Notes on neural network architecture design, comparison, scaling behavior, and inductive biases across model families.
Different architectural choices encode different inductive biases: how a model processes sequences, aggregates information, or shares parameters all shape what it can learn efficiently. Notes in this section cover the design, analysis, and comparison of neural network architectures, including how structural decisions affect scaling properties, expressivity, and generalization. The focus is on understanding architectures along axes beyond specific symmetry groups (which fall under geometric deep learning).
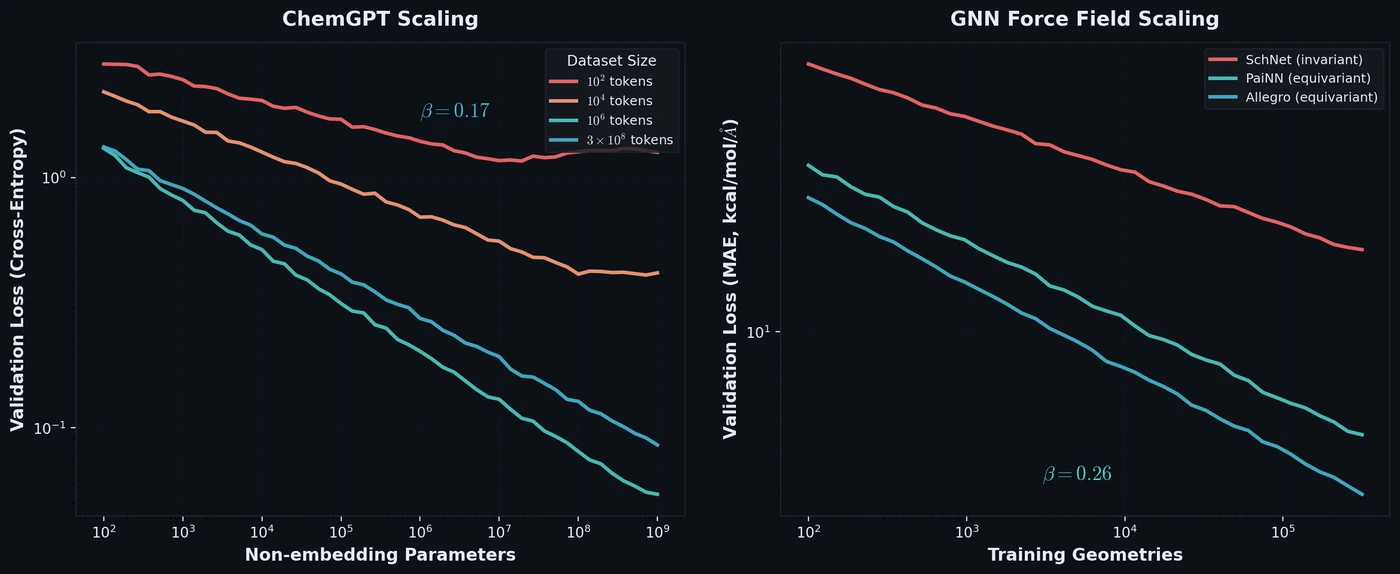
Frey et al. discover empirical power-law scaling relations for both chemical language models (ChemGPT, up to 1B parameters) and equivariant GNN interatomic potentials, finding that neither domain has saturated with respect to model size, data, or compute.
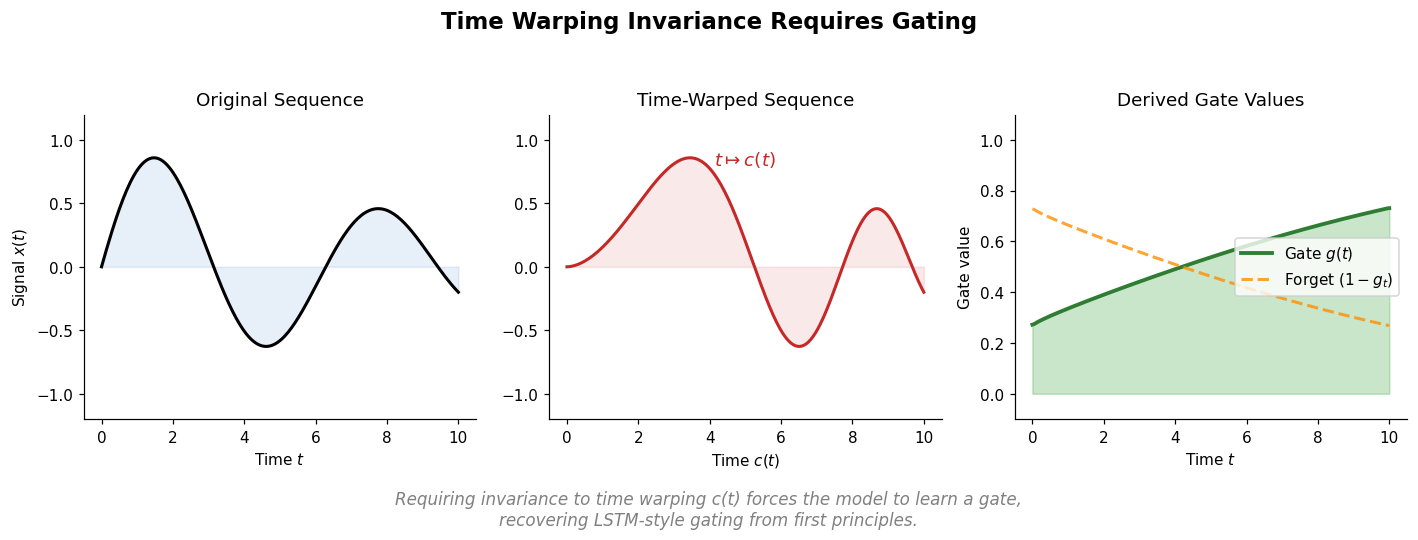
Can Recurrent Neural Networks Warp Time? (ICLR 2018)
Tallec and Ollivier show that requiring invariance to time transformations in recurrent models leads to gating mechanisms, recovering key LSTM components from first principles. They propose the chrono initialization for gate biases that improves learning of long-term dependencies.
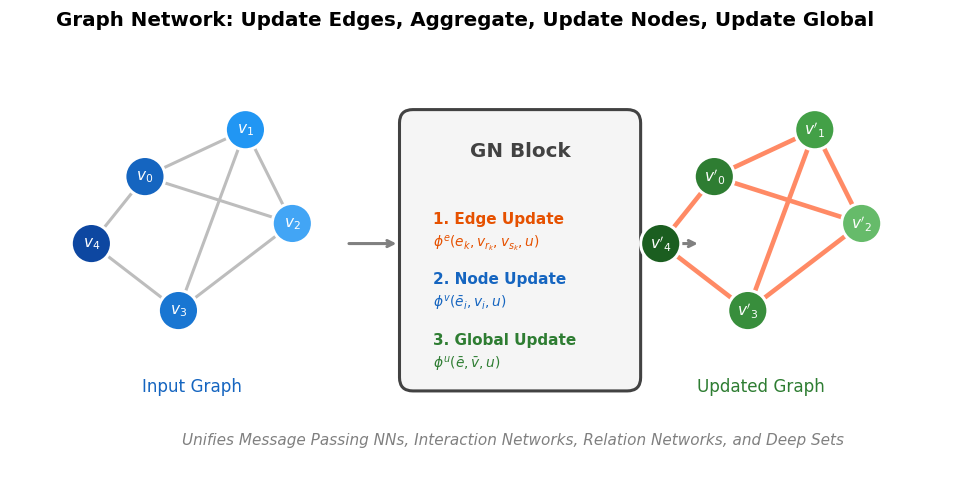
Relational Inductive Biases in Deep Learning (2018)
Battaglia et al. argue that combinatorial generalization requires structured representations, systematically analyze the relational inductive biases in standard deep learning architectures (MLPs, CNNs, RNNs), and present the graph network as a unifying framework that generalizes and extends prior graph neural network approaches.
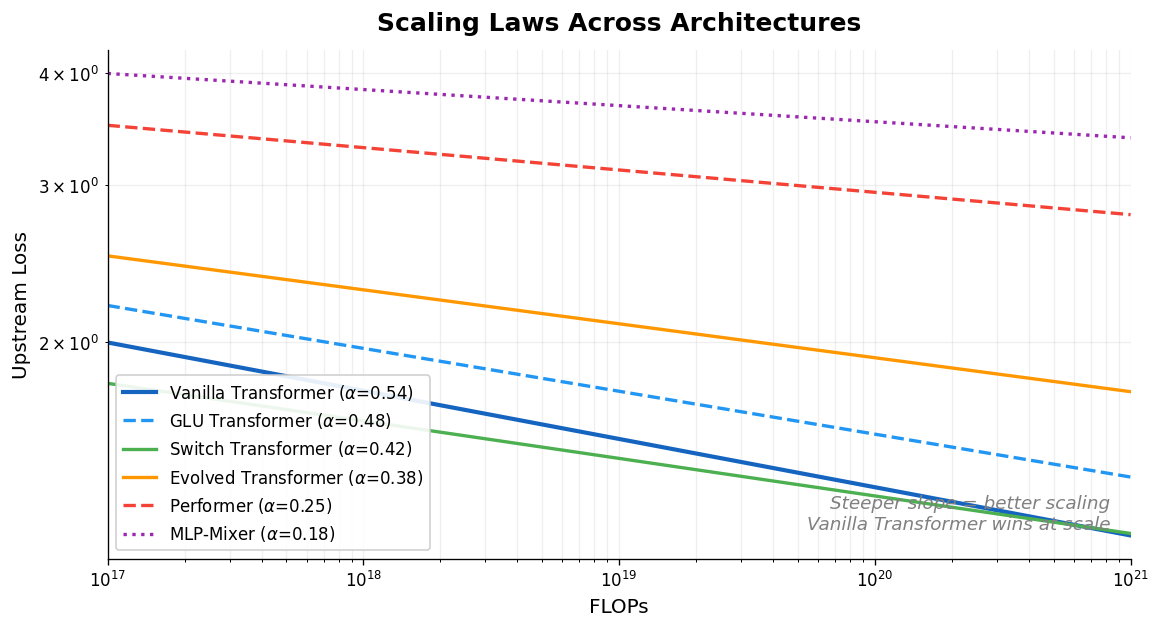
Scaling Laws vs Model Architectures: Inductive Bias
Tay et al. systematically compare scaling laws across ten diverse architectures (Transformers, Switch Transformers, Performers, MLP-Mixers, and others), finding that the vanilla Transformer has the best scaling coefficient and that the best-performing architecture changes across compute regions.
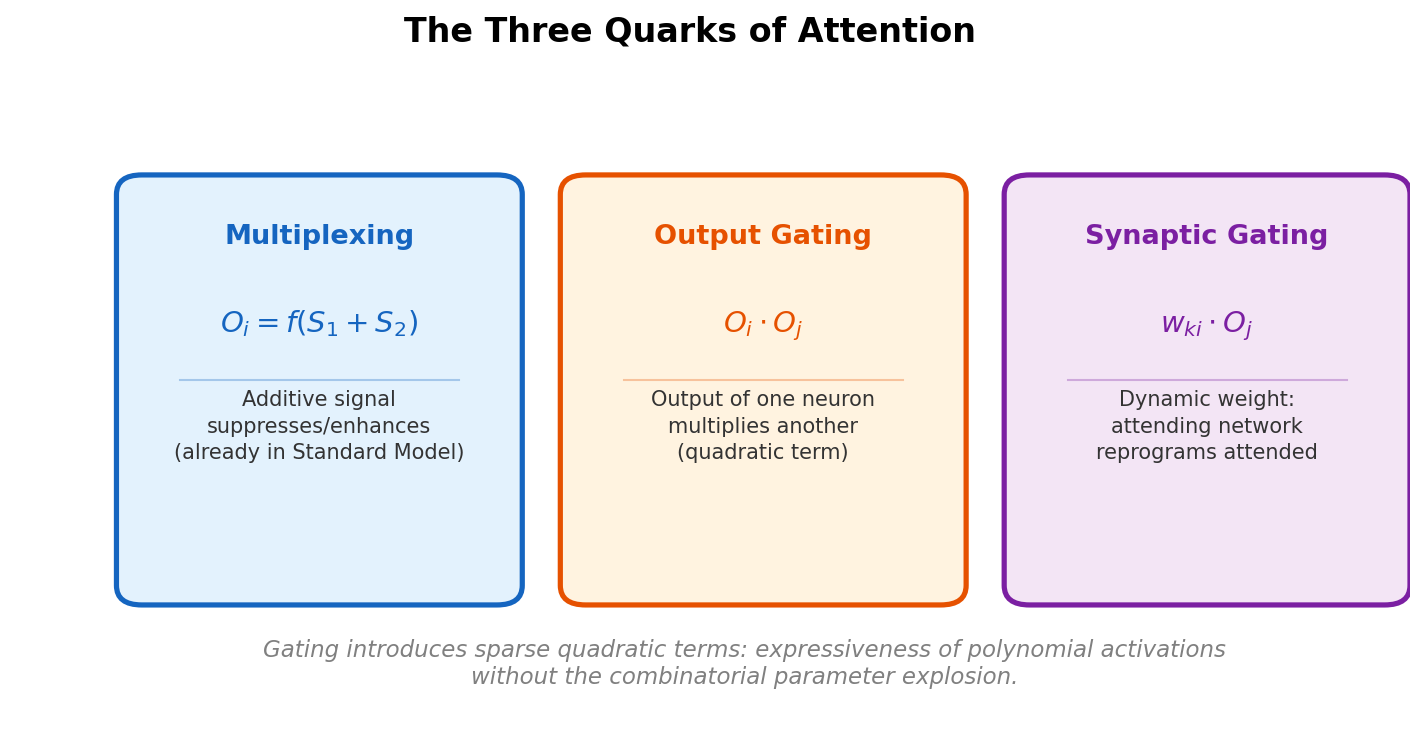
The Quarks of Attention: Building Blocks of Attention
Baldi and Vershynin systematically classify the fundamental building blocks of attention (activation attention, output gating, synaptic gating) by source, target, and mechanism, then prove capacity bounds showing that gating introduces quadratic terms sparsely, gaining expressiveness without the full cost of polynomial activations.