What kind of paper is this?
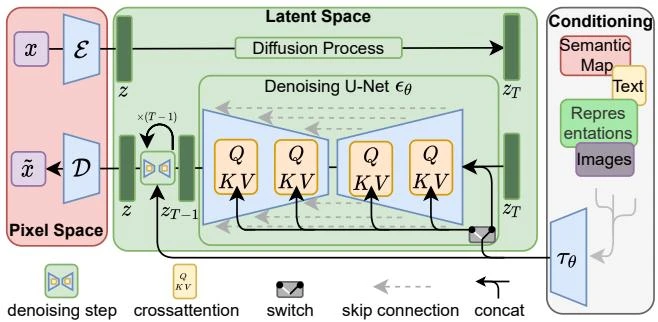
This is a Method paper. It introduces Latent Diffusion Models (LDMs), which train denoising diffusion models in the latent space of pretrained autoencoders rather than directly in pixel space. The key insight is that separating perceptual compression from generative learning enables high-resolution image synthesis at a fraction of the computational cost of pixel-based diffusion. The paper also introduces a cross-attention conditioning mechanism for flexible multi-modal generation.
Computational Cost of Pixel-Space Diffusion
Training diffusion models directly in pixel space is computationally expensive (150 to 1000 V100 GPU-days for leading models at the time) because the model must process high-dimensional RGB data at every denoising step. Much of this compute is spent modeling imperceptible high-frequency details. The authors observe that learning can be split into two stages: a perceptual compression stage that removes high-frequency detail, and a semantic compression stage where the generative model learns the conceptual composition. Prior two-stage approaches (VQGAN, DALL-E) relied on aggressive compression and autoregressive modeling in discrete latent spaces, trading off reconstruction quality for tractability.
Core Innovation: Diffusion in Latent Space
LDMs decompose image synthesis into two phases:
Phase 1: Perceptual Compression. A pretrained autoencoder (encoder $\mathcal{E}$, decoder $\mathcal{D}$) maps images $x \in \mathbb{R}^{H \times W \times 3}$ to a lower-dimensional latent representation $z = \mathcal{E}(x) \in \mathbb{R}^{h \times w \times c}$ with spatial downsampling factor $f = H/h$. The autoencoder is trained with a perceptual loss (matching deep features from a pretrained VGG network) and a patch-based adversarial objective, with either KL or VQ regularization on the latent space.
Phase 2: Latent Diffusion. A standard denoising diffusion model operates in this latent space. The training objective becomes:
$$L_{\text{LDM}} := \mathbb{E}_{\mathcal{E}(x), \epsilon \sim \mathcal{N}(0,1), t} \left[ \left| \epsilon - \epsilon_\theta(z_t, t) \right|_2^2 \right]$$
where $z_t$ is the noised latent at timestep $t$, and $\epsilon_\theta$ is a time-conditional UNet.
Cross-Attention Conditioning. To enable conditioning on text, semantic maps, or other modalities, the authors introduce cross-attention layers into the UNet. A domain-specific encoder $\tau_\theta$ maps conditioning input $y$ to an intermediate representation $\tau_\theta(y) \in \mathbb{R}^{M \times d_\tau}$, which interacts with the UNet features via:
$$Q = W_Q^{(i)} \cdot \varphi_i(z_t), \quad K = W_K^{(i)} \cdot \tau_\theta(y), \quad V = W_V^{(i)} \cdot \tau_\theta(y)$$
The conditional objective then becomes:
$$L_{\text{LDM}} := \mathbb{E}_{\mathcal{E}(x), y, \epsilon \sim \mathcal{N}(0,1), t} \left[ \left| \epsilon - \epsilon_\theta(z_t, t, \tau_\theta(y)) \right|_2^2 \right]$$
Both $\tau_\theta$ and $\epsilon_\theta$ are optimized jointly.
Experimental Setup and Results
The authors evaluate across multiple tasks and datasets:
Perceptual compression tradeoffs. Downsampling factors $f \in {1, 2, 4, 8, 16, 32}$ are compared on ImageNet class-conditional generation. LDM-1 (pixel-based) trains slowly; LDM-32 loses too much information. LDM-4 and LDM-8 achieve the best balance, with LDM-8 outperforming pixel-based diffusion by 38 FID points after 2M training steps on a single A100.
Unconditional image synthesis on CelebA-HQ 256, FFHQ 256, LSUN Churches/Bedrooms 256: LDM-4 achieves FID 5.11 on CelebA-HQ (state of the art at the time), outperforming LSGM, GANs, and other likelihood-based models. On LSUN-Bedrooms, LDM-4 achieves FID 2.95, close to ADM (1.90) with half the parameters and roughly 4x less training compute (see Appendix E.3.5).
Text-to-image synthesis on MS-COCO: A 1.45B parameter LDM-KL-8 model trained on LAION-400M achieves FID 12.63 with classifier-free guidance (a technique that amplifies the conditioning signal at the cost of diversity, by interpolating between conditional and unconditional predictions) at scale s=1.5, on par with GLIDE (FID 12.24, 6B params) and Make-A-Scene (FID 11.84, 4B params) with substantially fewer parameters.
Class-conditional ImageNet 256: LDM-4-G achieves FID 3.60, IS 247.67, outperforming ADM-G (FID 4.59) with fewer parameters and less compute.
Super-resolution: LDM-4 (big) achieves FID 2.4 on ImageNet 64-to-256 upscaling (validation split), outperforming SR3 in FID.
Inpainting on Places: LDM-4 (big, w/ ft) achieves FID 1.50, setting a new state of the art on image inpainting.
Key Findings and Limitations
- LDM-4 and LDM-8 offer the best tradeoff between perceptual compression and generation quality.
- The autoencoder only needs to be trained once and can be reused across different diffusion models and tasks.
- Cross-attention conditioning generalizes to text, semantic layouts, and bounding boxes without architecture changes.
- Convolutional sampling enables generation at resolutions higher than the training resolution (up to 1024x1024).
- Sequential sampling remains slower than GANs. The autoencoder reconstruction can become a bottleneck for tasks requiring pixel-level precision.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Unconditional | CelebA-HQ, FFHQ, LSUN | 256x256 | Standard benchmarks |
| Class-conditional | ImageNet | 256x256 | 1000 classes |
| Text-to-image | LAION-400M | 256x256 | 400M image-text pairs |
| Inpainting | Places | 256x256, 512x512 | Following LaMa protocol |
| Super-resolution | ImageNet | 64 to 256 | Following SR3 pipeline |
Algorithms
- Autoencoder regularization: KL-reg (KL penalty toward standard normal, weighted by ~$10^{-6}$) or VQ-reg (vector quantization layer on the latent space with a learned codebook)
- Diffusion: Standard DDPM denoising with reweighted objective
- Sampling: DDIM sampler with configurable steps (100 to 500 depending on task)
- Guidance: Classifier-free diffusion guidance with scale $s$ (1.5 for class-conditional and text-to-image quantitative evaluation; 10.0 for qualitative text-to-image samples)
Models
- Autoencoder: Based on VQGAN architecture with perceptual + adversarial loss
- UNet backbone: Time-conditional with cross-attention layers at multiple resolutions
- Text encoder: BERT-tokenizer with transformer $\tau_\theta$ for LAION text-to-image model
- LDM-4-G: 400M parameters, $f=4$ downsampling
- LDM-KL-8 (text): 1.45B parameters, $f=8$ downsampling, KL-regularized
Evaluation
| Metric | Task | Best Value | Notes |
|---|---|---|---|
| FID | CelebA-HQ unconditional | 5.11 | 500 DDIM steps |
| FID | ImageNet class-conditional | 3.60 | LDM-4-G, cfg s=1.5 |
| FID | MS-COCO text-to-image | 12.63 | LDM-KL-8-G, 250 steps, cfg s=1.5 |
| FID | Places inpainting | 1.50 | LDM-4 big, w/ ft |
| FID | ImageNet 4x super-resolution | 2.4 | LDM-4 big, 100 steps |
Hardware
- Perceptual compression tradeoff experiments: single NVIDIA A100
- Inpainting model trained on eight V100
- Training at least 2.7x faster than pixel-based diffusion at equal parameters
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| CompVis/latent-diffusion | Code | MIT | Official implementation with pretrained models |
Paper Information
Citation: Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022. https://arxiv.org/abs/2112.10752
Publication: CVPR 2022
@inproceedings{rombach2022highresolution,
title = {High-Resolution Image Synthesis with Latent Diffusion Models},
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj{\"o}rn},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages = {10684--10695},
year = {2022}
}
Additional Resources: