What kind of paper is this?
Method.
This paper is primarily a Methodological contribution. It proposes a novel probabilistic architecture, the Hierarchical Ideal Point Topic Model (HIPTM), designed to solve the specific limitations of existing political science models that typically rely on either voting data or text data in isolation. The paper validates this method by demonstrating its superior performance in predicting “Tea Party” membership compared to text-only baselines and its ability to provide interpretable “framing” analysis.
What is the motivation?
The primary motivation is to better understand political polarization, specifically the “Tea Party” phenomenon within the Republican party during the 112th Congress.
An ideal point is a scalar score representing a legislator’s ideological position, estimated from voting patterns. Standard “Ideal Point” models (like DW-NOMINATE) typically project legislators onto a single liberal-conservative dimension using only binary voting data. This is insufficient for capturing complex, multi-dimensional intra-party conflicts where legislators might agree on votes but differ on policy “framing” or specific sub-issues. Furthermore, existing multi-dimensional models often produce dimensions that are difficult for humans to interpret.
What is the novelty here?
The core novelty is the Hierarchical Ideal Point Topic Model (HIPTM). It distinguishes itself from prior work through three main technical innovations:
- Joint Modeling of Three Data Sources: It integrates roll call votes, the text of bills, and the floor speeches of legislators into a single probabilistic framework.
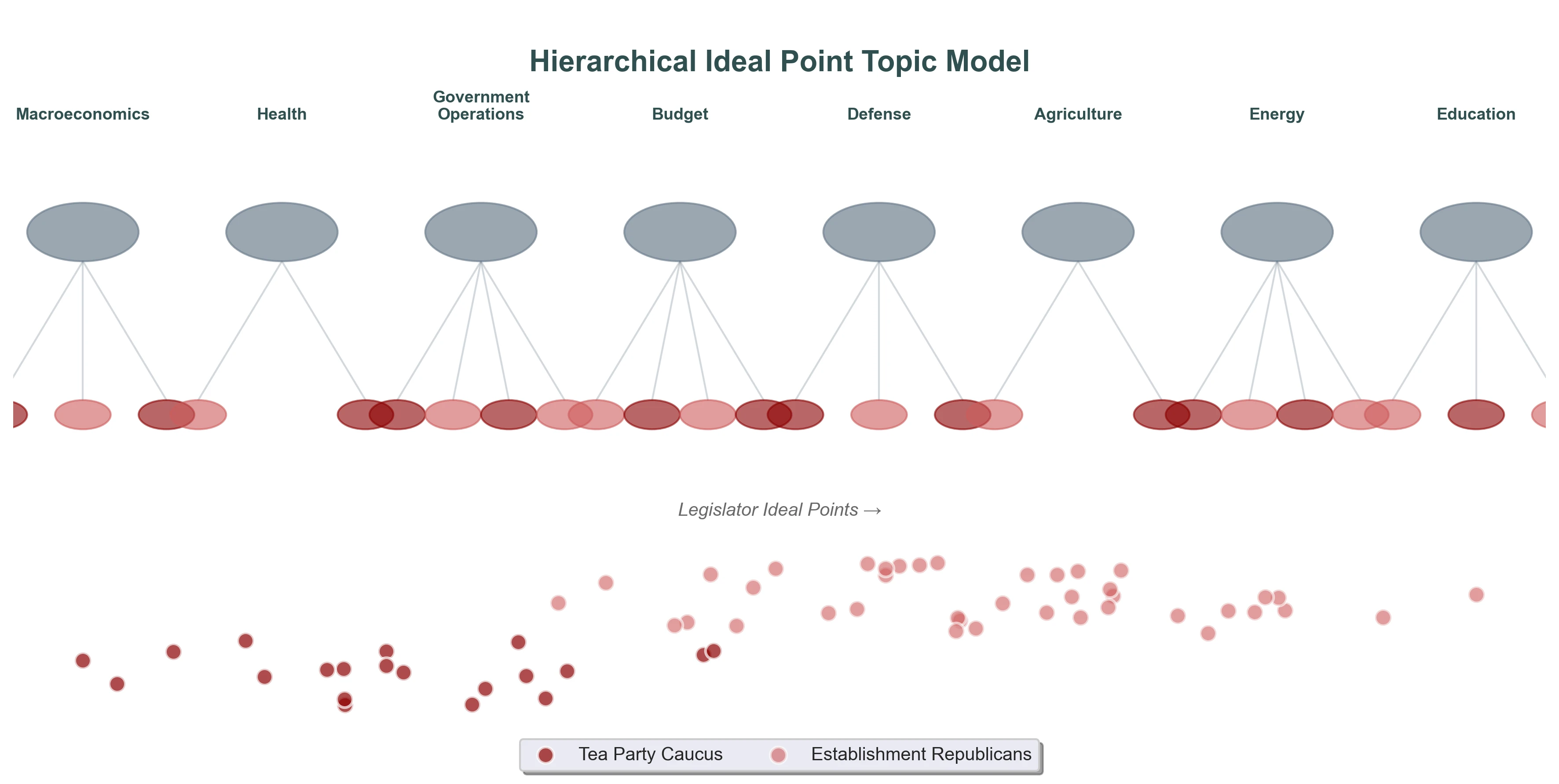
- Hierarchical Topic Structure: It models “frames” as a second level of the topic hierarchy. “Issues” (level 1) are fixed and non-polarized, while “Frames” (level 2) are discovered dynamically and carry polarity (ideal point weights). For example, Health Care is an issue; “government overreach” vs. “patient protection” are frames legislators use when debating it.
- Text-Based Ideal Point Prediction: HIPTM regresses ideal points on speech text, allowing it to predict the political alignment of legislators based solely on their writing or speeches without requiring voting records for inference.
What experiments were performed?
The authors validated the model using data from the 112th U.S. Congress (Republican legislators only).
- Prediction Task: Classifying legislators as members of the “Tea Party Caucus”.
- Baselines: The model was compared against Support Vector Machines (SVM) trained on:
- TF-IDF vectors (Text only)
- Normalized TF-IDF vectors (Text only)
- Binary Vote vectors (Vote only)
- Metric: Area Under the Receiver Operating Characteristic Curve (AUC-ROC) via 5-fold cross-validation.
- Qualitative Analysis: The authors examined the “span” of ideal points within specific topics (e.g., Macroeconomics, Health) to identify which issues were most polarized between Tea Party and Establishment Republicans.
What were the outcomes and conclusions drawn?
- Quantitative Performance: HIPTM features combined with voting data (HIPTM-VOTE) achieved the highest classification performance (AUC-ROC in the ~0.70-0.75 range, approximate, read from Figure 2). Vote-only features slightly trail HIPTM-VOTE, while text-only baselines (TF-IDF, normalized TF-IDF) fall considerably lower. The one-dimensional Tea Party ideal points correlate with DW-NOMINATE ($\rho = 0.91$). When voting data was withheld (simulating a candidate without a record), HIPTM’s text-based features outperformed standard text baselines TF-IDF and normalized TF-IDF (approximate, read from Figure 3).
- Political Insight: The model identified “Government Operations,” “Macroeconomics,” and “Transportation” as the three most polarized topics between Tea Party and establishment Republicans.
- Framing Analysis: The hierarchical topic structure reveals how legislators frame issues differently. For Macroeconomics, frame M3 (most Tea Party-oriented) focuses on criticizing government overspending, while frame M1 (least Tea Party-oriented) focuses on the downsides of a government shutdown. For Health, frame H3 captures Tea Party framing of the Affordable Care Act as an unconstitutional government takeover, while frame H1 frames opposition in terms of implementation costs and health care exchanges.
- Framing vs. Voting Taxonomy: The authors construct a 2x2 taxonomy of disagreement across issues, crossing whether ideal points are polarized with whether issue frames are polarized. Issues like Civil Rights fall in the “neither polarized” quadrant, where cooperation is expected. Banking/Finance and Transportation fall in the “ideal points polarized, frames not” quadrant, where Republicans frame the issue similarly but have underlying policy disagreements. Issues like Health and Public Lands fall in the “frames polarized, ideal points not” quadrant: Republicans voted similarly but framed the issue very differently. Issues like Macroeconomics and Government Operations fall in the “both polarized” quadrant, posing the greatest challenge for Republican leadership.
- Sub-group Identification: The model identifies legislators whose language marks them as ideologically aligned with the Tea Party even without formal caucus membership. For example, Jeff Flake (R-AZ) received the second-highest ideal point, disagreeing with Freedom Works on only one of 60 key votes, despite not being a Tea Party Caucus member. Justin Amash (R-MI), founder and chairman of the Liberty Caucus, agreed with Freedom Works on every key vote since 2011. Conversely, some self-identified Tea Partiers like Rodney Alexander (R-LA) only agreed with Freedom Works 48% of the time. Alexander and Ander Crenshaw (R-FL, 50% agreement) are categorized as “Green Tea” by Gervais and Morris (2014): Republican legislators who associate with the Tea Party on their own initiative but lack support from Tea Party organizations.
Limitations
- HIPTM does not formally distinguish frames from other kinds of subtopics. For example, the model discovered a strongly Tea Party-oriented frame under “Labor, Employment and Immigration” that reflected a Boeing labor dispute specific to South Carolina legislators, capturing geographic rather than ideological framing.
- The model is validated only on Republican legislators in the 112th Congress. Generalization to other parties, chambers, or time periods is untested.
Reproducibility Details
Data
The study focuses on the 112th U.S. Congress (Jan 2011 - Jan 2013).
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Subjects | Republican Legislators | 240 Reps | 60 are Tea Party Caucus members. |
| Votes | Roll Call Votes | 13,856 votes | Agreement/disagreement with Freedom Works on 60 key votes (40 in 2011, 20 in 2012). |
| Text | Floor Speeches | 5,349 word types | Sourced from GovTrack. Vocabulary size after preprocessing. |
| Priors | Congressional Bills Project | 19 Topics | Used to set informed priors $\phi^*_k$ for top-level issues. |
Algorithms
The model uses a Stochastic EM approach for inference.
- Generative Process:
- Speeches: Modeled as a mixture of $K$ Hierarchical Dirichlet Processes (HDPs). A legislator chooses an issue $z$, then a frame $t$ from a Dirichlet Process, then a word $w$.
- Bills: Modeled using Latent Dirichlet Allocation (LDA). Each bill is a mixture over $K$ issues.
- Votes: Modeled via a probabilistic ideal point function (logistic/inverse-logit). The probability of a “Yes” vote depends on the bill’s polarity $x_b$, popularity $y_b$, and the legislator’s issue-specific ideal point $u_{a,k}$.
- Optimization Steps:
- Sampling: Issue assignments $z$ and frame assignments $t$ are sampled for tokens in speeches and bills.
- Regression: Frame-specific regression weights $\eta_{k,j}$ are optimized using L-BFGS.
- Ideal Points: Legislator ideal points $u_{a,k}$ and bill parameters ($x_b, y_b$) are updated using Gradient Ascent.
Models
- Ideal Point Definition: A legislator’s ideal point on issue $k$ ($u_{a,k}$) is defined as a linear combination of the ideal points of the frames they use ($\eta_{k,j}$), weighted by their usage frequency ($\hat{\psi}_{a,k,j}$).
- Topic Hierarchy:
- Level 1 (Issues): Fixed at $K=19$ (based on Policy Agendas Project major headings). These nodes use informed Dirichlet priors.
- Level 2 (Frames): Unbounded number of frames per issue, discovered non-parametrically via Dirichlet Process.
- Prediction Features: The model runs for 1,000 iterations total with a 500-iteration burn-in. After burn-in, the sampled state is kept every 50 iterations, and feature values are averaged over the 10 stored models.
Evaluation
- Primary Metric: AUC-ROC (Area Under the Receiver Operating Characteristic Curve).
- Classifier: $\text{SVM}^{\text{light}}$ (Joachims, 1999).
- Cross-Validation: 5-fold stratified sampling.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| GovTrack Congressional Speeches | Dataset | Public | Source of floor speech text |
| Congressional Bills Project | Dataset | Public | Bill text with Policy Agendas Project topic labels |
| Freedom Works Key Votes | Dataset | Public | 60 key votes used to define Tea Party alignment (freedomworks.org is no longer available) |
No official code release accompanies this paper. The inference algorithm (Stochastic EM with Gibbs sampling, L-BFGS, and gradient ascent) is described in detail in Section 4 of the paper, but a full reimplementation would be required.
Paper Information
Citation: Nguyen, V., Boyd-Graber, J., Resnik, P., & Miler, K. (2015). Tea Party in the House: A Hierarchical Ideal Point Topic Model and Its Application to Republican Legislators in the 112th Congress. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, 1438-1448. https://doi.org/10.3115/v1/P15-1139
Publication: ACL 2015
@inproceedings{nguyenTeaPartyHouse2015,
title = {Tea {{Party}} in the {{House}}: {{A Hierarchical Ideal Point Topic Model}} and {{Its Application}} to {{Republican Legislators}} in the 112th {{Congress}}},
shorttitle = {Tea {{Party}} in the {{House}}},
booktitle = {Proceedings of the 53rd {{Annual Meeting}} of the {{Association}} for {{Computational Linguistics}} and the 7th {{International Joint Conference}} on {{Natural Language Processing}} ({{Volume}} 1: {{Long Papers}})},
author = {Nguyen, Viet-An and {Boyd-Graber}, Jordan and Resnik, Philip and Miler, Kristina},
year = {2015},
pages = {1438--1448},
publisher = {Association for Computational Linguistics},
address = {Beijing, China},
doi = {10.3115/v1/P15-1139},
urldate = {2023-11-02},
abstract = {We introduce the Hierarchical Ideal Point Topic Model, which provides a rich picture of policy issues, framing, and voting behavior using a joint model of votes, bill text, and the language that legislators use when debating bills. We use this model to look at the relationship between Tea Party Republicans and ``establishment'' Republicans in the U.S. House of Representatives during the 112th Congress.},
langid = {english}
}
Additional Resources:
- ACL Anthology: Tea Party in the House
- Gervais, B. T., & Morris, I. L. (2012). Reading the tea leaves: Understanding Tea Party Caucus membership in the US House of Representatives. PS: Political Science & Politics, 45(2), 245-250.
- Gervais, B. T., & Morris, I. L. (2014). Black Tea, Green Tea, White Tea, and Coffee: Understanding the variation in attachment to the Tea Party among members of Congress. In Annual Meeting of the American Political Science Association. (Source of the “Green Tea” Republican taxonomy cited in the paper)