What kind of paper is this?
This is primarily a Method paper, with a significant Theory component.
- Method: It proposes “Rectified Flow,” a novel generative framework that learns ordinary differential equations (ODEs) to transport distributions via straight paths. It introduces the “Reflow” algorithm to iteratively straighten these paths.
- Theory: It provides rigorous proofs connecting the method to Optimal Transport, showing that the rectification process yields a coupling with non-increasing convex transport costs and that recursive reflow reduces the curvature of trajectories.
What is the motivation?
The work addresses two main challenges in unsupervised learning: generative modeling (generating data from noise) and domain transfer (mapping between two observed distributions).
- Inefficiency of ODE/SDE Models: Continuous-time models (like Score-based Generative Models and DDPMs) require simulating diffusions over many steps, resulting in high computational costs during inference.
- Complexity of GANs: GANs provide fast (one-step) generation alongside challenges with training instability and mode collapse.
- Disconnection: Generative modeling and domain transfer are often treated as separate tasks requiring different techniques.
The authors aim to unify these tasks into a single “transport mapping” problem while bridging the gap between high-quality continuous models and fast one-step models.
What is the novelty here?
The core novelty is the Rectified Flow framework and the Reflow procedure.
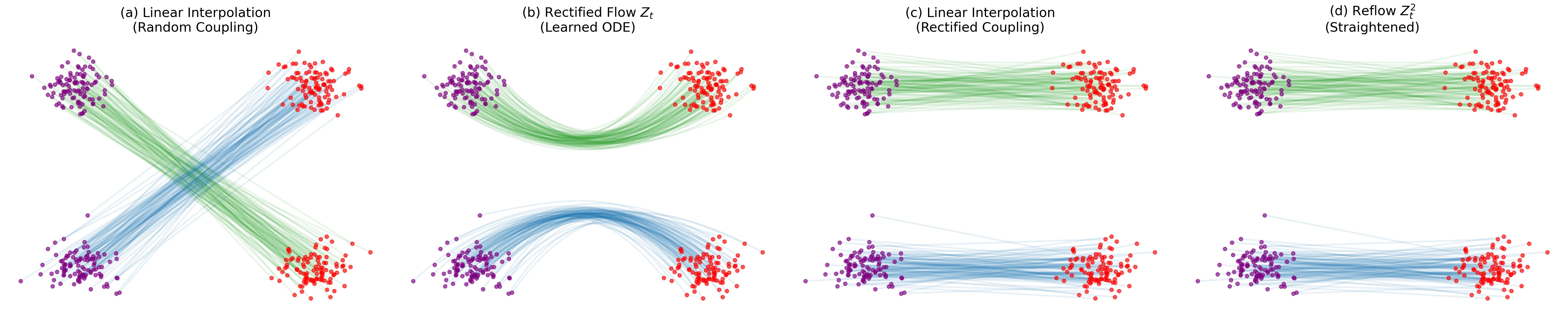
- Straight-Line ODEs: Rectified Flow learns an ODE drift $v$ to follow the straight line connecting data pairs $(X_0, X_1)$, providing an alternative to diffusion models that rely on stochastic paths or specific forward processes. This is achieved via a simple least-squares optimization problem.
- Reflow (Iterative Straightening): The authors introduce a recursive training procedure where a new flow is trained on the data pairs $(Z_0, Z_1)$ generated by the previous flow. Theoretical analysis shows this reduces the “transport cost” and straightens the trajectories, allowing for accurate 1-step simulation (effectively converting the ODE into a one-step model).
- Unified Framework: The method uses the exact same algorithm for generation ($\pi_0$ is Gaussian) and domain transfer ($\pi_0$ is a source dataset), removing the need for adversarial losses or cycle-consistency constraints.
What experiments were performed?
The authors validated the method across image generation, translation, and domain adaptation tasks.
- Unconditioned Image Generation:
- Dataset: CIFAR-10 ($32\times32$).
- Baselines: Compared against GANs (StyleGAN2, TDPM), Diffusion/SDE Models (VP SDE, sub-VP SDE, VE SDE), ODE methods (VP ODE, sub-VP ODE, VE ODE), and distilled methods (DDIM Distillation).
- High-Res: Validated on LSUN Bedroom/Church, CelebA-HQ, and AFHQ ($256\times256$).
- Image-to-Image Translation:
- Datasets: AFHQ (Cat $\leftrightarrow$ Dog/Wild), MetFace $\leftrightarrow$ CelebA-HQ.
- Setup: Transferring styles while preserving semantic identity (using a classifier-based feature mapping metric).
- Domain Adaptation:
- Datasets: DomainNet, Office-Home.
- Metric: Classification accuracy on the transferred testing data.
What outcomes/conclusions?
- Superior 1-Step Generation: On CIFAR-10 with a single Euler step (as of ICLR 2023), the distilled 2-Rectified Flow achieved an FID of 4.85, beating the best one-step U-Net model TDPM (FID 8.91, a truncated diffusion model using a GAN). The distilled 3-Rectified Flow reached a Recall of 0.51, beating the GAN baseline StyleGAN2+ADA (Recall 0.49).
- Straightening Effect: The “Reflow” procedure was empirically shown to reduce the “straightness” error and transport costs, validating the theoretical claims. “Straightness” is measured as $S(Z) = \mathbb{E}[\int_0^1 |\dot{Z}_t - (Z_1 - Z_0)|^2, dt]$ (zero means perfectly straight); “transport cost” is $\mathbb{E}[c(Z_1 - Z_0)]$ for a convex cost $c$, and Reflow reduces this for all convex costs.
- High-Quality Transfer: The model successfully performed image translation (e.g., Cat to Wild Animal) without paired data or cycle-consistency losses.
- Strong Full-Simulation Results: With RK45 adaptive ODE solving, 1-Rectified Flow achieves FID 2.58 and Recall 0.57 on CIFAR-10 (Table 1a), the best among ODE methods and comparable to fully simulated SDEs (VP SDE: FID 2.55).
- Fast Simulation: The method allows for extremely coarse time discretization (e.g., $N=1$) without significant quality loss after reflow, effectively solving the slow inference speed of standard ODE models.
- Domain Adaptation: On Office-Home, Rectified Flow achieves 69.2% accuracy, outperforming Deep CORAL (68.7%) and other baselines. On DomainNet, it achieves 41.4%, comparable to Deep CORAL (41.5%) and MLDG (41.2%).
Reproducibility Details
Data
The paper utilizes several standard computer vision benchmarks.
| Purpose | Dataset | Size/Resolution | Notes |
|---|---|---|---|
| Generation | CIFAR-10 | 32x32 | Standard split |
| Generation | LSUN (Bedroom, Church) | 256x256 | High-res evaluation |
| Generation | CelebA-HQ | 256x256 | High-res evaluation |
| Gen/Transfer | AFHQ (Cat, Dog, Wild) | 512x512 | 256x256 for generation, 512x512 for transfer |
| Transfer | MetFace | 1024x1024 | Resized to 512x512 for experiments |
| Adaptation | DomainNet | Mixed | 345 categories, 6 domains |
| Adaptation | Office-Home | Mixed | 65 categories, 4 domains |
Algorithms
Objective Function: The drift $v(Z_t, t)$ is trained by minimizing a least-squares regression objective: $$\min_{v} \int_{0}^{1} \mathbb{E}[|(X_1 - X_0) - v(X_t, t)|^2] dt$$ where $X_t = tX_1 + (1-t)X_0$ is the linear interpolation.
Reflow Procedure: Iteratively updates the flow. Let $Z^k$ be the $k$-th rectified flow.
- Generate 4 million data pairs $(Z_0^k, Z_1^k)$ by simulating the current flow.
- Fine-tune the $i$-rectified flow model for 300,000 steps on these pairs to obtain the $(i+1)$-rectified flow.
Distillation: For 1-step distillation ($k=1$), the L2 loss is replaced with LPIPS perceptual similarity, which empirically yields better image quality. For multi-step distillation, training samples $t$ from ${0, 1/k, \ldots, (k-1)/k}$ rather than the full $[0, 1]$ interval.
ODE Solver:
- Training: Analytical linear interpolation.
- Inference: Euler method (constant step size $1/N$) or RK45 (adaptive).
Models
Architecture:
- Uses the DDPM++ U-Net architecture (from Song et al., 2020) across experiments. Implementation is modified from the open-source code of Song et al.
Optimization:
- Optimizer: Adam (CIFAR-10) or AdamW (Transfer/Adaptation).
- Hyperparameters:
- LR: $2 \times 10^{-4}$ (CIFAR), Grid search for transfer.
- EMA: 0.999999 (CIFAR), 0.9999 (Transfer).
- Batch Size: 4 (Transfer), 16 (Domain Adaptation).
- Dropout: 0.15 (CIFAR), 0.1 (Transfer).
Evaluation
| Metric | Value (CIFAR-10, N=1) | Baseline (Best 1-step) | Notes |
|---|---|---|---|
| FID | 4.85 (2-Rectified + Distill) | 8.91 (TDPM) | Lower is better |
| Recall | 0.51 (3-Rectified + Distill) | 0.49 (StyleGAN2+ADA) | Higher is better |
Hardware
The paper does not specify GPU models or training times. The DDPM++ U-Net architecture used in the experiments typically requires multi-GPU setups for training on high-resolution datasets.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| RectifiedFlow (GitHub) | Code | Unknown | Official PyTorch implementation with CIFAR-10 and high-res training code, plus pre-trained checkpoints |
Paper Information
Citation: Liu, X., Gong, C., & Liu, Q. (2023). Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=XVjTT1nw5z
Publication: ICLR 2023
@inproceedings{liuFlowStraightFast2023,
title = {Flow {{Straight}} and {{Fast}}: {{Learning}} to {{Generate}} and {{Transfer Data}} with {{Rectified Flow}}},
booktitle = {International Conference on Learning Representations},
author = {Liu, Xingchao and Gong, Chengyue and Liu, Qiang},
year = 2023,
url = {https://openreview.net/forum?id=XVjTT1nw5z}
}
Additional Resources: