What kind of paper is this?
This is a Method paper. It proposes consistency models, a new class of generative models designed for fast one-step (or few-step) generation. The models can be trained either by distilling pretrained diffusion models (consistency distillation) or as standalone generative models from scratch (consistency training). The paper provides theoretical analysis of both training modes and achieves FID 3.55 on CIFAR-10 for single-step non-adversarial generation (state of the art at the time of publication).
The Slow Sampling Problem in Diffusion
Diffusion models produce high-quality samples but require iterating through many denoising steps (often tens to hundreds), making generation slow compared to GANs or VAEs. Previous approaches to speed up sampling include faster ODE/SDE solvers (DDIM, DPM-Solver) and progressive distillation. These either still require multiple steps or depend on a complex multi-stage distillation pipeline. The goal is a model that can generate high-quality samples in a single forward pass while optionally allowing more steps for better quality.
Core Innovation: The Self-Consistency Property
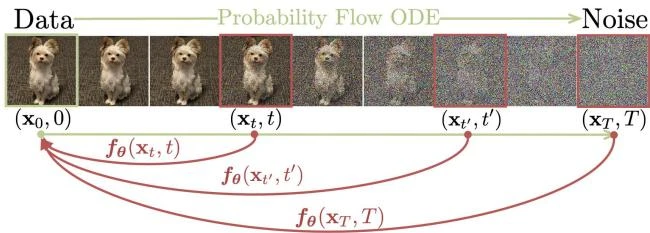
The key idea builds on the Probability Flow (PF) ODE from the score-based SDE framework. The PF ODE describes a deterministic trajectory that converts noise into data, governed by the learned score function. For the VE-SDE parameterization used by EDM (Karras et al., 2022), this takes the form:
$$\frac{d\mathbf{x}_t}{dt} = -t , s_\phi(\mathbf{x}_t, t)$$
where $s_\phi$ is a pretrained score model, a consistency function $f(\mathbf{x}_t, t)$ maps any point on an ODE trajectory to the trajectory’s origin $\mathbf{x}_\epsilon$. The defining property is self-consistency:
$$f(\mathbf{x}_t, t) = f(\mathbf{x}_{t’}, t’) \quad \text{for all } t, t’ \in [\epsilon, T]$$
for any points $\mathbf{x}_t$ and $\mathbf{x}_{t’}$ on the same PF ODE trajectory.
Parameterization. The model enforces the boundary condition $f(\mathbf{x}_\epsilon, \epsilon) = \mathbf{x}_\epsilon$ using skip connections:
$$f_\theta(\mathbf{x}, t) = c_{\text{skip}}(t) , \mathbf{x} + c_{\text{out}}(t) , F_\theta(\mathbf{x}, t)$$
where $c_{\text{skip}}(\epsilon) = 1$ and $c_{\text{out}}(\epsilon) = 0$, ensuring the boundary condition is satisfied by construction.
Consistency Distillation (CD). Given a pretrained diffusion model, CD trains a consistency model by enforcing self-consistency between adjacent timesteps:
$$\mathcal{L}_{\text{CD}}^N(\theta, \theta^-; \phi) = \mathbb{E}\left[\lambda(t_n) , d!\left(f_\theta(\mathbf{x}_{t_{n+1}}, t_{n+1}), , f_{\theta^-}(\hat{\mathbf{x}}_{t_n}^\phi, t_n)\right)\right]$$
where $\hat{\mathbf{x}}_{t_n}^\phi$ is obtained by running one step of the ODE solver using the pretrained score model, $\theta^-$ is an exponential moving average (EMA) of $\theta$, and $d(\cdot, \cdot)$ is a distance metric. The use of a target network $\theta^-$ (updated via EMA) parallels techniques from deep Q-learning and momentum contrastive learning.
Consistency Training (CT). CT eliminates the need for a pretrained diffusion model. It replaces the ODE solver step with a score estimate derived from the denoising score matching identity:
$$\nabla_{\mathbf{x}_t} \log p_t(\mathbf{x}_t) = \mathbb{E}\left[\frac{\mathbf{x} - \mathbf{x}_t}{t^2} ,\middle|, \mathbf{x}_t\right]$$
Because this identity lets us estimate the score from noisy data alone (without a pretrained model), we can compute the ODE update directly from training samples. This allows training directly on data pairs $(\mathbf{x}, \mathbf{x} + t\mathbf{z})$ where $\mathbf{z} \sim \mathcal{N}(0, I)$.
Theoretical guarantee. If CD achieves zero loss, the consistency model error is bounded by $O((\Delta t)^p)$ where $\Delta t$ is the maximum timestep gap and $p$ is the order of the ODE solver.
Experiments and Benchmarks
Datasets: CIFAR-10 (32x32), ImageNet 64x64, LSUN Bedroom 256x256, LSUN Cat 256x256.
Architecture: All models use the NCSN++/EDM architecture. CD distills from pretrained EDM models.
Key results for consistency distillation (CD):
| Dataset | Steps | FID |
|---|---|---|
| CIFAR-10 | 1 | 3.55 |
| CIFAR-10 | 2 | 2.93 |
| ImageNet 64x64 | 1 | 6.20 |
| ImageNet 64x64 | 2 | 4.70 |
| LSUN Bedroom 256 | 1 | 7.80 |
| LSUN Bedroom 256 | 2 | 5.22 |
| LSUN Cat 256 | 1 | 11.0 |
| LSUN Cat 256 | 2 | 8.84 |
CD outperforms progressive distillation (PD) across all datasets and sampling steps, with the exception of single-step generation on Bedroom 256x256 where CD with $\ell_2$ slightly underperforms PD with $\ell_2$.
Key results for consistency training (CT):
| Dataset | Steps | FID |
|---|---|---|
| CIFAR-10 | 1 | 8.70 |
| CIFAR-10 | 2 | 5.83 |
| ImageNet 64x64 | 1 | 13.0 |
| ImageNet 64x64 | 2 | 11.1 |
| LSUN Bedroom 256 | 1 | 16.0 |
| LSUN Cat 256 | 1 | 20.7 |
CT outperforms existing single-step non-adversarial models (VAEs, normalizing flows), e.g., improving over DC-VAE’s FID of 17.90 on CIFAR-10. Samples from CT share structural similarity with EDM samples from the same initial noise, suggesting CT does not suffer from mode collapse.
Zero-shot editing: Consistency models support colorization, super-resolution, inpainting, stroke-guided generation, interpolation, and denoising at test time without task-specific training, by modifying the multi-step sampling algorithm.
Findings and Limitations
- Consistency distillation achieves state-of-the-art FID for one-step generation (3.55 on CIFAR-10, 6.20 on ImageNet 64x64).
- Multi-step sampling provides a smooth quality-compute tradeoff: more steps yield better FID.
- CT produces competitive results without any pretrained diffusion model, making consistency models a standalone generative model family.
- The LPIPS distance metric $d(\cdot, \cdot)$ generally outperforms $\ell_1$ and $\ell_2$ for training consistency models.
- At higher resolutions (LSUN 256x256), the gap between CD/CT and full EDM sampling widens.
- CT currently underperforms CD, suggesting room for improvement in the standalone training paradigm.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Primary benchmark | CIFAR-10 | 32x32, 50K train | FID on 50K samples |
| Scaling benchmark | ImageNet 64x64 | 64x64, 1.28M | Unconditional generation |
| High-res benchmark | LSUN Bedroom, Cat | 256x256 | Unconditional generation |
Algorithms
- ODE solver for CD: Euler and Heun (2nd order) solvers on the empirical PF ODE
- EMA for target network: Decay rate $\mu$ scheduled as a function of training step
- Schedule functions: $N$ (number of discretization steps) and $\mu$ (EMA rate) increase over training following specific schedules (see Appendix C of the paper)
- Distance metric: LPIPS performs best; $\ell_2$ and $\ell_1$ also evaluated
Models
- Architecture: NCSN++/EDM architecture from Karras et al. (2022)
- CD teacher: Pretrained EDM models
- Parameterization: Skip-connection formulation with $c_{\text{skip}}(t)$ and $c_{\text{out}}(t)$ from EDM
Evaluation
| Metric | Dataset | CD 1-step | CT 1-step | EDM (full) |
|---|---|---|---|---|
| FID | CIFAR-10 | 3.55 | 8.70 | 2.04 |
| FID | ImageNet 64 | 6.20 | 13.0 | 2.44 |
| FID | LSUN Bedroom | 7.80 | 16.0 | 3.57 |
| FID | LSUN Cat | 11.0 | 20.7 | 6.69 |
Hardware
- Training details follow EDM conventions
- CD and CT use the same batch sizes and learning rate schedules as EDM training
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| openai/consistency_models | Code | MIT | Official implementation with pretrained checkpoints |
Paper Information
Citation: Song, Y., Dhariwal, P., Chen, M., & Sutskever, I. (2023). Consistency Models. ICML 2023. https://arxiv.org/abs/2303.01469
Publication: ICML 2023
@inproceedings{song2023consistency,
title = {Consistency Models},
author = {Song, Yang and Dhariwal, Prafulla and Chen, Mark and Sutskever, Ilya},
booktitle = {International Conference on Machine Learning},
year = {2023},
url = {https://arxiv.org/abs/2303.01469}
}
Additional Resources: