axiom of invariance to time transformations. The theoretical insights also yield a practical contribution: the chrono initialization for LSTM gate biases.
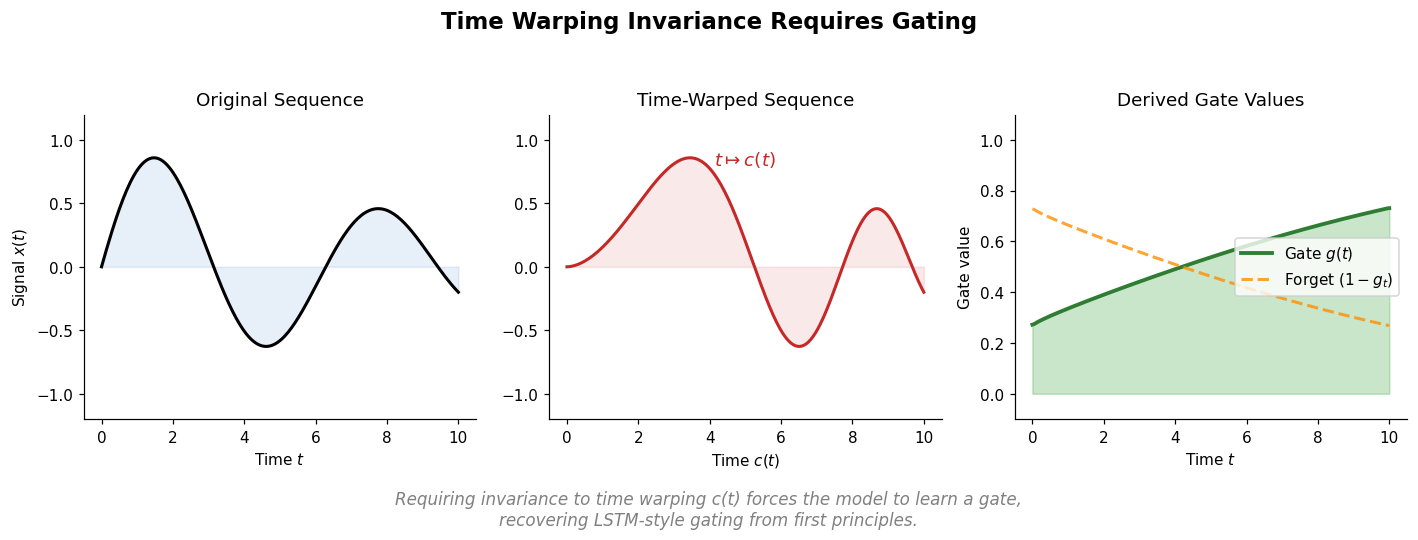
Why time warping invariance matters for recurrent models
Standard recurrent neural networks are highly sensitive to changes in the time scale of their input data. Inserting a fixed number of blank steps between elements of an input sequence can make an otherwise easy task impossible for a vanilla RNN to learn. This fragility arises because the class of functions representable by an ordinary RNN is not closed under time rescaling.
The vanishing gradient problem compounds this issue: learning long-term dependencies requires gradient signals to persist across many time steps, but stability of the dynamical system causes these signals to decay exponentially. Prior solutions include gating mechanisms (LSTMs, GRUs) introduced on engineering grounds, and orthogonal weight constraints that limit representational power and make forgetting difficult.
Tallec and Ollivier ask a clean theoretical question: what structural properties must a recurrent model have to be invariant to arbitrary time transformations in its input?
Deriving gates from time warping invariance
The core insight starts from the continuous-time formulation of a basic RNN:
$$\frac{\mathrm{d}h(t)}{\mathrm{d}t} = \tanh(W_x x(t) + W_h h(t) + b) - h(t)$$
Applying a time warping $t \gets c(t)$ (any increasing differentiable function) to the input data $x(c(t))$ transforms this equation into:
$$\frac{\mathrm{d}h(t)}{\mathrm{d}t} = \frac{\mathrm{d}c(t)}{\mathrm{d}t} \tanh(W_x x(t) + W_h h(t) + b) - \frac{\mathrm{d}c(t)}{\mathrm{d}t} h(t)$$
The derivative $\frac{\mathrm{d}c(t)}{\mathrm{d}t}$ of the time warping appears as a multiplicative factor. For the model class to represent this equation for any time warping, a learnable function $g(t)$ must replace the unknown derivative:
$$\frac{\mathrm{d}h(t)}{\mathrm{d}t} = g(t) \tanh(W_x x(t) + W_h h(t) + b) - g(t) h(t)$$
Discretizing with a Taylor expansion ($\delta t = 1$) yields:
$$h_{t+1} = g_t \tanh(W_x x_t + W_h h_t + b) + (1 - g_t) h_t$$
This is a gated recurrent network with input gate $g_t$ and forget gate $(1 - g_t)$, where $g_t$ is computed by a sigmoid function of the inputs. The value $1/g(t_0)$ represents the local forgetting time of the network at time $t_0$.
The special case of linear time rescaling
For the simpler case of a constant time rescaling $c(t) = \alpha t$, the same derivation produces a leaky RNN:
$$h_{t+1} = \alpha \tanh(W_x x_t + W_h h_t + b) + (1 - \alpha) h_t$$
Leaky RNNs are invariant to global time rescalings but fail with variable warpings. Full gating (where $g_t$ depends on the input) is required for invariance to general time warpings.
Per-unit gates and the connection to LSTMs
Extending to per-unit gates $g_t^i$ allows different units to operate at different characteristic timescales:
$$h_{t+1}^i = g_t^i \tanh(W_x^i x_t + W_h^i h_t + b^i) + (1 - g_t^i) h_t^i$$
This closely resembles the LSTM cell update equation, where $(1 - g_t^i)$ corresponds to the forget gate $f_t$ and $g_t^i$ corresponds to the input gate $i_t$. The derivation naturally ties these two gates (they sum to 1), a constraint that has been used successfully in practice.
Chrono initialization for gate biases
The theoretical framework provides a principled initialization strategy. If the sequential data has temporal dependencies in a range $[T_{\text{min}}, T_{\text{max}}]$, then gate values $g$ should lie in $[1/T_{\text{max}}, 1/T_{\text{min}}]$. Since gate values center around $\sigma(b_g)$ when inputs are centered, the biases should be initialized as:
$$b_g \sim -\log(\mathcal{U}([T_{\text{min}}, T_{\text{max}}]) - 1)$$
For LSTMs specifically, the chrono initialization sets:
$$b_f \sim \log(\mathcal{U}([1, T_{\text{max}} - 1]))$$ $$b_i = -b_f$$
where $T_{\text{max}}$ is the expected range of long-term dependencies. This contrasts with the standard practice of setting forget gate biases to 1 or 2.
Experimental validation
Time warping robustness
On a character recall task with artificially warped sequences, three architectures are compared (64 units each):
- Vanilla RNNs fail with even moderate warping coefficients
- Leaky RNNs perfectly solve uniform warpings but fail with variable warpings
- Gated RNNs achieve perfect performance under both uniform and variable warpings for all tested warping factors
This directly validates the theory: leaky RNNs handle constant time rescalings, but only gated models handle general time warpings.
Synthetic tasks (copy and adding)
Using 128-unit LSTMs:
- Copy task ($T = 500, 2000$): Chrono initialization converges to the solution while standard initialization plateaus at the memoryless baseline
- Variable copy ($T = 500, 1000$): Chrono matches standard for smaller $T$ but outperforms for $T = 1000$
- Adding task ($T = 200, 750$): Chrono converges significantly faster, approximately 7x faster for $T = 750$
Real-world tasks
- Permuted MNIST (512-unit LSTM): Chrono achieves 96.3% vs. 95.4% for standard initialization
- Character-level text8 (2000-unit LSTM): Slight improvement (1.37 vs. 1.38 bits-per-character)
- Word-level Penn Treebank (10-layer RHN): Comparable results to the baseline (65.4 test perplexity)
Short-term dependency tasks show minimal differences, consistent with the theory that chrono initialization primarily helps when long-term dependencies dominate.
Limitations
The continuous-to-discrete time correspondence relies on a Taylor expansion with step size $\delta t = 1$. This approximation holds when the derivative of the time warping is not too large ($g_t \lesssim 1$). Discrete-time gated models are therefore invariant to time warpings that stretch time (such as interspersing data with blanks or introducing long-term dependencies), but they cannot handle warpings that compress events faster than the model’s time step. Additionally, the chrono initialization requires specifying $T_{\text{max}}$, the expected range of long-term dependencies, which may not be known in advance.
Reproducibility
Status: Partially Reproducible.
The paper describes all hyperparameters, architectures, and training procedures in sufficient detail to reproduce the experiments. The synthetic tasks (copy, adding, time warping) follow standard setups from prior work with clearly specified parameters. The real-world experiments (permuted MNIST, text8, Penn Treebank) use established benchmarks with referenced codebases (the text8 setup reuses code from Cooijmans et al. 2016).
The chrono initialization itself requires minimal implementation effort: it only changes the bias initialization of gate units, with no modifications to the model architecture or training procedure.
No official code repository is provided by the authors. No pre-trained models or datasets beyond standard benchmarks are released.
Paper Information
Citation: Tallec, C. & Ollivier, Y. (2018). Can recurrent neural networks warp time? International Conference on Learning Representations (ICLR 2018).
Publication: ICLR 2018
Additional Resources:
Citation
@inproceedings{tallec2018can,
title={Can recurrent neural networks warp time?},
author={Tallec, Corentin and Ollivier, Yann},
booktitle={International Conference on Learning Representations},
year={2018}
}