Different architectural choices encode different inductive biases: how a model processes sequences, aggregates information, or shares parameters all shape what it can learn efficiently. Notes in this section cover the design, analysis, and comparison of neural network architectures, including how structural decisions affect scaling properties, expressivity, and generalization. The focus is on understanding architectures along axes beyond specific symmetry groups (which fall under geometric deep learning).
| Year | Paper | Key Idea |
|---|---|---|
| 1949 | Communication in the Presence of Noise | Shannon’s information theory, channel capacity, and sampling theorem |
| 1984 | Distributed Representations | Theoretical efficiency of coarse coding over local representations |
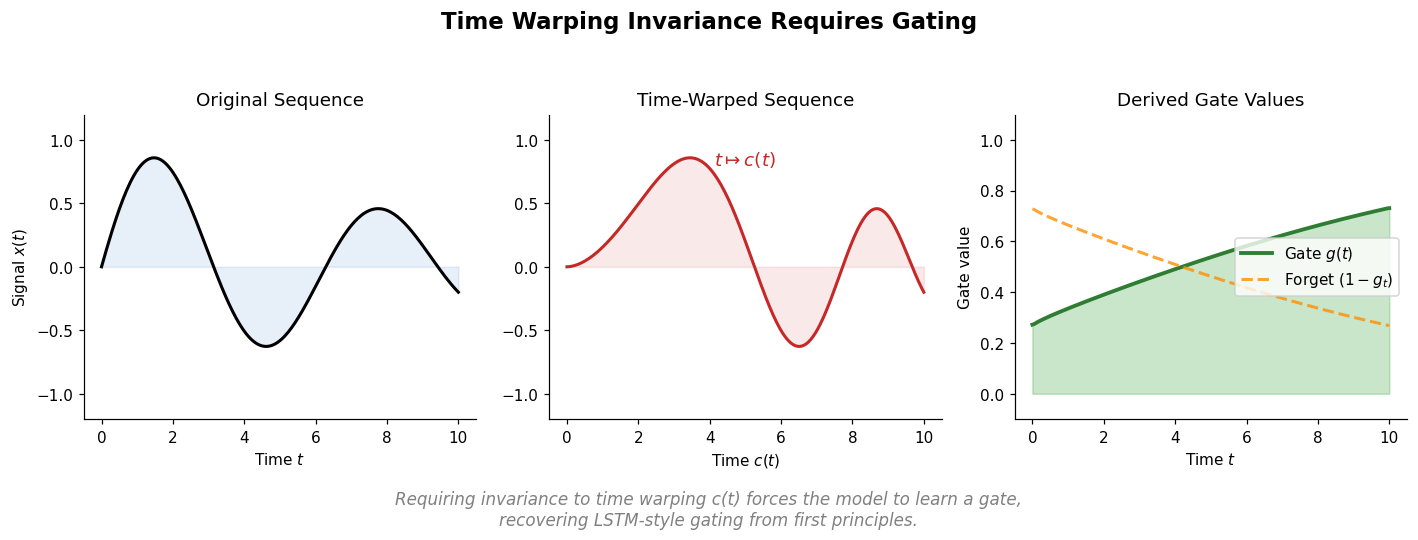
| 2018 | Can Recurrent Neural Networks Warp Time? | Deriving gating from time-warping invariance; chrono initialization |
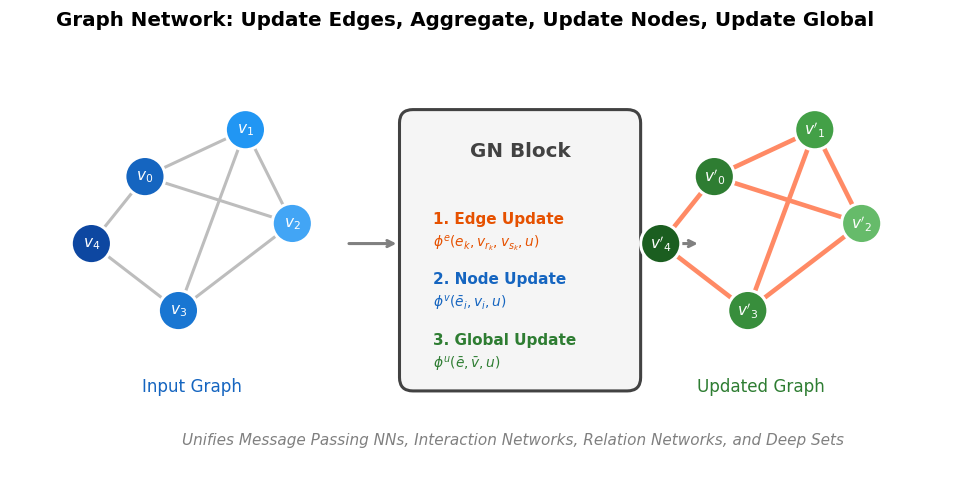
| 2018 | Relational Inductive Biases in Deep Learning | Unifying graph neural network variants under a general GN framework |
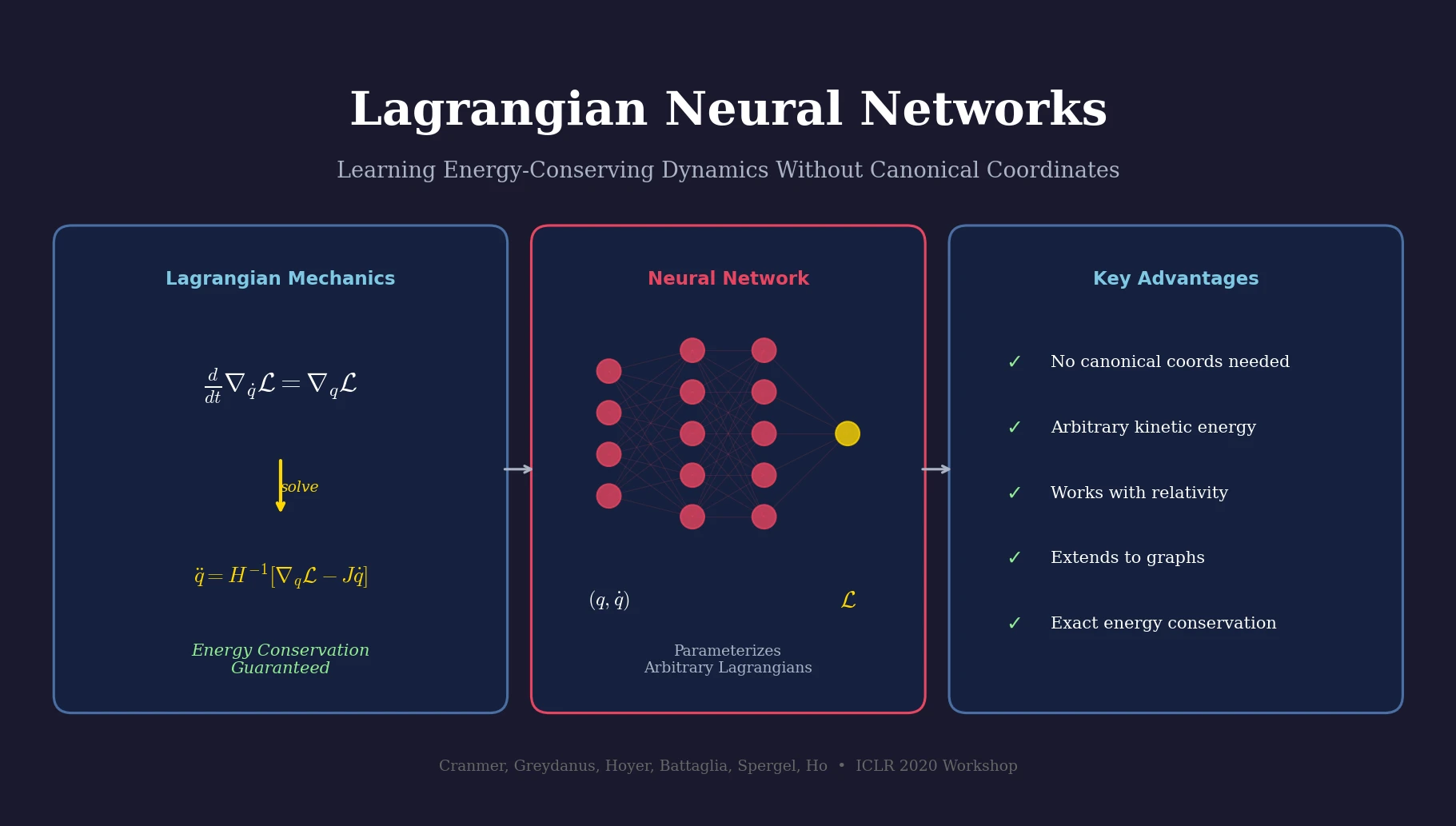
| 2020 | Lagrangian Neural Networks | Energy-conserving dynamics from learned Lagrangians, no canonical coords |
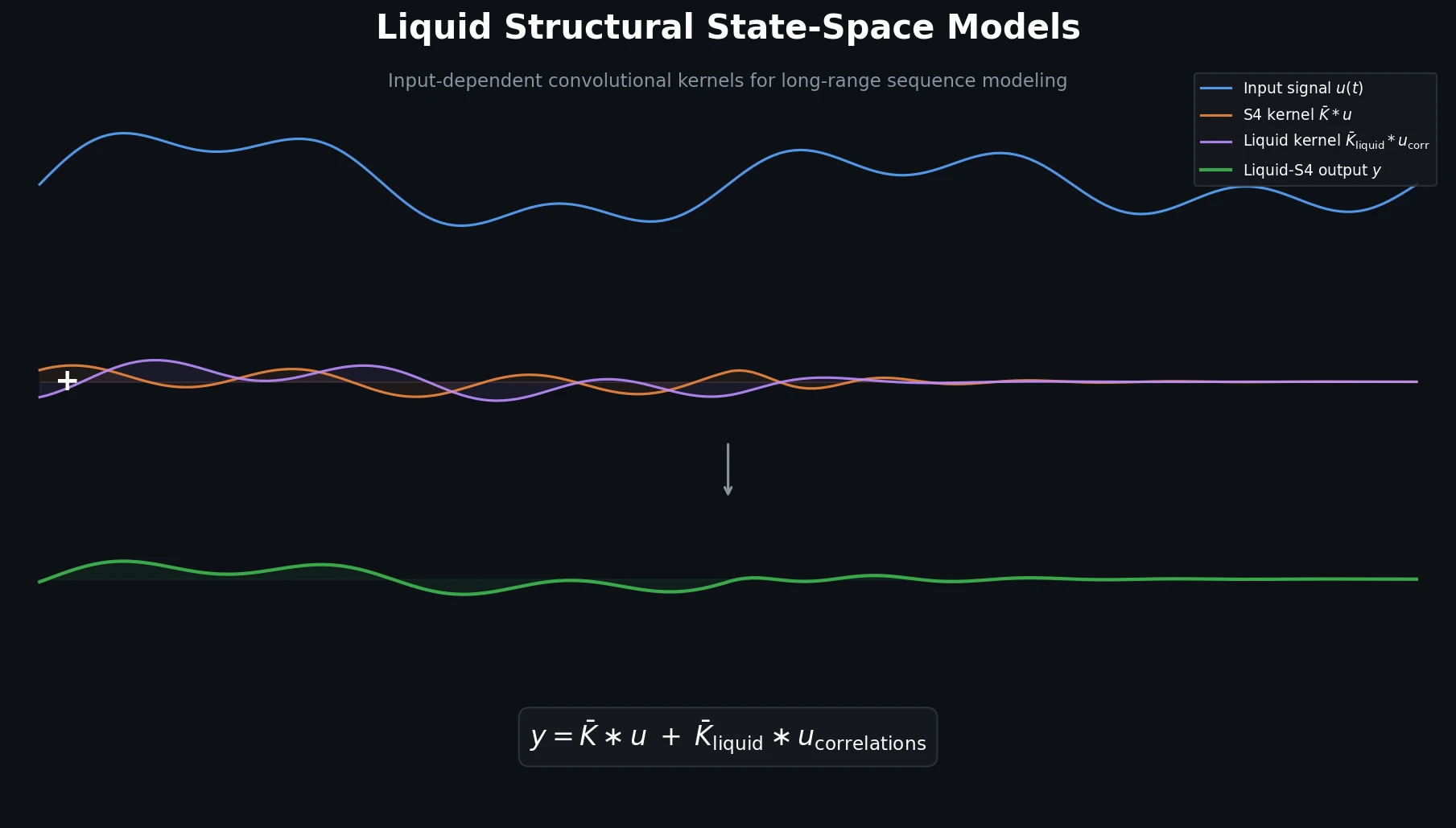
| 2022 | Liquid-S4 | Input-dependent state transitions for structured state-space models |
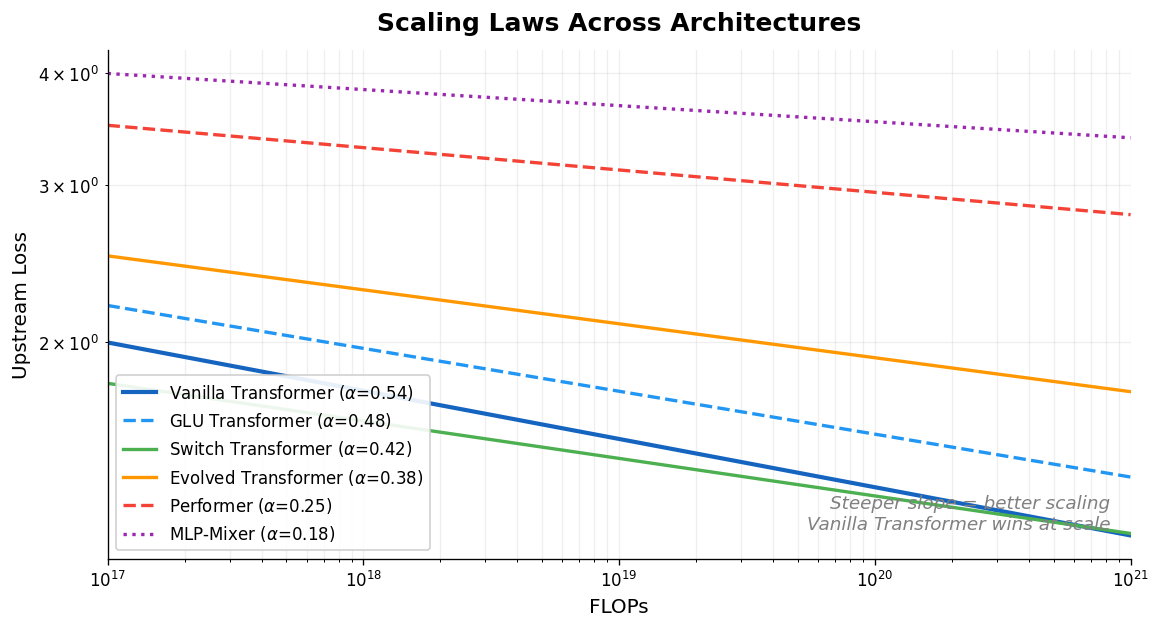
| 2022 | Scaling Laws vs Model Architectures | Comparing scaling behavior across ten architectures |
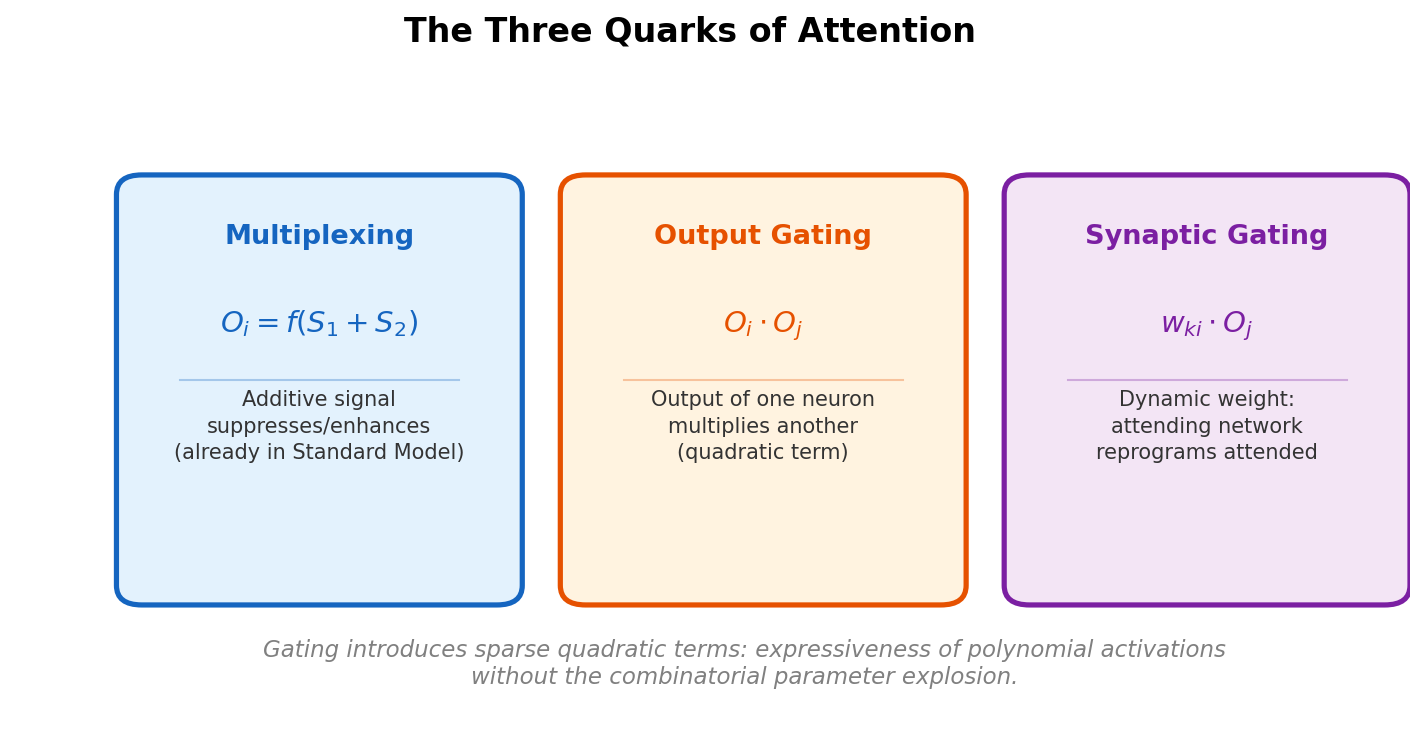
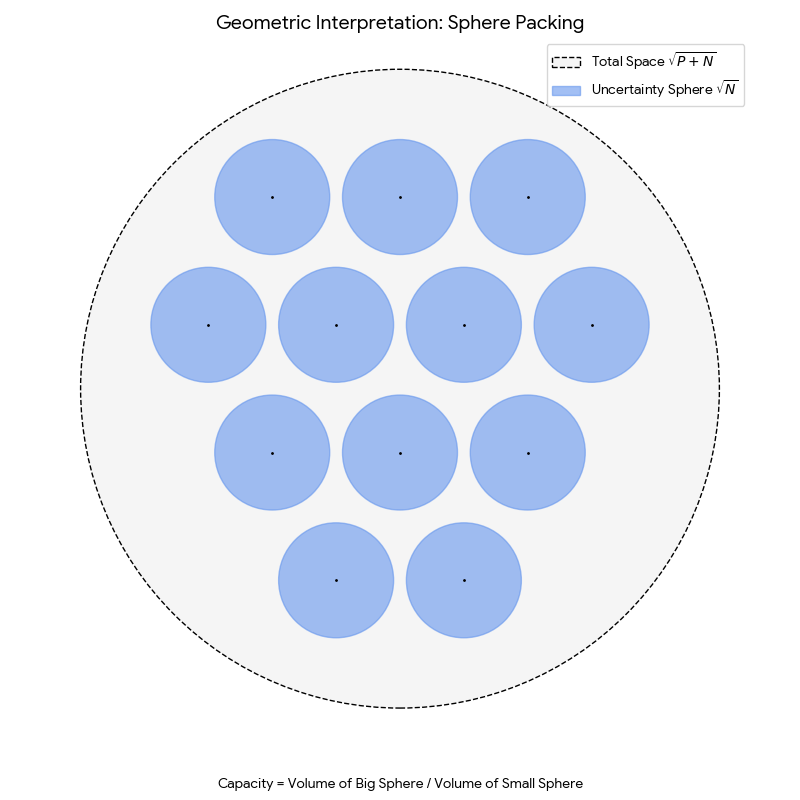
| 2023 | The Quarks of Attention | Decomposing attention into fundamental building blocks with capacity bounds |
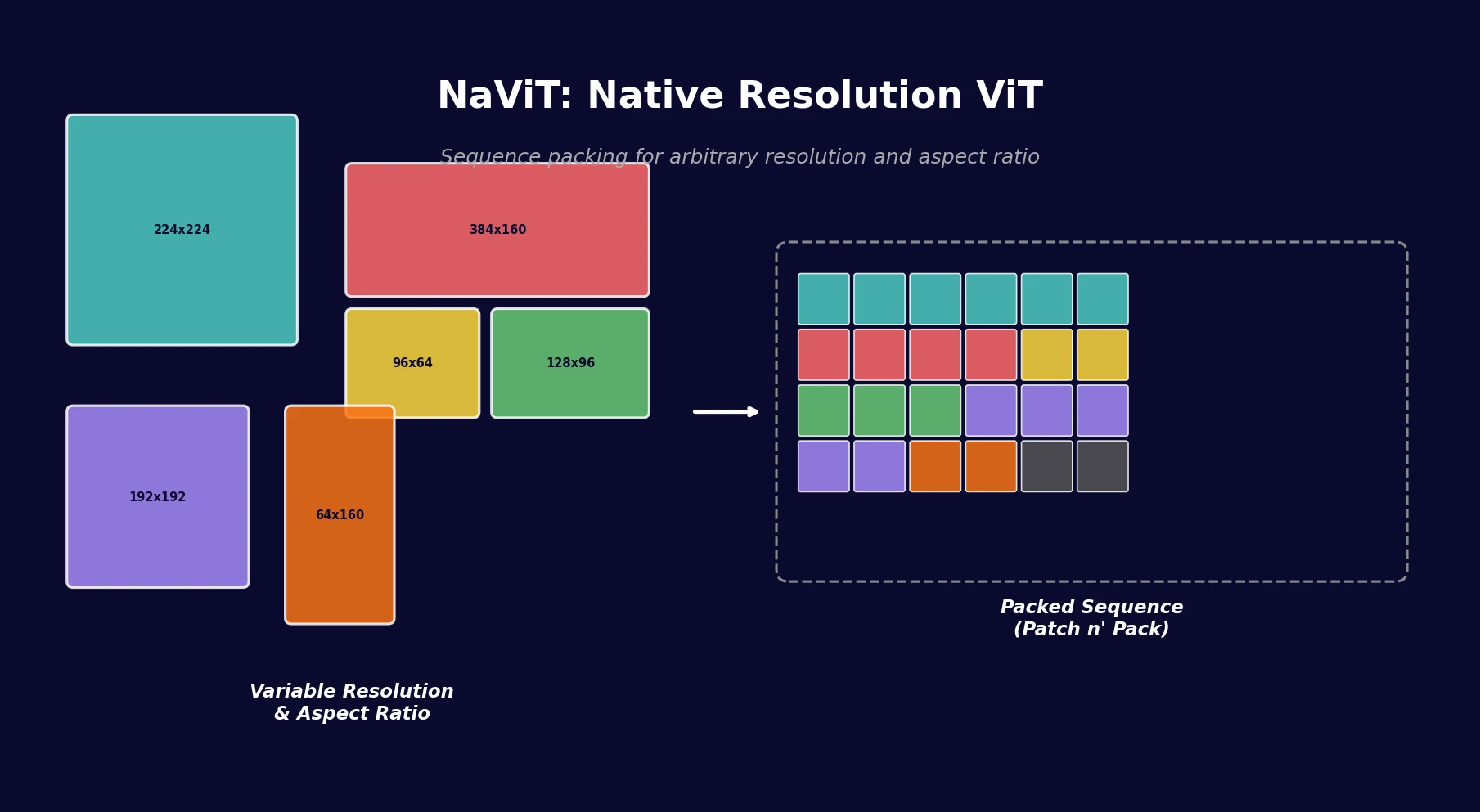
| 2023 | NaViT | Sequence packing for native-resolution Vision Transformers |