A Theory Paper Grounding Disentanglement in Symmetry
This is a Theory paper that provides the first formal mathematical definition of disentangled representations. Rather than proposing a new learning algorithm or evaluating existing methods, the paper uses group theory and representation theory to define precisely what it means for a representation to be disentangled. The authors argue that the relevant structure of the world is captured by symmetry transformations, and that a disentangled representation must decompose into independent subspaces aligned with the decomposition of the corresponding symmetry group.
Why Disentangling Lacks a Formal Foundation
Disentangled representation learning aims to learn representations where distinct factors of variation in the data are separated into independent components. This idea has driven significant research, particularly through models like $\beta$-VAE and InfoGAN. Despite this progress, the field has lacked agreement on several fundamental questions: what constitutes the “data generative factors,” whether each factor should correspond to a single latent dimension or multiple dimensions, and whether a disentangled representation should have a unique axis alignment.
Without a formal definition, evaluating disentanglement methods remains subjective, relying on human intuition or metrics that encode different (sometimes contradictory) assumptions. For example, some metrics penalize multi-dimensional subspaces while others allow them. The lack of formal grounding also means there is no principled way to determine whether certain factors of variation (such as 3D rotations) can even be disentangled in principle.
The authors draw inspiration from physics, where symmetry transformations have been central to understanding world structure since Noether’s theorem connected conservation laws to continuous symmetries. Gell-Mann’s prediction of the $\Omega^{-}$ particle from symmetry-based classification of hadrons, and the unification of electricity and magnetism through shared symmetry transformations, illustrate the power of the symmetry perspective for generalization to new domains.
Symmetry Groups as the Foundation for Disentanglement
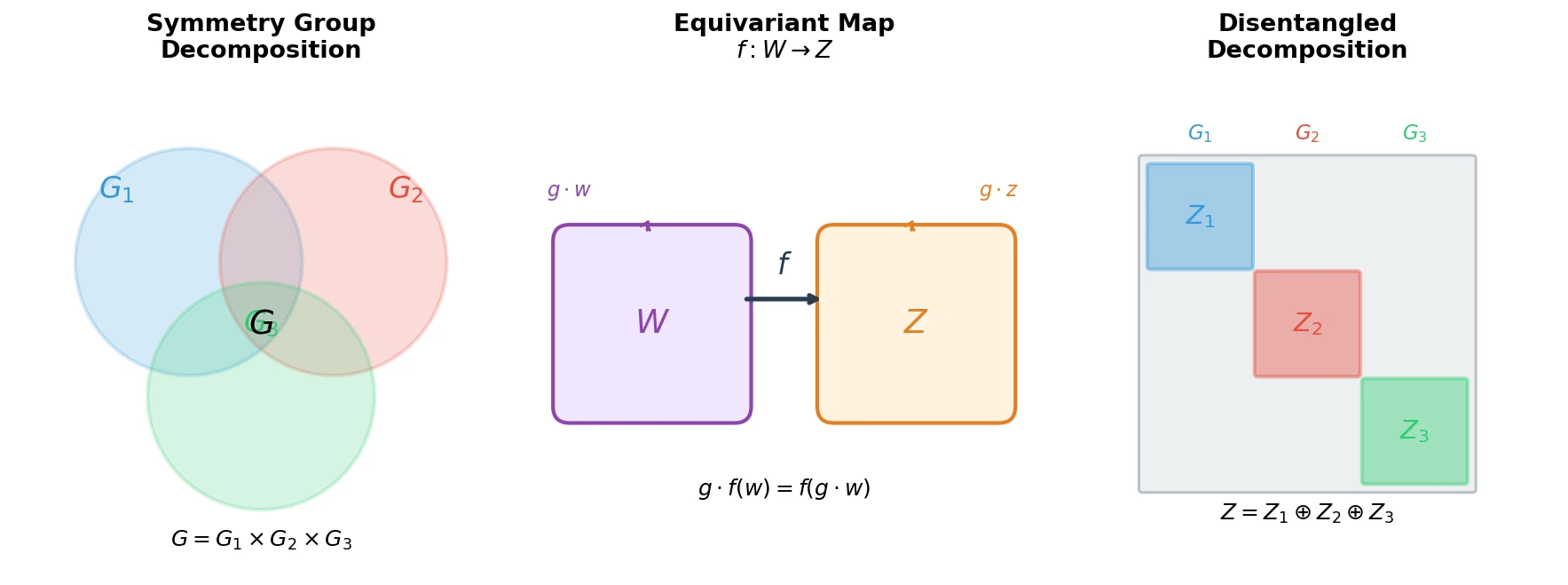
The core insight is that the “data generative factors” previously used to discuss disentanglement should be replaced by symmetry transformations of the world. The paper defines a disentangled representation through three key concepts.
Disentangled Group Action
Given a group $G$ that decomposes as a direct product $G = G_1 \times G_2 \times \ldots \times G_n$, an action of $G$ on a set $X$ is disentangled if there exists a decomposition $X = X_1 \times X_2 \times \ldots \times X_n$ such that each subgroup $G_i$ acts only on $X_i$ and leaves all other components fixed:
$$(g_1, g_2) \cdot (v_1, v_2) = (g_1 \cdot_1 v_1, g_2 \cdot_2 v_2)$$
Disentangled Representation
Let $W$ be the set of world states with symmetry group $G$ acting on it. A generative process $b: W \to O$ produces observations, and an inference process $h: O \to Z$ produces representations. The composition $f = h \circ b$ maps world states to representations. The representation is disentangled if:
- There exists an action $\cdot: G \times Z \to Z$
- The map $f: W \to Z$ is equivariant: $g \cdot f(w) = f(g \cdot w)$ for all $g \in G, w \in W$
- There exists a decomposition $Z = Z_1 \oplus Z_2 \oplus \ldots \oplus Z_n$ such that each $Z_i$ is affected only by $G_i$ and fixed by all other subgroups
The equivariance condition ensures that the symmetry structure of the world is faithfully reflected in the representation space.
Linear Disentangled Representation
When the group action on $Z$ is additionally constrained to be linear, the representation becomes a linear disentangled representation. This leverages group representation theory, where the action is described by a homomorphism $\rho: G \to GL(Z)$. The representation is linearly disentangled if it decomposes as a direct sum $\rho = \rho_1 \oplus \rho_2 \oplus \ldots \oplus \rho_n$, where each $\rho_i$ acts only on $Z_i$. In matrix terms, this means $\rho(g)$ takes a block-diagonal form.
For the irreducible representations of a direct product group $G = G_1 \times G_2$, disentanglement requires that each irreducible component $\rho_1 \otimes \rho_2$ has at most one non-trivial factor. This prevents any subspace from being jointly affected by multiple subgroups.
Grid World Example and the SO(3) Counterexample
Since this is a theory paper, the “experiments” consist of worked examples that illustrate the definition.
Grid World Verification
The authors consider a grid world where an object can translate horizontally, vertically, and change color, with wraparound boundaries. The symmetry group decomposes as $G = G_x \times G_y \times G_c$, where each subgroup is isomorphic to the cyclic group $C_N$.
A CCI-VAE model trained on observations from this world learns a representation that approximately satisfies the equivariance condition $f(x, y, c) \approx (\lambda_x x, \lambda_y y, \lambda_c c)$, where each subgroup acts independently on its corresponding subspace. The group structure (commutativity of actions) is approximately preserved, though the learned representation uses translation rather than linear action, and the cyclic structure is lost.
For a linear disentangled representation, the map $f(x, y, c) = (e^{2\pi i x / N}, e^{2\pi i y / N}, e^{2\pi i c / N})$ over $\mathbb{C}^3$ provides an exact solution. The generator of each subgroup acts as multiplication by $e^{2\pi i / N}$ on its corresponding coordinate, yielding a truly linear and disentangled action. Equivalently, viewing $\rho$ as a representation over $\mathbb{R}^6$ (since $\mathbb{C}^3 \cong \mathbb{R}^6$), the group action is expressed using block-diagonal matrices of $2 \times 2$ rotation matrices, and each invariant subspace becomes two-dimensional.
3D Rotations Cannot Be Disentangled
The group of 3D rotations $SO(3)$ has subgroups for rotations about the $x$, $y$, and $z$ axes. Intuitively, one might expect to disentangle these three rotation axes. However, rotations about different axes do not commute (rotating $90°$ about $x$ then $y$ gives a different result from $y$ then $x$), so $SO(3)$ cannot be written as a direct product of these subgroups. The definition correctly rules out disentangling along these lines.
Rotations can still be disentangled from other independent symmetries. For an object that can rotate and change color, the relevant group $G = SO(3) \times G_c$ is a valid direct product, so rotation and color form two disentangled subspaces (even though the rotation subspace is itself multi-dimensional and internally entangled).
Resolving Disagreements and Defining the Path Forward
Backward Compatibility with Existing Intuitions
The paper evaluates its definition against three established dimensions of disentanglement:
Modularity (each latent dimension encodes at most one factor): Satisfied by the new definition, with “data generative factors” replaced by “disentangled actions of the symmetry group.” The $SO(3)$ case shows where the new definition disagrees with naive intuition, correctly identifying that non-commuting factors cannot be disentangled.
Compactness (each factor encoded by a single dimension): The new definition allows multi-dimensional subspaces, siding with approaches that permit distributed representations of individual factors. The dimensionality of each subspace is determined by the structure of the corresponding group representation.
Explicitness (factors linearly decodable): The general definition does not require linearity. Linear disentangled representations are a strictly stronger condition, and the paper provides a separate formal definition for this case.
Key Consequences
The definition is relative to a particular decomposition of the symmetry group into subgroups. This has two implications. First, the same group may admit multiple decompositions, and different decompositions yield different disentangled representations (potentially useful for different downstream tasks). Second, identifying the “natural” decomposition is a separate problem that the authors leave to future work, suggesting that active perception and causal interventions may play a role.
The paper connects to Locatello et al. (2018), who proved that unsupervised learning of disentangled representations is impossible without inductive biases. The symmetry-based framework suggests that such biases could come from an agent’s ability to interact with the world and discover which aspects remain invariant under various transformations.
Limitations
The paper explicitly focuses on defining disentanglement rather than solving the learning problem. It assumes that the symmetry group decomposes as a direct product of subgroups and that a useful decomposition is known. The authors acknowledge that relaxing these assumptions (e.g., discovering useful decompositions automatically) is important future work. The worked examples use toy environments, and bridging the gap to realistic data remains an open challenge.
Reproducibility Details
Data
This is a purely theoretical paper. The only empirical element is a qualitative demonstration using a CCI-VAE model on a grid world environment, where an object translates on a grid with wraparound and changes color through discrete steps on a circular hue axis.
Algorithms
No new algorithms are proposed. The CCI-VAE model from Burgess et al. (2018) is used for the grid world demonstration. The paper’s contribution is a set of formal definitions, not an algorithmic procedure.
Evaluation
No quantitative evaluation is performed. The paper discusses how existing disentanglement metrics relate to the proposed definition, noting that they each capture different subsets of the three dimensions (modularity, compactness, explicitness) and that the formal definition provides a principled way to evaluate their relative merits.
Reproducibility Status: Closed
This is a theory paper whose primary contribution is a set of formal definitions. The theoretical content (definitions, proofs, worked examples) is self-contained in the paper. No code, data, or models are released. The CCI-VAE demonstration uses a model from Burgess et al. (2018), but no implementation or training details specific to the grid world experiment are provided.
Paper Information
Citation: Higgins, I., Amos, D., Pfau, D., Racanière, S., Matthey, L., Rezende, D., & Lerchner, A. (2018). Towards a Definition of Disentangled Representations. arXiv preprint arXiv:1812.02230.
@misc{higgins2018towards,
title={Towards a Definition of Disentangled Representations},
author={Higgins, Irina and Amos, David and Pfau, David and Racani\`{e}re, S\'{e}bastien and Matthey, Lo\"{i}c and Rezende, Danilo and Lerchner, Alexander},
year={2018},
eprint={1812.02230},
archiveprefix={arXiv},
primaryclass={cs.LG}
}