A Method for Combining Attention with Block-Level Recurrence
This is a Method paper that introduces the Block-Recurrent Transformer, a model architecture that integrates recurrence into the transformer framework at the block level. Rather than processing tokens one at a time (as in traditional RNNs) or attending over entire sequences (as in standard transformers), this approach applies a transformer layer recurrently across blocks of tokens. The result is a model with linear complexity in sequence length that maintains the parallelism benefits of transformers during training. A related approach, RWKV, later explored similar ideas using linear attention with channel-wise decay.
Why Transformers Struggle with Long Documents
Transformers have largely replaced RNNs for sequence modeling tasks, but their quadratic self-attention cost limits the length of sequences they can process. A transformer with a window size of 512 tokens cannot see information beyond that window, making it blind to long-range dependencies in books, technical papers, or source code repositories.
Prior approaches to this problem fall into several categories: sparse attention patterns (BigBird, Routing Transformers, Reformer), sequence compression (Linformer, Funnel Transformers), and linearized attention approximations. These methods either sacrifice the expressiveness of full softmax attention or introduce implementation complexity.
Traditional RNNs like LSTMs offer linear complexity but suffer from three key limitations: sequential processing prevents parallelism on modern hardware, a single state vector bottlenecks information capacity, and vanishing gradients limit effective memory to a few hundred tokens.
Block-Level Recurrence with LSTM-Style Gates
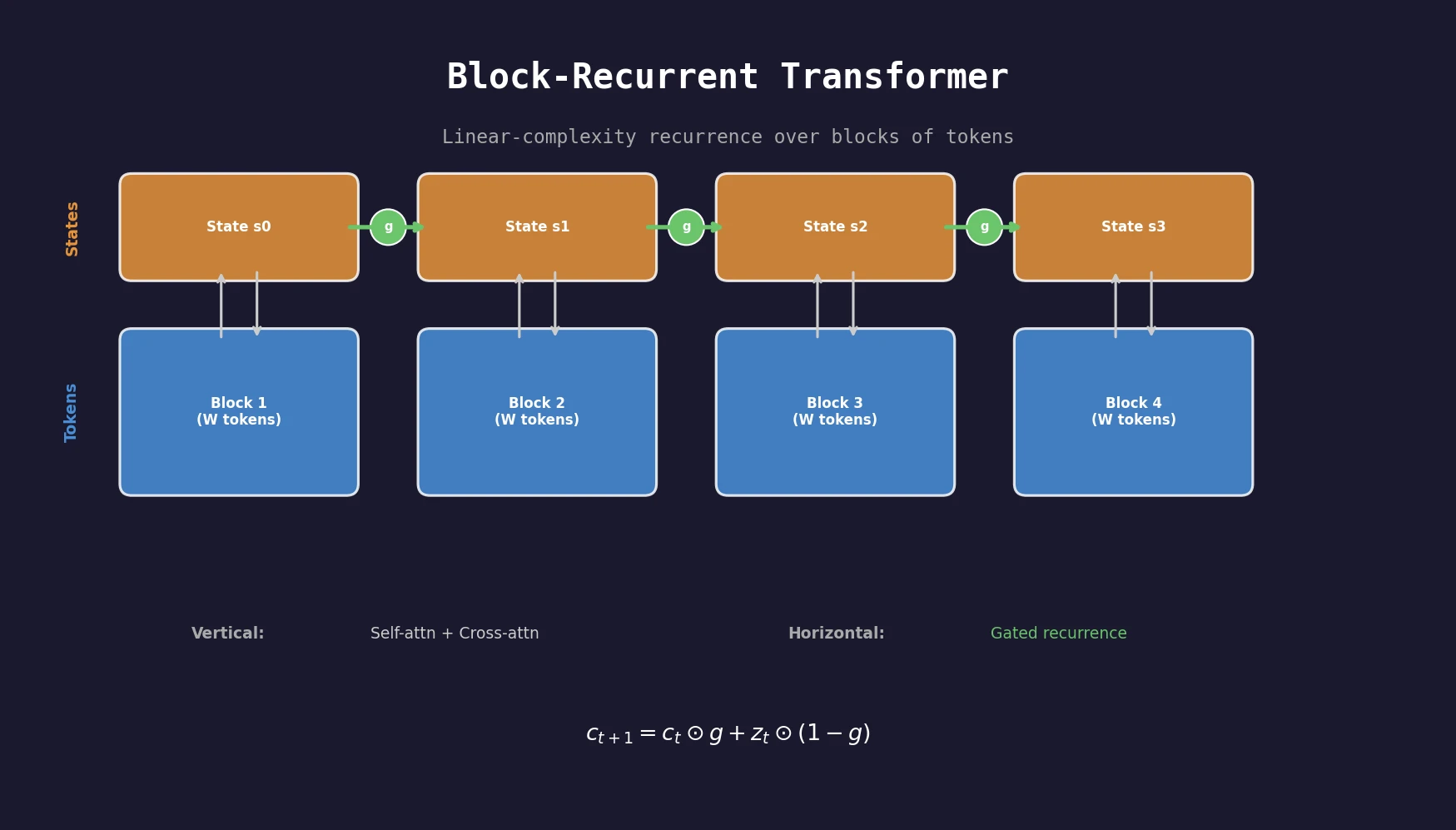
The core innovation is applying a standard transformer layer in a recurrent fashion along the sequence, operating on blocks of $W$ tokens rather than individual tokens. The recurrent cell maintains $S$ state vectors (typically $S = W = 512$) that are updated at each block boundary.
The Recurrent Cell
The cell has two processing directions:
- Vertical direction: An ordinary transformer layer with self-attention over input tokens and cross-attention to recurrent states, producing output embeddings.
- Horizontal direction: Self-attention over current state vectors and cross-attention to input tokens, producing updated state vectors. Residual connections are replaced with gates.
Self-attention and cross-attention are computed in parallel (not sequentially), with results concatenated and fed into a linear projection. Keys and values are shared between directions, while queries are separate, yielding four query sets: $Q_e^v$, $Q_s^v$ (vertical) and $Q_s^h$, $Q_e^h$ (horizontal).
Gating Mechanisms
Two gate types are explored. The fixed gate uses a learned convex combination:
$$ g = \sigma(b_g) $$
$$ c_{t+1} = c_t \odot g + z_t \odot (1 - g) $$
where $g$ is constant after training, implementing an exponential moving average.
The LSTM gate uses input and forget gates:
$$ i_t = \sigma(W_i h_t + b_i - 1) $$
$$ f_t = \sigma(W_f h_t + b_f + 1) $$
$$ c_{t+1} = c_t \odot f_t + z_t \odot i_t $$
The bias offsets ($-1$ for input, $+1$ for forget) initialize the model to “remember” by default, which is critical for training stability. Without careful initialization, the model can fall into a local optimum where it ignores the recurrent state entirely. This echoes the gate initialization challenges studied by Tallec and Ollivier, who derived chrono initialization for LSTMs from time-warping invariance.
Gate Configurations
Three configurations are tested: dual (gates on both attention and MLP outputs), single (gate only on MLP output), and skip (gate only on attention output, no MLP). The skip configuration removes the large MLP from the recurrent layer entirely.
Learned State IDs
Since the same weights are applied to all state vectors, learned “state IDs” (analogous to position embeddings) are added so each state vector can issue distinct queries. T5-style relative position bias is used for token self-attention, with no position bias for state-token cross-attention.
Language Modeling on PG19, arXiv, and GitHub
Experimental Setup
The base model is a 12-layer transformer with 150M parameters (8 heads of size 128, embedding dimension 1024, MLP hidden size 4096). The recurrent layer is placed at layer 10 with segment length $N = 4096$ and window size $W = 512$. The architecture is evaluated on three long-document datasets:
- PG19: Full-length books from Project Gutenberg (pre-1919)
- arXiv: Mathematics papers in LaTeX
- GitHub: Concatenated source code from open-source repositories
All models report bits-per-token ($\log_2$ perplexity, lower is better).
Baselines
Five baselines are compared: Transformer-XL with window sizes of 512, 1024, and 2048, plus 12-layer and 13-layer sliding window models. The 13-layer sliding window (Slide:13L) is the primary comparison, having equivalent computation cost and parameter count to the recurrent models.
Main Results
| Model | Step Time | PG19 (bytes) | PG19 (tokens) | arXiv | GitHub |
|---|---|---|---|---|---|
| XL:512 | 0.88 | 1.01 | 3.62 | 1.45 | 1.21 |
| XL:2048 | 2.11 | 0.990 | 3.58 | 1.31 | 1.01 |
| Slide:13L | 1.00 | 0.989 | 3.58 | 1.42 | 1.17 |
| Rec:fixed:skip | 0.99 | 0.952 | 3.53 | 1.24 | 0.976 |
| Rec:fixed:dual | 1.01 | 0.957 | 3.52 | 1.27 | 0.991 |
| Feedback:fixed:skip | 1.35 | 0.935 | 3.49 | 1.24 | - |
| Memorizing Trans. 64k | 1.94 | 0.950 | 3.53 | 1.22 | - |
The Rec:fixed:skip configuration achieves the best overall results while being slightly faster than the 13-layer baseline. It outperforms XL:2048, which runs over 2x slower. The block feedback variant (allowing all layers to cross-attend to recurrent states) improves perplexity further at ~35-40% higher step time.
Scaling Behavior
Models from 40M to 1.3B parameters show that the benefit of recurrence is consistent across scales and increases with model size. At larger sizes, adding recurrence provides a benefit greater than doubling the number of parameters. The 1.3B parameter model achieves 26.50 word-level perplexity on PG19, setting a new state of the art at the time of publication.
| Model | Layers | PG19 Perplexity | Parameters |
|---|---|---|---|
| Compressive Transformer | 36 | 33.6 | - |
| Routing Transformer | 22 | 33.2 | 490M |
| Perceiver AR | 60 | 28.9 | 974.6M |
| Block-Recurrent Transformer | 24 | 26.50 | 1.3B |
Ablations
- Multiple recurrent layers: Two adjacent layers (9, 10) provide no benefit. Two separated layers (4, 10) help but no more than adding another non-recurrent layer.
- Number of states: Improvement up to 1024 states, degradation at 2048.
- Window size reduction: Reducing the sliding window hurts Transformer-XL dramatically but has smaller impact on the recurrent model, which compensates via recurrence.
- Gate type: The fixed gate consistently outperforms the LSTM gate despite being theoretically less expressive.
Qualitative Analysis
Comparing per-token predictions against Transformer-XL on PG19 books, the recurrent model’s advantage comes overwhelmingly from predicting proper names (17/20 top-improvement tokens). In 19/20 cases, the predicted word was outside the attention window, confirming it was stored in recurrent state. The model can remember book titles and authors across 60,000+ tokens.
Findings, Limitations, and Future Directions
The Block-Recurrent Transformer demonstrates that recurrence at the block level is a cost-effective way to improve language modeling on long sequences. The fixed:skip configuration (the simplest variant) performs best, suggesting the model primarily uses recurrence for long-range name lookup rather than complex reasoning. The fact that removing the MLP from the recurrent layer has minimal impact further supports this interpretation.
Key limitations include: the model was only evaluated on language modeling perplexity (no downstream tasks), the LSTM gate underperforms the simpler fixed gate (suggesting untapped potential for more expressive recurrence), and the authors acknowledge that training the recurrent layer to fully exploit its capacity for knowledge extraction will require further advances.
The authors note that evaluating on downstream tasks requiring long-range context (book summarization, long-document QA, code completion) is an important direction for future work.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Training/Eval | PG19 | ~29k books | Public domain, freely available |
| Training/Eval | arXiv | Mathematics papers | Obtained via private channels, not redistributable |
| Training/Eval | GitHub | Open-source repos | Obtained via private channels, not redistributable |
Algorithms
- Optimizer: Adafactor
- Learning rate: 1.0 with inverse square root decay (initial experiments), cosine decay with max 0.01 (scaling experiments)
- Warmup: 1000 steps
- Dropout: 0.05
- Vocabulary: 32k SentencePiece (T5 pretrained for initial, custom for scaling)
- Gate initialization: bias of $+1$ for forget gate, $-1$ for input gate to ensure initial “remember” behavior
Models
| Variant | Layers | Parameters | Recurrent Layers |
|---|---|---|---|
| Base | 12 (+1 recurrent) | ~151-164M | Layer 10 |
| Large | 24 (+2 recurrent) | 650M | Layers 10, 20 |
| XL | 24 (+2 recurrent) | 1.3B | Layers 10, 20 |
Evaluation
| Metric | Best Model | PG19 (tokens) | arXiv | GitHub |
|---|---|---|---|---|
| Bits-per-token | Rec:fixed:skip | 3.53 | 1.24 | 0.976 |
| Word-level PPL | 1.3B model | 26.50 | - | - |
Error bars on PG19 are between 0.002 and 0.007 (3 runs with different seeds).
Hardware
- Training: 32 Google V4 TPU replicas
- Training time: ~48 hours for 500k steps on PG19
- Batch size: 32 (segment length 4096) or 256 (segment length 512), adjusted so each model sees the same tokens per step
Artifacts
| Artifact | Available | License | URL |
|---|---|---|---|
| Code (Meliad) | Yes | Apache 2.0 | github.com/google-research/meliad |
| PG19 Dataset | Yes | Public Domain | Public |
| arXiv Dataset | No | Not redistributable | Private |
| GitHub Dataset | No | Not redistributable | Private |
| Pretrained Models | No | - | - |
Reproducibility Assessment: Partially Reproducible. Source code is available under Apache 2.0 and the PG19 dataset is public. However, two of three evaluation datasets (arXiv, GitHub) were obtained via private channels and are not redistributable. No pretrained model checkpoints are released.
Paper Information
Citation: Hutchins, D., Schlag, I., Wu, Y., Dyer, E., & Neyshabur, B. (2022). Block-Recurrent Transformers. Advances in Neural Information Processing Systems 35 (NeurIPS 2022).
@misc{hutchins2022block,
title={Block-Recurrent Transformers},
author={Hutchins, DeLesley and Schlag, Imanol and Wu, Yuhuai and Dyer, Ethan and Neyshabur, Behnam},
year={2022},
eprint={2203.07852},
archiveprefix={arXiv},
primaryclass={cs.LG}
}