This section covers the core families of generative models used in modern machine learning. Notes begin with the foundational variational autoencoder (VAE) and its extensions (importance-weighted objectives, contrastive priors), then move through continuous normalizing flows, neural ODEs, score-based and diffusion models, and flow matching. The thread connecting these works is the shared goal of learning to sample from complex distributions, and each set of notes tries to make the mathematical connections between approaches explicit rather than treating them as isolated methods.
| Year | Paper | Key Idea |
|---|---|---|
| 1994 | Mixture Density Networks | Neural nets predicting Gaussian mixture parameters for multimodal outputs |
| 1997 | A Convexity Principle for Interacting Gases | Displacement interpolation via optimal transport for energy functionals |
| 2011 | Score Matching and Denoising Autoencoders | Proves denoising autoencoders are equivalent to score matching |
| 2013 | Auto-Encoding Variational Bayes | Reparameterization trick enabling end-to-end VAE training |
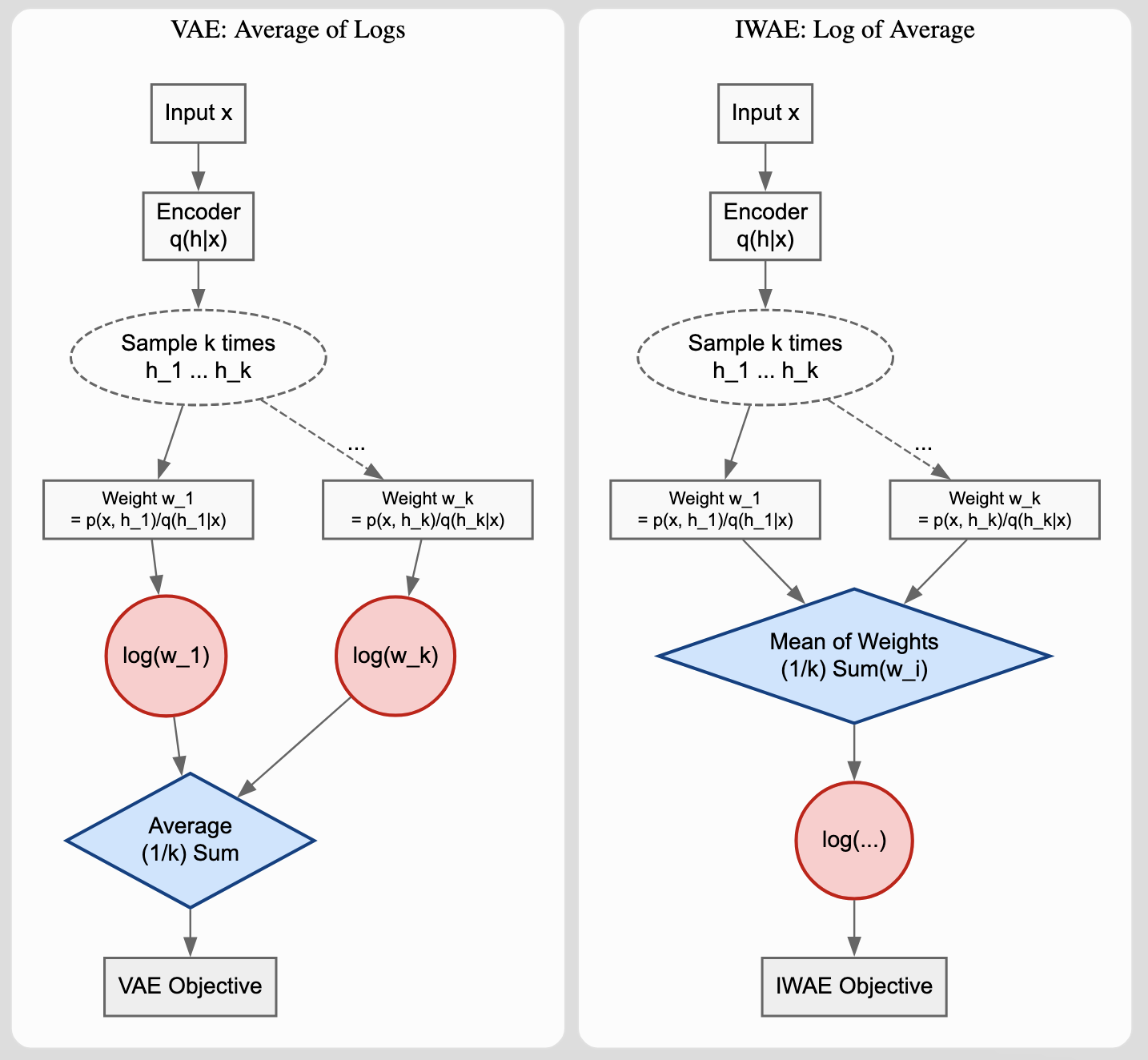
| 2016 | Importance Weighted Autoencoders | Tighter log-likelihood bounds via importance sampling in VAEs |
| 2018 | Neural ODEs | Continuous-depth networks via ODE solvers with constant-memory training |
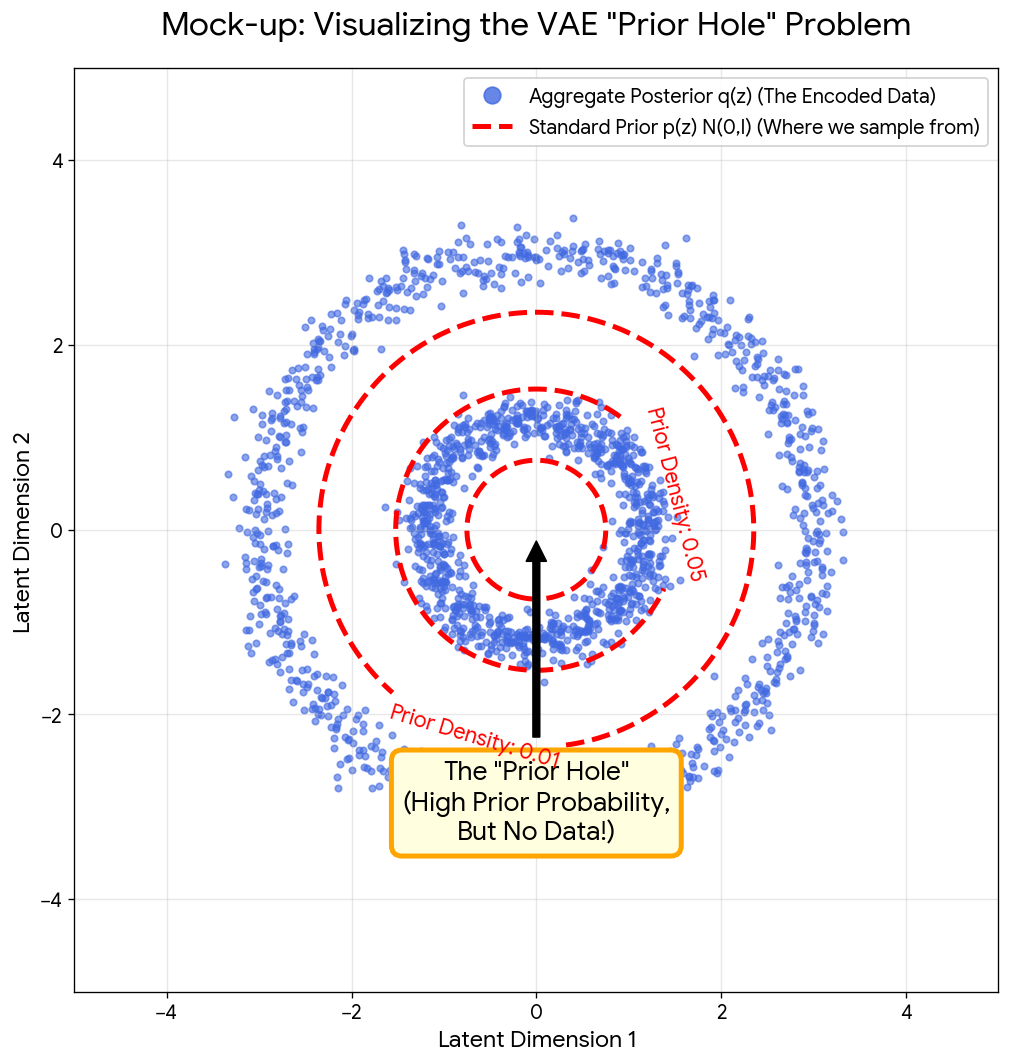
| 2021 | Contrastive Learning for VAE Priors | Noise contrastive priors to fix the VAE “prior hole” problem |
| 2021 | D3PM: Discrete Diffusion Models | Diffusion extended to discrete state-spaces with structured transitions |
| 2021 | Score-Based Generative Modeling with SDEs | Unified SDE framework for score-based models with Predictor-Corrector sampling |
| 2022 | Latent Diffusion Models | Diffusion in compressed latent space for high-res image synthesis |
| 2023 | Consistency Models | One-step generation by mapping ODE trajectory points to their origin |
| 2023 | Flow Matching for Generative Modeling | Simulation-free CNF training with optimal transport paths |
| 2023 | Rectified Flow | ODE-based generation with iterative trajectory straightening (reflow) |
| 2023 | Stochastic Interpolants | CNFs between arbitrary densities via quadratic velocity field objective |