What kind of paper is this?
This is primarily a Method paper. It proposes a unified framework that generalizes previous discrete score-based models (SMLD and DDPM) into continuous-time Stochastic Differential Equations (SDEs). The paper introduces algorithms for sampling (Predictor-Corrector) and likelihood computation (Probability Flow ODE), validated by setting new records on CIFAR-10 (FID 2.20, IS 9.89 at the time of publication). It also contains elements of Systematization by showing how existing methods are special cases of this broader framework.
What is the motivation?
Prior successful generative models, specifically Score Matching with Langevin Dynamics (SMLD) and Denoising Diffusion Probabilistic Models (DDPM), operate by sequentially corrupting data with slowly increasing noise and learning to reverse the process. Both methods treat the noise scales as a finite set of discrete steps. The authors aim to generalize this to a continuum of noise scales by modeling the diffusion process as a Stochastic Differential Equation (SDE). This continuous formulation enables:
- Flexible sampling: Use of general-purpose SDE solvers.
- Exact likelihood computation: Via connection to Neural ODEs.
- Controllable generation: Solving inverse problems (inpainting, colorization) without retraining.
What is the novelty here?
The core novelty is the SDE framework for score-based generative modeling:
- Continuous Generalization: Proving that SMLD and DDPM noise perturbations correspond to discretizations of Variance Exploding (VE) SDEs and Variance Preserving (VP) SDEs, respectively.
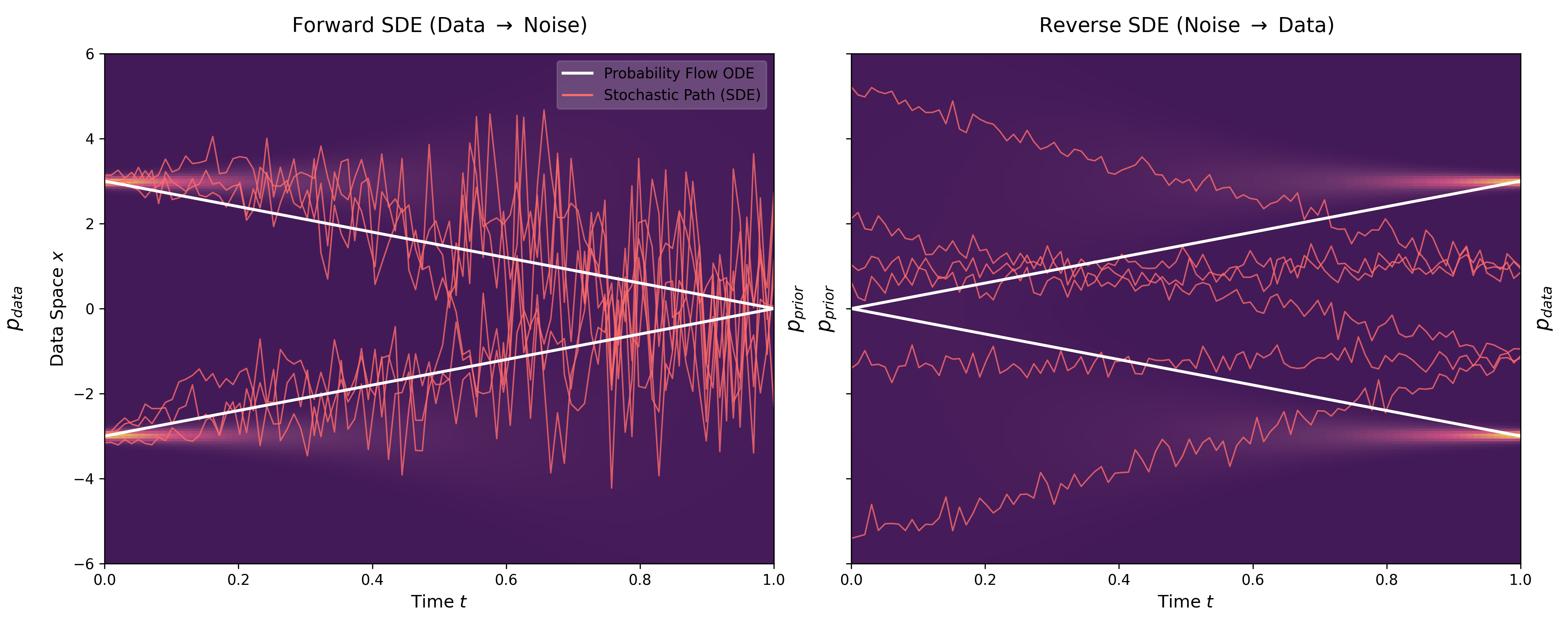
- Reverse-Time SDE: Leveraging Anderson’s result (Anderson, 1982: a result on time-reversal of diffusion processes showing that the reverse is also a diffusion, with the forward drift reversed and a correction term involving the score of the marginal density) that the reverse of a diffusion process is also a diffusion process, governed by the score (gradient of log density).
- Predictor-Corrector (PC) Samplers: A hybrid sampling strategy where a numerical SDE solver (Predictor) estimates the next step, and a score-based MCMC approach (Corrector) corrects the marginal distribution.
- Probability Flow ODE: Deriving a deterministic ODE that shares the same marginal densities as the SDE, enabling near-exact likelihood computation (accuracy is limited by both numerical ODE solver discretization and variance of the unbiased Hutchinson trace estimator) and latent space manipulation.
- Sub-VP SDE: A new SDE class proposed to improve likelihoods by bounding variance tighter than the VP SDE.
What experiments were performed?
The authors validated the framework on standard image benchmarks:
- Datasets: CIFAR-10 (32x32), CelebA (64x64), LSUN (Bedroom, Church), and CelebA-HQ (256x256 and 1024x1024).
- Ablation Studies: Comparing samplers (Ancestral vs. Reverse Diffusion vs. Probability Flow vs. PC) and SDE types (VE, VP, sub-VP).
- Architecture Search: Exploring improvements like FIR up/downsampling, rescaling skip connections, and increasing depth (leading to NCSN++ and DDPM++ architectures).
- Likelihood Evaluation: Computing Negative Log-Likelihood (NLL) in bits/dim using the Probability Flow ODE.
- Inverse Problems: Testing class-conditional generation, inpainting, and colorization using the conditional reverse-time SDE.
What outcomes/conclusions?
- Record Performance: The NCSN++ cont. (deep, VE) model achieved an Inception Score of 9.89 and FID of 2.20 on CIFAR-10 (as of ICLR 2021).
- High-Fidelity Generation: First score-based model to generate 1024x1024 images (CelebA-HQ).
- Competitive Likelihoods: The DDPM++ cont. (deep, sub-VP) model achieved 2.99 bits/dim on uniformly dequantized CIFAR-10, a record at the time.
- Sampling Efficiency: PC samplers consistently outperformed predictor-only methods (like standard ancestral sampling) for the same computational cost.
- Controllable Generation: Successful application to inpainting and colorization using a single unconditional model.
- Limitations: Sampling remains slower than GANs on the same datasets. The breadth of available samplers introduces many hyperparameters (SDE type, predictor, corrector, signal-to-noise ratio, number of steps) that require tuning.
Reproducibility Details
Data
- CIFAR-10: Used for main benchmarking (FID, Inception Score, NLL).
- CelebA-HQ: Used for high-resolution experiments at 256x256 and 1024x1024.
- LSUN: Bedroom and Church Outdoor categories (256x256) used for sampler comparison and controllable generation (inpainting, colorization).
- Preprocessing: CIFAR-10 images are 32x32; CelebA pre-processed to 64x64 following Song & Ermon (2020). Data is typically scaled to $[0, 1]$ or standardized depending on the specific SDE config.
Algorithms
Forward SDEs:
Here $dw$ denotes a Wiener process increment (a small, independent Gaussian noise burst at each timestep).
- VE SDE (Variance Exploding): $dx = \sqrt{\frac{d[\sigma^2(t)]}{dt}} dw$. Corresponds to SMLD. Used with $\sigma_{\min}=0.01$ and $\sigma_{\max}$ chosen via heuristics.
- VP SDE (Variance Preserving): $dx = -\frac{1}{2}\beta(t)x dt + \sqrt{\beta(t)} dw$. Corresponds to DDPM.
- Sub-VP SDE: $dx = -\frac{1}{2}\beta(t)x dt + \sqrt{\beta(t)(1 - e^{-2\int_0^t \beta(s)ds})} dw$. Bounded variance, good for likelihoods.
Reverse-Time SDE Solver (Predictor):
- Discretized via Reverse Diffusion Sampling, which matches the forward discretization.
- Euler-Maruyama solver used for continuously-trained models.
Corrector Algorithm:
- Langevin MCMC: Applies annealed Langevin dynamics: adds noise and takes a score-guided gradient step to correct the marginal distribution at each timestep.
- PC Sampling: Alternates between one step of the Predictor and one step of the Corrector.
- Signal-to-Noise Ratio ($r$): A hyperparameter for the corrector step size. Tuned values: $r \approx 0.16$ for VE SDEs on CIFAR-10.
Models
- NCSN++: Optimized architecture for VE SDEs. Key features:
- 4 residual blocks per resolution.
- BigGAN-type residual blocks.
- Rescaling skip connections by $1/\sqrt{2}$.
- FIR (Finite Impulse Response) up/downsampling.
- “Residual” progressive architecture for input, no progressive growing for output.
- DDPM++: Optimized architecture for VP/sub-VP SDEs. Similar to NCSN++ but without FIR upsampling and no progressive growing.
- Deep Variants: “cont. (deep)” models double the depth (from 4 to 8 blocks per resolution) for the best reported results.
- Conditioning: Time $t$ is conditioned via random Fourier feature embeddings (scale 16) for continuous models.
Evaluation
Metrics:
- FID (Fréchet Inception Distance): Computed on 50k samples.
- Inception Score: Reported for CIFAR-10.
- NLL (Negative Log-Likelihood): Reported in bits/dim on uniformly dequantized data using the Probability Flow ODE.
Denoising: A single denoising step using Tweedie’s formula is applied at the end of sampling to remove residual noise, which significantly improves FID.
Hardware
Training:
- Batch size: 128 for CIFAR-10, 64 for LSUN, 8 for high-res CelebA-HQ.
- Iterations: Discrete-objective models trained for 1.3M iterations during architecture exploration. Continuous-objective models (cont.) trained for 0.95M iterations. High-res CelebA-HQ (1024x1024) trained for approximately 2.4M iterations.
- EMA: Exponential Moving Average rate of 0.999 used for VE models, 0.9999 for VP models.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| yang-song/score_sde | Code | Apache-2.0 | Official JAX and PyTorch implementation with pretrained checkpoints |
All datasets used (CIFAR-10, CelebA-HQ, LSUN) are publicly available. Pretrained model checkpoints for CIFAR-10, CelebA-HQ, and FFHQ are provided in the repository. Specific hardware requirements (GPU type, training time) are not detailed in the paper.
Paper Information
Citation: Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., & Poole, B. (2021). Score-Based Generative Modeling through Stochastic Differential Equations. ICLR 2021. https://arxiv.org/abs/2011.13456
Publication: ICLR 2021
@inproceedings{song2021scorebased,
title = {Score-Based Generative Modeling through Stochastic Differential Equations},
author = {Song, Yang and Sohl-Dickstein, Jascha and Kingma, Diederik P and Kumar, Abhishek and Ermon, Stefano and Poole, Ben},
booktitle = {International Conference on Learning Representations},
year = {2021},
url = {https://openreview.net/forum?id=PxTIG12RRHS}
}
Additional Resources: