What kind of paper is this?
This is a Method paper. It extends denoising diffusion probabilistic models (DDPMs) from continuous to discrete state-spaces by introducing structured Markov transition matrices for the corruption process. The paper unifies several corruption strategies, draws a formal connection between absorbing-state diffusion and masked language models, and demonstrates competitive results on both image and text generation.
Diffusion Beyond Continuous Spaces
Standard DDPMs operate in continuous state-spaces (e.g., pixel values treated as real numbers) and use Gaussian noise for corruption. Many important data types are inherently discrete: text (tokens from a vocabulary), quantized images (discrete pixel values), molecular structures, and segmentation maps. Prior work by Hoogeboom et al. extended binary diffusion to multinomial diffusion with uniform transition probabilities, but this limits the structure of the corruption process. D3PMs generalize this by allowing arbitrary transition matrices that encode domain-specific inductive biases.
Core Innovation: Structured Transition Matrices
D3PMs define a forward corruption process over discrete variables $\mathbf{x} \in {1, \ldots, K}^D$ using transition matrices $\mathbf{Q}_t \in \mathbb{R}^{K \times K}$:
$$q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \text{Cat}(\mathbf{x}_t; \mathbf{p} = \mathbf{x}_{t-1} \mathbf{Q}_t)$$
where $\mathbf{x}_{t-1}$ is a one-hot row vector. The cumulative transition after $t$ steps is $\overline{\mathbf{Q}}_t = \mathbf{Q}_1 \mathbf{Q}_2 \cdots \mathbf{Q}_t$, giving:
$$q(\mathbf{x}_t | \mathbf{x}_0) = \text{Cat}(\mathbf{x}_t; \mathbf{p} = \mathbf{x}_0 \overline{\mathbf{Q}}_t)$$
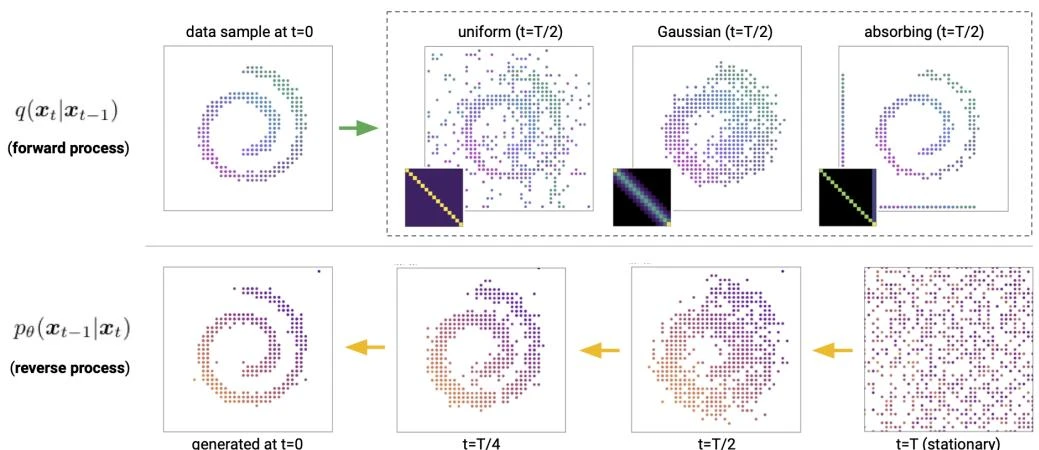
The paper explores several transition matrix designs:
Uniform diffusion: $[\mathbf{Q}_t]_{ij} = (1 - \beta_t) \mathbf{1}_{i=j} + \beta_t / K$. Transitions with equal probability to any state. Stationary distribution is uniform.
Absorbing state: In absorbing-state diffusion, each non-mask token transitions to the mask state with probability $\beta_t$ per step, while tokens already at the mask state remain there:
$[\mathbf{Q}_t]_{ij} = (1-\beta_t)\mathbf{1}_{i=j\neq m} + \beta_t \mathbf{1}_{j=m} + \mathbf{1}_{i=j=m}$. Each token transitions to a designated absorbing state $m$ (e.g., [MASK] for text, gray pixel for images) with probability $\beta_t$. This establishes a direct connection to masked language models like BERT.
Discretized Gaussian: Transition probabilities decay as a function of the distance $|i-j|$ between states, mimicking Gaussian diffusion on ordinal data like pixel values.
Embedding-based nearest neighbor: For text, transitions are weighted by proximity in a pretrained word embedding space, so corruption preferentially swaps words with semantically similar ones.
Training objective. The reverse process $p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t)$ is parameterized by predicting $\tilde{p}_\theta(\tilde{\mathbf{x}}_0 | \mathbf{x}_t)$ and computing the posterior:
$$p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t) \propto \sum_{\tilde{\mathbf{x}}_0} q(\mathbf{x}_{t-1} | \mathbf{x}_t, \tilde{\mathbf{x}}_0) , \tilde{p}_\theta(\tilde{\mathbf{x}}_0 | \mathbf{x}_t)$$
The loss combines the variational lower bound (VLB) with an auxiliary cross-entropy loss $L_\lambda$:
$$L = L_{\text{VLB}} + \lambda , L_{\text{CE}}$$
where $L_{\text{CE}}$ is a reweighted cross-entropy loss on the $\mathbf{x}_0$ prediction that stabilizes training and improves sample quality. The VLB decomposes into per-timestep KL divergences between the true and predicted reverse transitions.
Experiments and Results
Image generation (CIFAR-10):
| Model | Loss | IS | FID | NLL (bpd) |
|---|---|---|---|---|
| D3PM uniform | $L_{\text{VLB}}$ | 5.99 | 51.27 | 5.08 |
| D3PM absorbing | $L_\lambda$ ($\lambda{=}0.001$) | 6.78 | 30.97 | 4.40 |
| D3PM Gauss | $L_{\text{VLB}}$ | 7.75 | 15.30 | 3.97 |
| D3PM Gauss | $L_\lambda$ ($\lambda{=}0.001$) | 8.54 | 8.34 | 3.98 |
| D3PM Gauss + logistic | $L_\lambda$ ($\lambda{=}0.001$) | 8.56 | 7.34 | 3.44 |
| DDPM $L_{\text{simple}}$ (continuous) | – | 9.46 | 3.17 | 3.75 |
The best discrete D3PM variant is D3PM Gauss + logistic, which achieves FID 7.34 and NLL 3.44 bpd using the combined $L_\lambda$ loss with a truncated logistic parameterization. The truncated logistic parameterization replaces the standard softmax output with a discretized logistic distribution over pixel values, assigning probability mass to each discrete bin based on a continuous logistic CDF. This provides a smoother output distribution that better captures the ordinal structure of pixel intensities. This variant exceeds the continuous DDPM in log-likelihood (3.44 vs. 3.75 bpd) while approaching its sample quality (FID 7.34 vs. 3.17).
Text generation (text8, character-level, 1000 steps):
| Model | bpc |
|---|---|
| D3PM absorbing ($L_\lambda$) | 1.45 |
| D3PM NN ($L_{\text{VLB}}$) | 1.59 |
| D3PM uniform | 1.61 |
| Discrete Flow (Tran et al.) | 1.23 |
Among the D3PM variants and baselines evaluated, D3PM absorbing achieves the best bpc on text8 apart from Discrete Flow (Tran et al., 2019). On LM1B (sentencepiece vocabulary of 8192 tokens), D3PM absorbing achieves a perplexity of 76.9 at 1000 steps, compared to 137.9 for D3PM uniform and 43.6 for a comparable autoregressive transformer, demonstrating that discrete diffusion scales to large vocabularies.
Ablation findings:
- The auxiliary cross-entropy loss $L_\lambda$ is critical: for D3PM Gauss, it improves FID from 15.30 ($L_{\text{VLB}}$) to 8.34 ($L_\lambda$, $\lambda{=}0.001$). Adding the truncated logistic parameterization further improves FID to 7.34.
- Discretized Gaussian transitions outperform both uniform and absorbing-state transitions on CIFAR-10 across all metrics.
- For text, the absorbing-state (mask) model outperforms uniform and nearest-neighbor models. Nearest-neighbor diffusion provides only marginal improvement over uniform, a surprising negative result.
- The $\mathbf{x}_0$-parameterization ensures the learned reverse distribution has the correct sparsity pattern dictated by the transition matrix $\mathbf{Q}_t$.
Findings and Limitations
- The choice of transition matrix is an important design decision that encodes domain-specific inductive biases. Discretized Gaussian transitions work best for ordinal image data; absorbing-state transitions work best for text.
- D3PMs formally unify diffusion models and masked language models: absorbing-state diffusion with a [MASK] token is equivalent to a reweighted BERT-style training objective.
- The combined VLB + auxiliary loss ($L_\lambda$) achieves better density estimation (3.44 bpd) than continuous DDPMs (3.75 bpd) while producing competitive samples.
- Sample quality (best FID 7.34 for D3PM Gauss + logistic) still lags behind continuous-space DDPMs (FID 3.17) on CIFAR-10, though the gap narrows with structured transitions and the auxiliary loss.
- Scaling to very large numbers of categories $K$ requires special techniques (low-rank corruption or matrix exponentials) to manage the $O(K^2 T)$ memory cost of storing transition matrices.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Image generation | CIFAR-10 | 32x32, 256 categories | Quantized to 256 ordinal values per channel |
| Text generation | text8 | Character-level | 27 character vocabulary, sequences of length 256 |
| Text generation | LM1B | Word-level | Sentencepiece vocabulary of 8192 tokens, sequence length 128 |
Algorithms
- Noise schedules: Linear schedule for D3PM Gauss, cosine schedule for D3PM uniform, and a novel mutual information schedule for absorbing and nearest-neighbor models
- Reverse parameterization: $\mathbf{x}_0$-parameterization with posterior computation via Bayes’ rule
- Loss: $L_{\text{VLB}} + \lambda L_{\text{CE}}$ with $\lambda = 0.001$ for images and $\lambda = 0.01$ for text absorbing models
- Scaling: Low-rank corruption (absorbing, uniform) scales as $O(r^2 T)$; matrix exponentials for nearest-neighbor transitions
Models
- Image models: Modified U-Net architecture from Ho et al. (2020) adapted for categorical output via softmax over $K$ classes
- Text models: 12-layer T5-style transformer encoder with 70M parameters (12 heads, MLP dim 3072, QKV dim 768)
- Timesteps: $T = 1000$ for both images and text, though text models can be evaluated with fewer steps (e.g., 256 or 20)
Evaluation
| Metric | Dataset | Best D3PM | Continuous DDPM |
|---|---|---|---|
| FID | CIFAR-10 | 7.34 (Gauss + logistic) | 3.17 |
| NLL (bpd) | CIFAR-10 | 3.44 (Gauss + logistic) | 3.75 |
| BPC | text8 (char) | 1.45 (absorbing, $L_\lambda$) | N/A |
| Perplexity | LM1B | 76.9 (absorbing) | N/A |
Hardware
- All models trained for 1M steps with batch size 512 on TPUv2 or TPUv3
- Text models: 12-layer transformer encoder (T5 architecture), 70M parameters
- Image models: Modified U-Net architecture from Ho et al. (2020)
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| google-research/d3pm | Code | Apache-2.0 | Official JAX/Flax implementation for image and text experiments |
Paper Information
Citation: Austin, J., Johnson, D. D., Ho, J., Tarlow, D., & van den Berg, R. (2021). Structured Denoising Diffusion Models in Discrete State-Spaces. NeurIPS 2021. https://arxiv.org/abs/2107.03006
Publication: NeurIPS 2021
@inproceedings{austin2021structured,
title = {Structured Denoising Diffusion Models in Discrete State-Spaces},
author = {Austin, Jacob and Johnson, Daniel D. and Ho, Jonathan and Tarlow, Daniel and van den Berg, Rianne},
booktitle = {Advances in Neural Information Processing Systems},
volume = {34},
year = {2021}
}
Additional Resources: