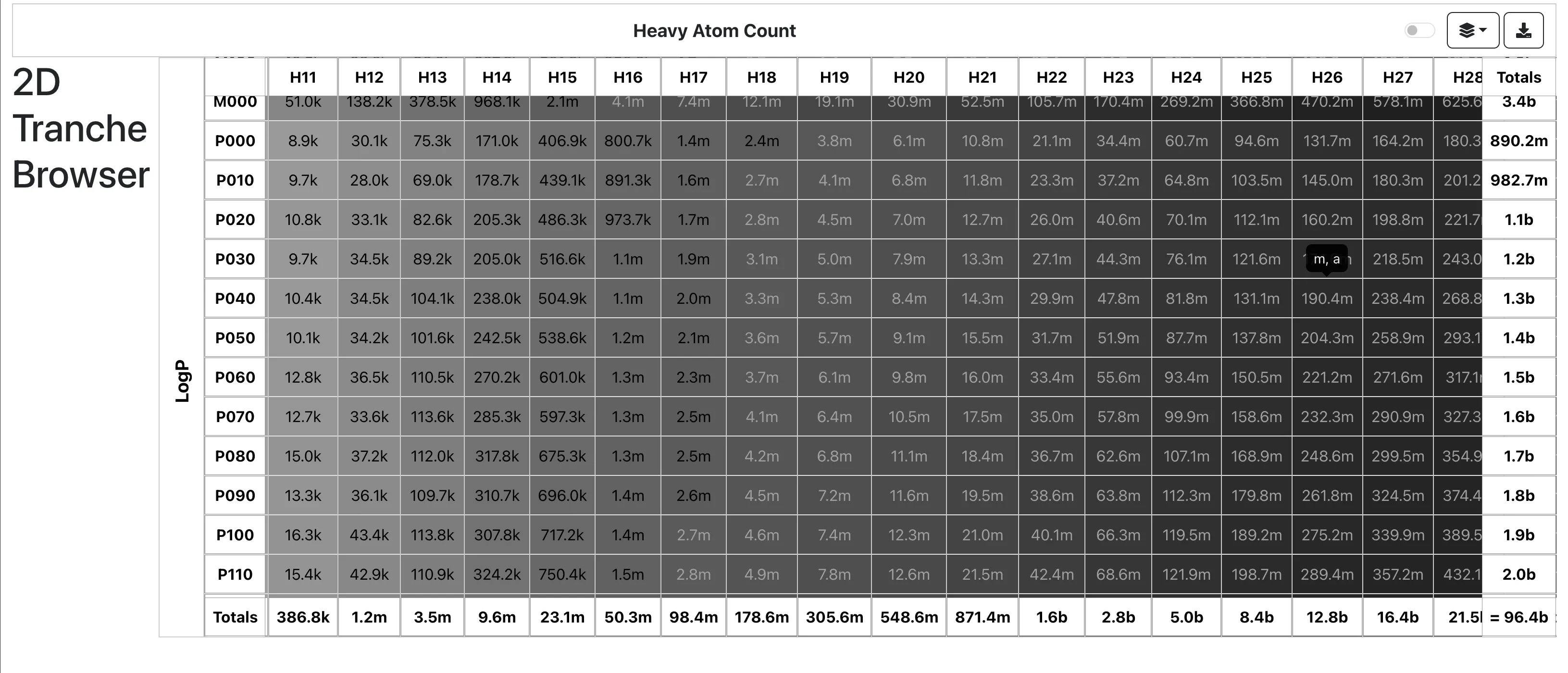
ZINC-22: Multi-Billion Molecule Database
A dataset card for ZINC-22, the largest freely available database of commercially available compounds for virtual …
A dataset card for ZINC-22, the largest freely available database of commercially available compounds for virtual …
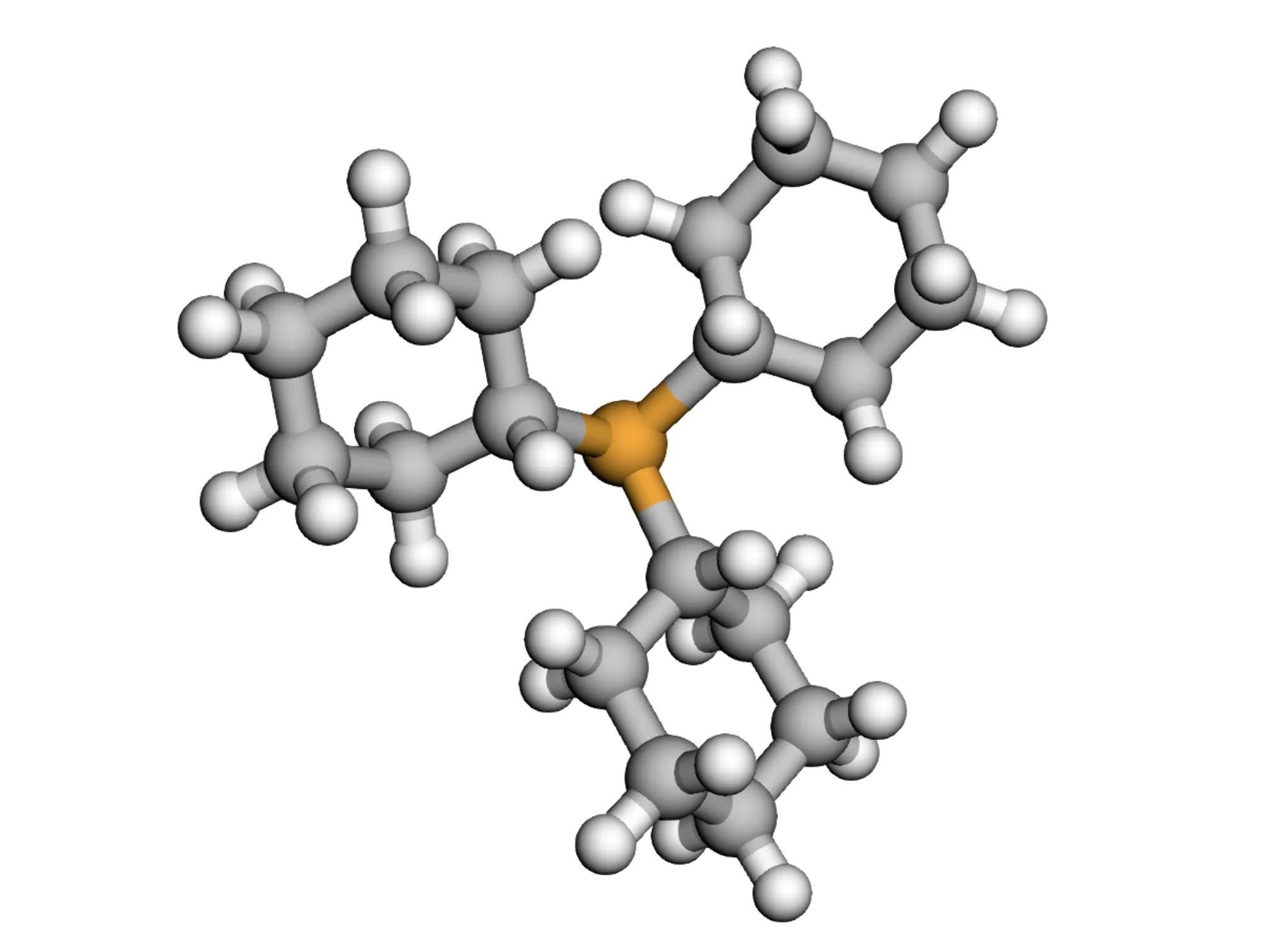
MARCEL dataset provides 722K+ conformers across 76K+ molecules for drug discovery, catalysis, and molecular …
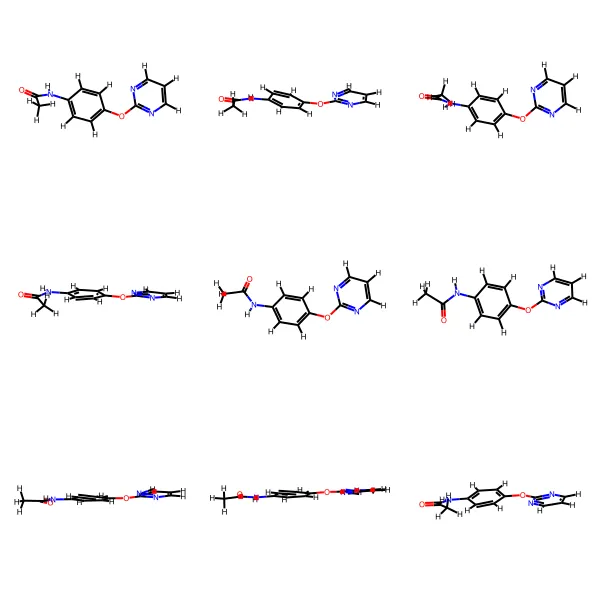
A dataset card for the GEOM dataset, a collection of energy-annotated molecular conformations for property prediction …
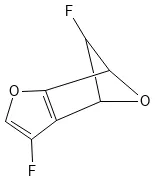
A dataset card for the Generated Database 11 (GDB-11), a database of 26.4 million small organic molecules for virtual …
A dataset card for the Generated Database 13 (GDB-13), a database of nearly 1 billion small organic molecules for …
Dataset card for GDB-17, containing 166 billion small organic molecules representing the largest enumerated chemical …